 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePindrop it! Audio and Visual Deepfake Countermeasures for Robust Detection and Fine Grained-Localization
Aug 11, 2025The field of visual and audio generation is burgeoning with new state-of-the-art methods. This rapid proliferation of new techniques underscores the need for robust solutions for detecting synthetic content in videos. In particular, when fine-grained alterations via localized manipulations are performed in visual, audio, or both domains, these subtle modifications add challenges to the detection algorithms. This paper presents solutions for the problems of deepfake video classification and localization. The methods were submitted to the ACM 1M Deepfakes Detection Challenge, achieving the best performance in the temporal localization task and a top four ranking in the classification task for the TestA split of the evaluation dataset.
Explaining Face Presentation Attack Detection Using Natural Language
Nov 08, 2021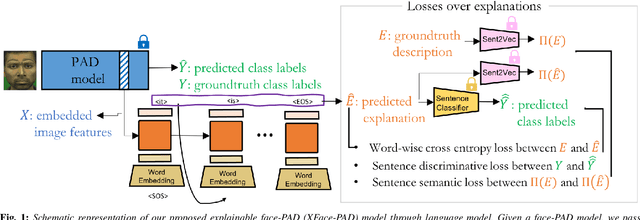
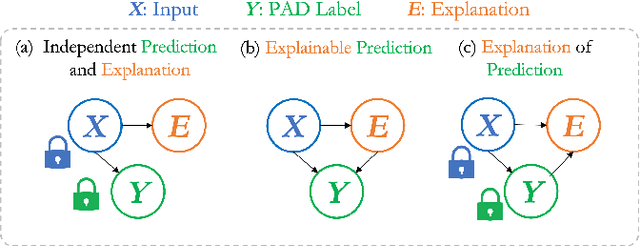
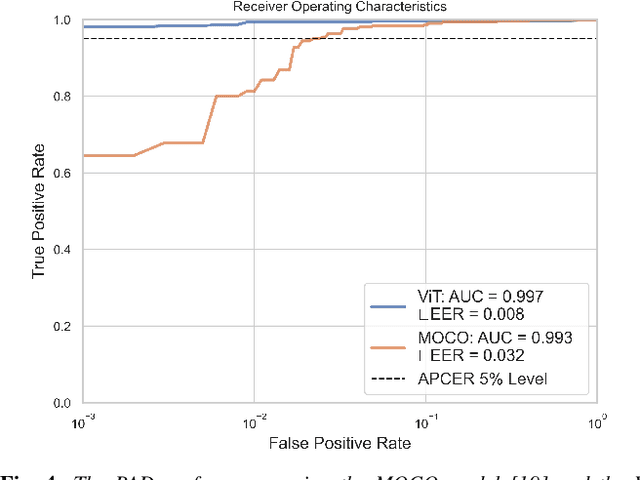
A large number of deep neural network based techniques have been developed to address the challenging problem of face presentation attack detection (PAD). Whereas such techniques' focus has been on improving PAD performance in terms of classification accuracy and robustness against unseen attacks and environmental conditions, there exists little attention on the explainability of PAD predictions. In this paper, we tackle the problem of explaining PAD predictions through natural language. Our approach passes feature representations of a deep layer of the PAD model to a language model to generate text describing the reasoning behind the PAD prediction. Due to the limited amount of annotated data in our study, we apply a light-weight LSTM network as our natural language generation model. We investigate how the quality of the generated explanations is affected by different loss functions, including the commonly used word-wise cross entropy loss, a sentence discriminative loss, and a sentence semantic loss. We perform our experiments using face images from a dataset consisting of 1,105 bona-fide and 924 presentation attack samples. Our quantitative and qualitative results show the effectiveness of our model for generating proper PAD explanations through text as well as the power of the sentence-wise losses. To the best of our knowledge, this is the first introduction of a joint biometrics-NLP task. Our dataset can be obtained through our GitHub page.
