 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Consistency Benchmark for GenAI Video
May 16, 2025Video generation driven by artificial intelligence has advanced significantly, enabling the creation of dynamic and realistic content. However, maintaining character consistency across video sequences remains a major challenge, with current models struggling to ensure coherence in appearance and attributes. This paper introduces the Face Consistency Benchmark (FCB), a framework for evaluating and comparing the consistency of characters in AI-generated videos. By providing standardized metrics, the benchmark highlights gaps in existing solutions and promotes the development of more reliable approaches. This work represents a crucial step toward improving character consistency in AI video generation technologies.
The secret of immersion: actor driven camera movement generation for auto-cinematography
Mar 29, 2023



Immersion plays a vital role when designing cinematic creations, yet the difficulty in immersive shooting prevents designers to create satisfactory outputs. In this work, we analyze the specific components that contribute to cinematographic immersion considering spatial, emotional, and aesthetic level, while these components are then combined into a high-level evaluation mechanism. Guided by such a immersion mechanism, we propose a GAN-based camera control system that is able to generate actor-driven camera movements in the 3D virtual environment to obtain immersive film sequences. The proposed encoder-decoder architecture in the generation flow transfers character motion into camera trajectory conditioned on an emotion factor. This ensures spatial and emotional immersion by performing actor-camera synchronization physically and psychologically. The emotional immersion is further strengthened by incorporating regularization that controls camera shakiness for expressing different mental statuses. To achieve aesthetic immersion, we make effort to improve aesthetic frame compositions by modifying the synthesized camera trajectory. Based on a self-supervised adjustor, the adjusted camera placements can project the character to the appropriate on-frame locations following aesthetic rules. The experimental results indicate that our proposed camera control system can efficiently offer immersive cinematic videos, both quantitatively and qualitatively, based on a fine-grained immersive shooting. Live examples are shown in the supplementary video.
Robust and Low-Rank Representation for Fast Face Identification with Occlusions
Nov 11, 2017
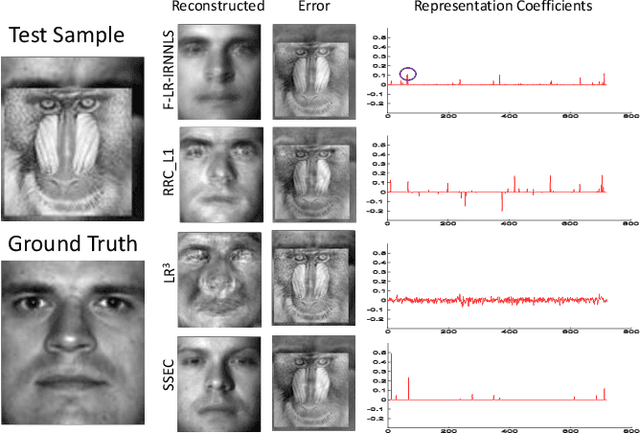


In this paper we propose an iterative method to address the face identification problem with block occlusions. Our approach utilizes a robust representation based on two characteristics in order to model contiguous errors (e.g., block occlusion) effectively. The first fits to the errors a distribution described by a tailored loss function. The second describes the error image as having a specific structure (resulting in low-rank in comparison to image size). We will show that this joint characterization is effective for describing errors with spatial continuity. Our approach is computationally efficient due to the utilization of the Alternating Direction Method of Multipliers (ADMM). A special case of our fast iterative algorithm leads to the robust representation method which is normally used to handle non-contiguous errors (e.g., pixel corruption). Extensive results on representative face databases (in constrained and unconstrained environments) document the effectiveness of our method over existing robust representation methods with respect to both identification rates and computational time. Code is available at Github, where you can find implementations of the F-LR-IRNNLS and F-IRNNLS (fast version of the RRC) : https://github.com/miliadis/FIRC
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Jul 19, 2016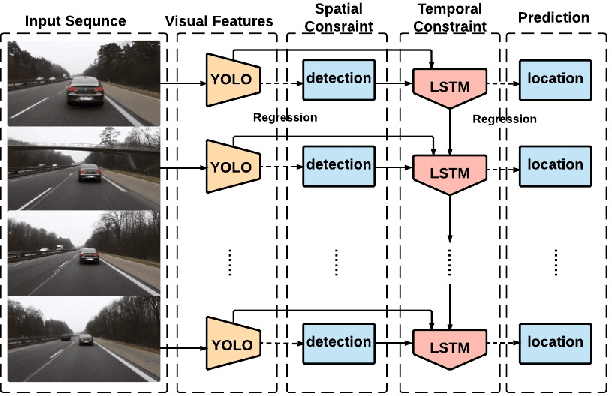



In this paper, we develop a new approach of spatially supervised recurrent convolutional neural networks for visual object tracking. Our recurrent convolutional network exploits the history of locations as well as the distinctive visual features learned by the deep neural networks. Inspired by recent bounding box regression methods for object detection, we study the regression capability of Long Short-Term Memory (LSTM) in the temporal domain, and propose to concatenate high-level visual features produced by convolutional networks with region information. In contrast to existing deep learning based trackers that use binary classification for region candidates, we use regression for direct prediction of the tracking locations both at the convolutional layer and at the recurrent unit. Our extensive experimental results and performance comparison with state-of-the-art tracking methods on challenging benchmark video tracking datasets shows that our tracker is more accurate and robust while maintaining low computational cost. For most test video sequences, our method achieves the best tracking performance, often outperforms the second best by a large margin.