 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Projection for Deep Neural Networks
Paper and Code
Oct 26, 2017
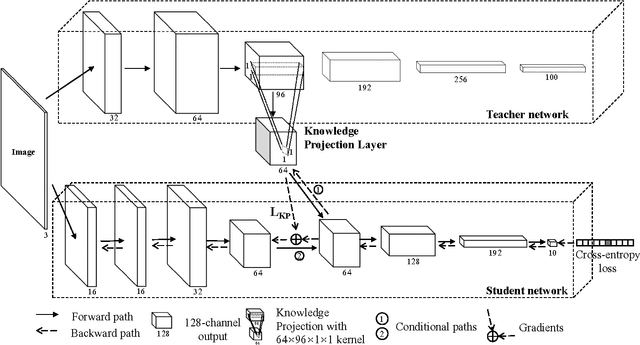


While deeper and wider neural networks are actively pushing the performance limits of various computer vision and machine learning tasks, they often require large sets of labeled data for effective training and suffer from extremely high computational complexity. In this paper, we will develop a new framework for training deep neural networks on datasets with limited labeled samples using cross-network knowledge projection which is able to improve the network performance while reducing the overall computational complexity significantly. Specifically, a large pre-trained teacher network is used to observe samples from the training data. A projection matrix is learned to project this teacher-level knowledge and its visual representations from an intermediate layer of the teacher network to an intermediate layer of a thinner and faster student network to guide and regulate its training process. Both the intermediate layers from the teacher network and the injection layers from the student network are adaptively selected during training by evaluating a joint loss function in an iterative manner. This knowledge projection framework allows us to use crucial knowledge learned by large networks to guide the training of thinner student networks, avoiding over-fitting, achieving better network performance, and significantly reducing the complexity. Extensive experimental results on benchmark datasets have demonstrated that our proposed knowledge projection approach outperforms existing methods, improving accuracy by up to 4% while reducing network complexity by 4 to 10 times, which is very attractive for practical applications of deep neural networks.