Detection and Continual Learning of Novel Face Presentation Attacks
Aug 27, 2021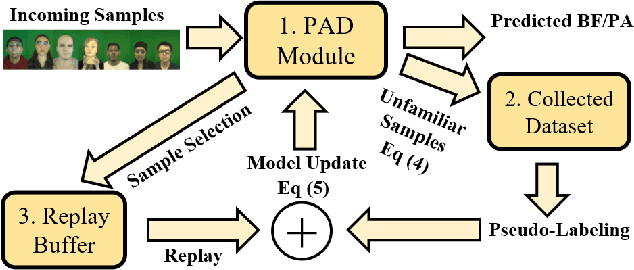


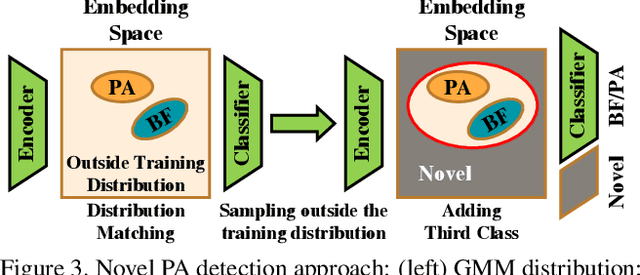
Advances in deep learning, combined with availability of large datasets, have led to impressive improvements in face presentation attack detection research. However, state-of-the-art face antispoofing systems are still vulnerable to novel types of attacks that are never seen during training. Moreover, even if such attacks are correctly detected, these systems lack the ability to adapt to newly encountered attacks. The post-training ability of continually detecting new types of attacks and self-adaptation to identify these attack types, after the initial detection phase, is highly appealing. In this paper, we enable a deep neural network to detect anomalies in the observed input data points as potential new types of attacks by suppressing the confidence-level of the network outside the training samples' distribution. We then use experience replay to update the model to incorporate knowledge about new types of attacks without forgetting the past learned attack types. Experimental results are provided to demonstrate the effectiveness of the proposed method on two benchmark datasets as well as a newly introduced dataset which exhibits a large variety of attack types.
Multi-Modal Fingerprint Presentation Attack Detection: Evaluation On A New Dataset
Jun 16, 2020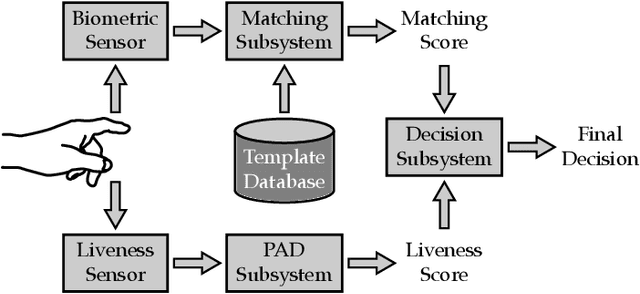

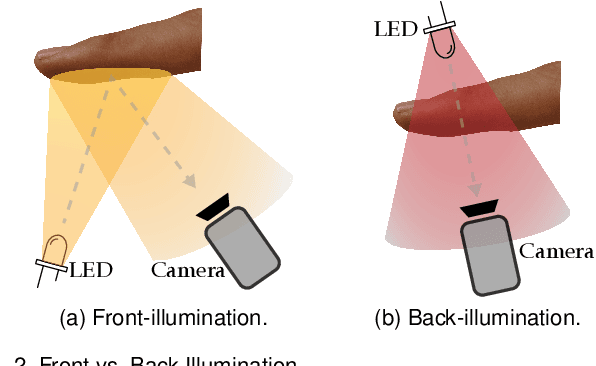
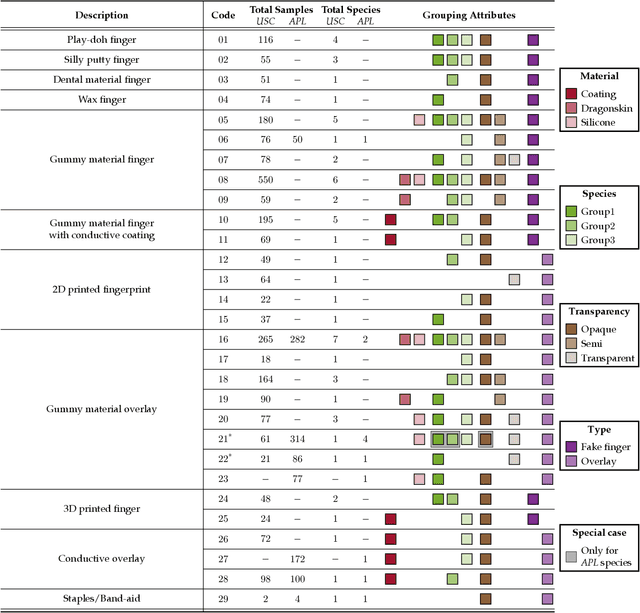
Fingerprint presentation attack detection is becoming an increasingly challenging problem due to the continuous advancement of attack preparation techniques, which generate realistic-looking fake fingerprint presentations. In this work, rather than relying on legacy fingerprint images, which are widely used in the community, we study the usefulness of multiple recently introduced sensing modalities. Our study covers front-illumination imaging using short-wave-infrared, near-infrared, and laser illumination; and