 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Fully-Connected Networks for Video Compressive Sensing
Dec 16, 2017
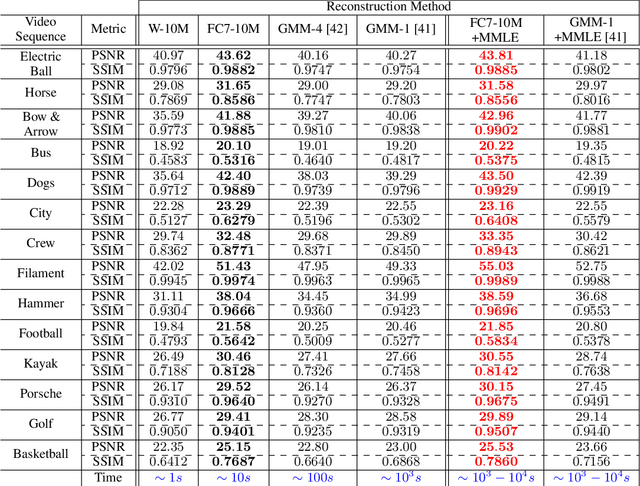
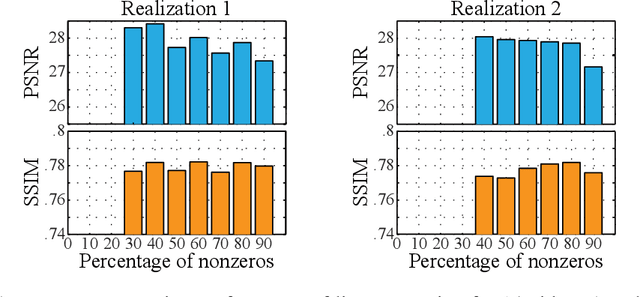
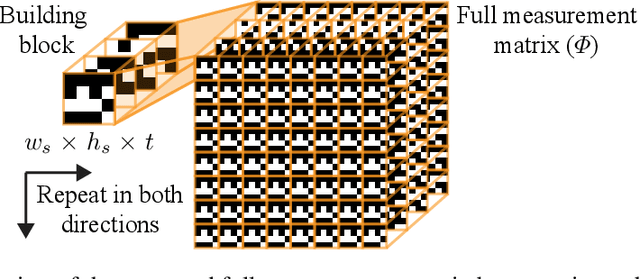
In this work we present a deep learning framework for video compressive sensing. The proposed formulation enables recovery of video frames in a few seconds at significantly improved reconstruction quality compared to previous approaches. Our investigation starts by learning a linear mapping between video sequences and corresponding measured frames which turns out to provide promising results. We then extend the linear formulation to deep fully-connected networks and explore the performance gains using deeper architectures. Our analysis is always driven by the applicability of the proposed framework on existing compressive video architectures. Extensive simulations on several video sequences document the superiority of our approach both quantitatively and qualitatively. Finally, our analysis offers insights into understanding how dataset sizes and number of layers affect reconstruction performance while raising a few points for future investigation. Code is available at Github: https://github.com/miliadis/DeepVideoCS
Robust and Low-Rank Representation for Fast Face Identification with Occlusions
Nov 11, 2017
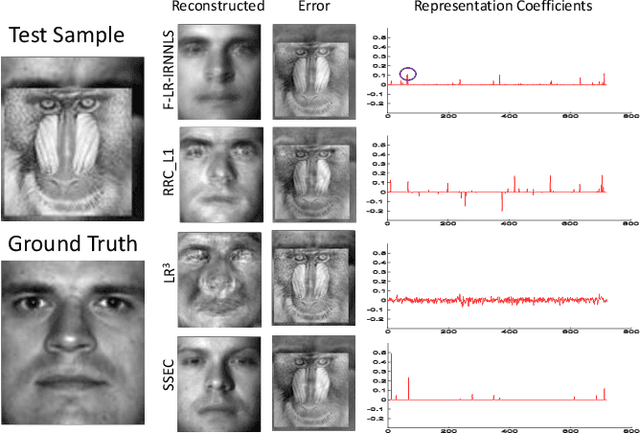


In this paper we propose an iterative method to address the face identification problem with block occlusions. Our approach utilizes a robust representation based on two characteristics in order to model contiguous errors (e.g., block occlusion) effectively. The first fits to the errors a distribution described by a tailored loss function. The second describes the error image as having a specific structure (resulting in low-rank in comparison to image size). We will show that this joint characterization