back-illumination imaging using near-infrared light. Toward studying the effectiveness of each of these unconventional sensing modalities and their fusion for liveness detection, we conducted a comprehensive analysis using a fully convolutional deep neural network framework. Our evaluation compares different combination of the new sensing modalities to legacy data from one of our collections as well as the public LivDet2015 dataset, showing the superiority of the new sensing modalities in most cases. It also covers the cases of known and unknown attacks and the cases of intra-dataset and inter-dataset evaluations. Our results indicate that the power of our approach stems from the nature of the captured data rather than the employed classification framework, which justifies the extra cost for hardware-based (or hybrid) solutions. We plan to publicly release one of our dataset collections.
Multispectral Biometrics System Framework: Application to Presentation Attack Detection
Jun 12, 2020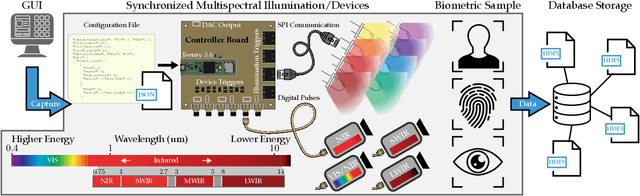
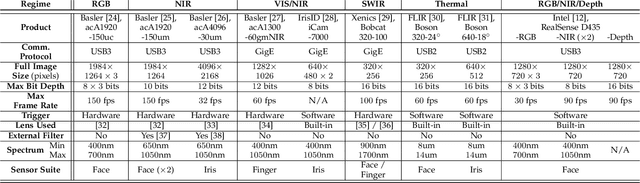
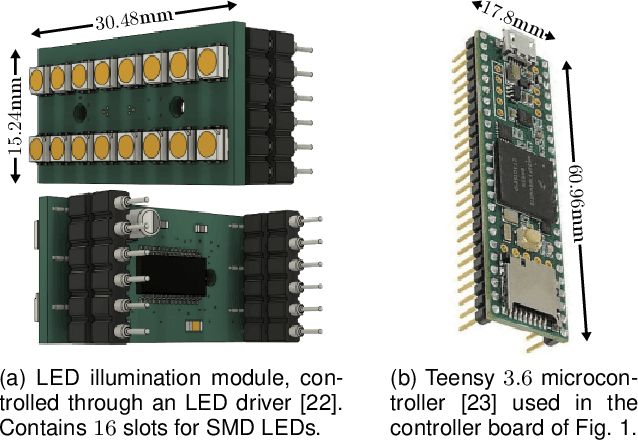
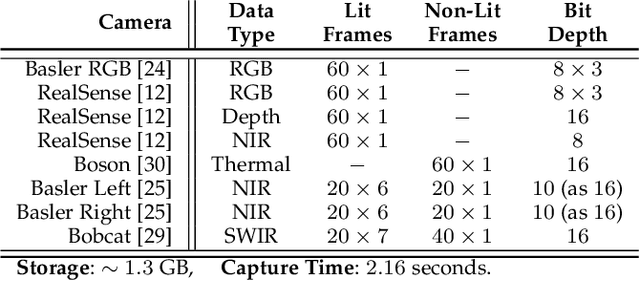
In this work, we present a general framework for building a biometrics system capable of capturing multispectral data from a series of sensors synchronized with active illumination sources. The framework unifies the system design for different biometric modalities and its realization on face, finger and iris data is described in detail. To the best of our knowledge, the presented design is the first to employ such a diverse set of electromagnetic spectrum bands, ranging from visible to long-wave-infrared wavelengths, and is capable of acquiring large volumes of data in seconds. Having performed a series of data collections, we run a comprehensive analysis on the captured data using a deep-learning classifier for presentation attack detection. Our study follows a data-centric approach attempting to highlight the strengths and weaknesses of each spectral band at distinguishing live from fake samples.