is effective for describing errors with spatial continuity. Our approach is computationally efficient due to the utilization of the Alternating Direction Method of Multipliers (ADMM). A special case of our fast iterative algorithm leads to the robust representation method which is normally used to handle non-contiguous errors (e.g., pixel corruption). Extensive results on representative face databases (in constrained and unconstrained environments) document the effectiveness of our method over existing robust representation methods with respect to both identification rates and computational time. Code is available at Github, where you can find implementations of the F-LR-IRNNLS and F-IRNNLS (fast version of the RRC) : https://github.com/miliadis/FIRC
DeepBinaryMask: Learning a Binary Mask for Video Compressive Sensing
Jul 18, 2016
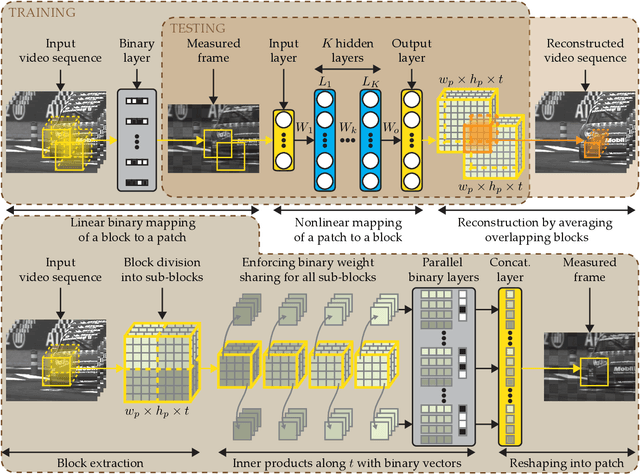
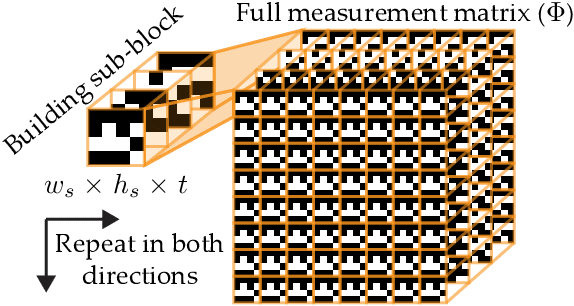
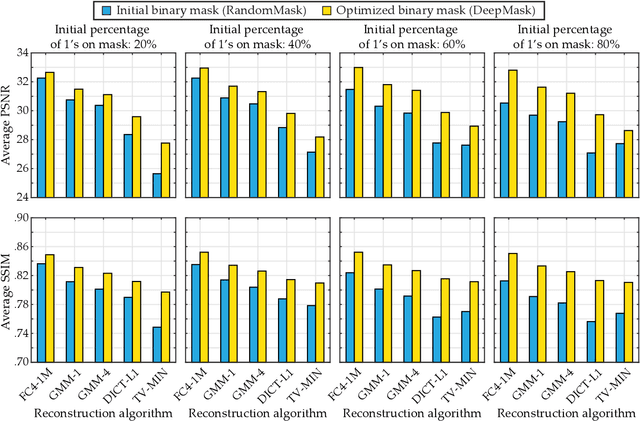
In this paper, we propose a novel encoder-decoder neural network model referred to as DeepBinaryMask for video compressive sensing. In video compressive sensing one frame is acquired using a set of coded masks (sensing matrix) from which a number of video frames is reconstructed, equal to the number of coded masks. The proposed framework is an end-to-end model where the sensing matrix is trained along with the video reconstruction. The encoder learns the binary elements of the sensing matrix and the decoder is trained to recover the unknown video sequence. The reconstruction performance is found to improve when using the trained sensing mask from the network as compared to other mask designs such as random, across a wide variety of compressive sensing reconstruction algorithms. Finally, our analysis and discussion offers insights into understanding the characteristics of the trained mask designs that lead to the improved reconstruction quality.