Deep Fully-Connected Networks for Video Compressive Sensing
Dec 16, 2017
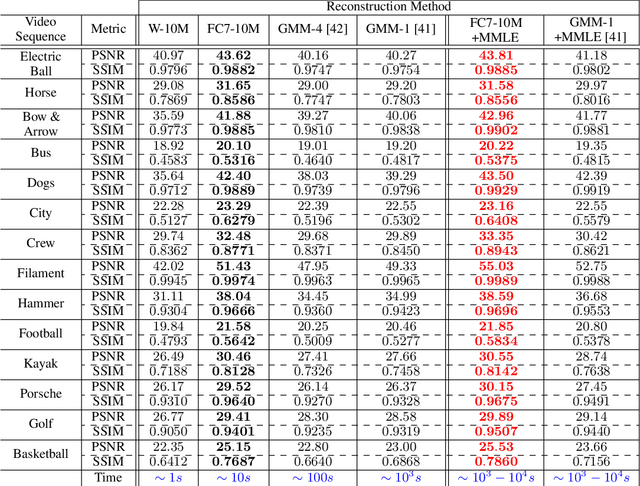
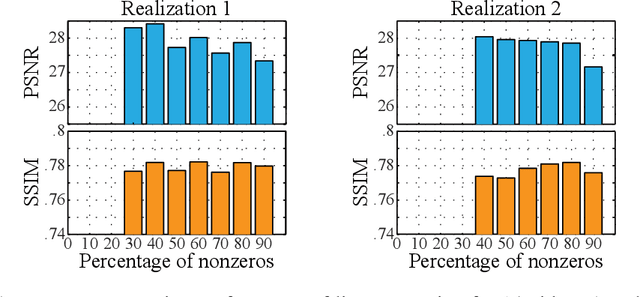
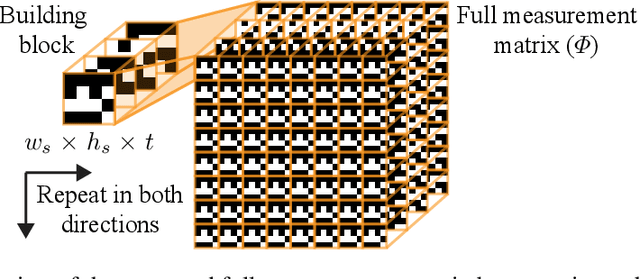
In this work we present a deep learning framework for video compressive sensing. The proposed formulation enables recovery of video frames in a few seconds at significantly improved reconstruction quality compared to previous approaches. Our investigation starts by learning a linear mapping between video sequences and corresponding measured frames which turns out to provide promising results. We then extend the linear formulation to deep fully-connected networks and explore the performance gains using deeper architectures. Our analysis is always driven by the applicability of the proposed framework on existing compressive video architectures. Extensive simulations on several video sequences document the superiority of our approach both quantitatively and qualitatively. Finally, our analysis offers insights into understanding how dataset sizes and number of layers affect reconstruction performance while raising a few points for future investigation. Code is available at Github: https://github.com/miliadis/DeepVideoCS
Compressive Holographic Video
Oct 27, 2016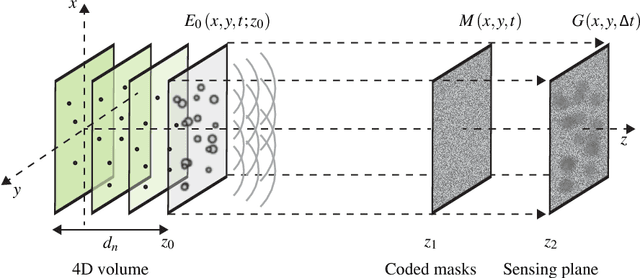
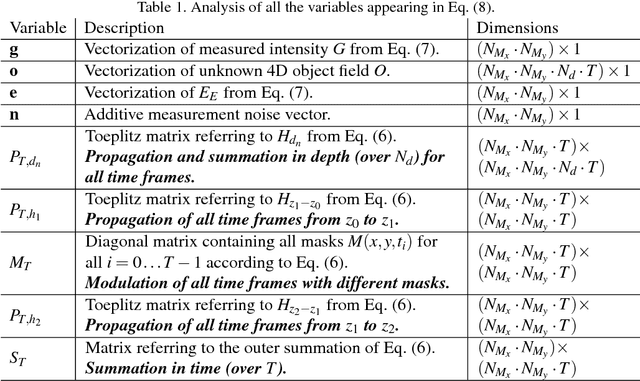
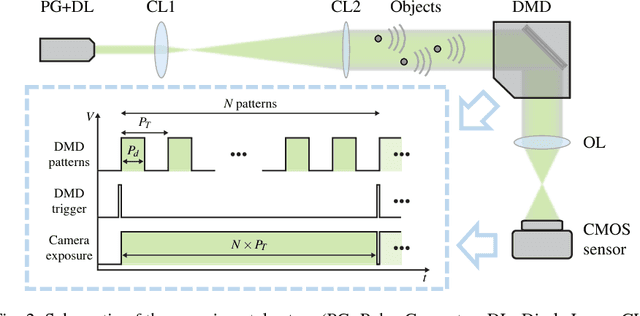
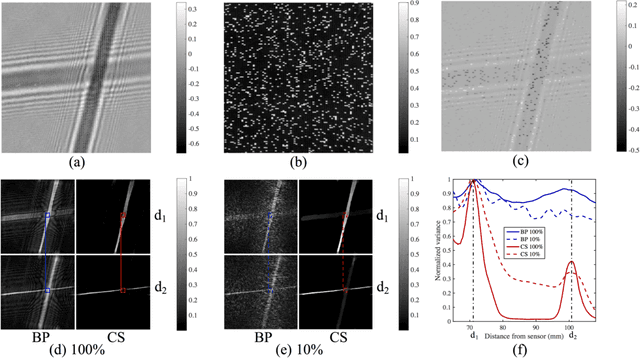
Compressed sensing has been discussed separately in spatial and temporal domains. Compressive holography has been introduced as a method that allows 3D tomographic reconstruction at different depths from a single 2D image. Coded exposure is a temporal compressed sensing method for high speed video acquisition. In this work, we combine compressive holography and coded exposure techniques and extend the discussion to 4D reconstruction in space and time from one coded captured image. In our prototype, digital in-line holography was used for imaging macroscopic, fast moving objects. The pixel-wise temporal modulation was implemented by a digital micromirror device. In this paper we demonstrate $10\times$ temporal super resolution with multiple depths recovery from a single image. Two examples are presented for the purpose of recording subtle vibrations and tracking small particles within 5 ms.
DeepBinaryMask: Learning a Binary Mask for Video Compressive Sensing
Jul 18, 2016
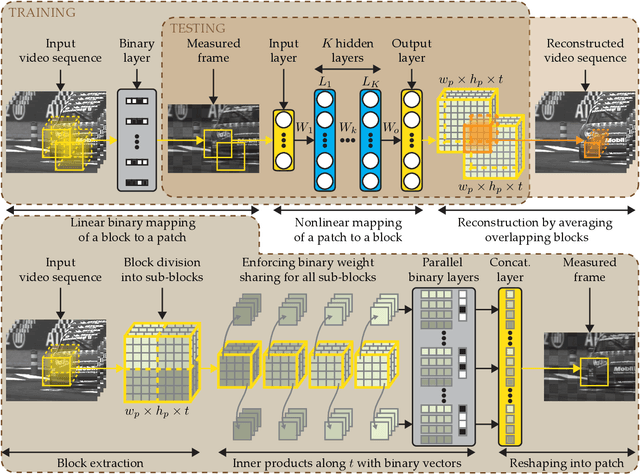
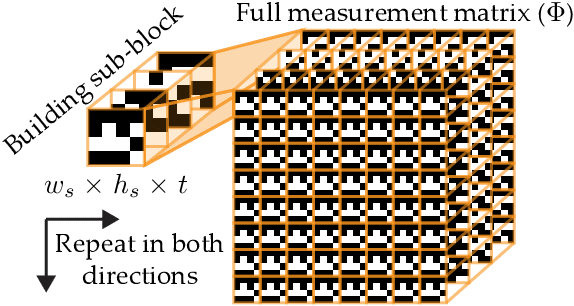
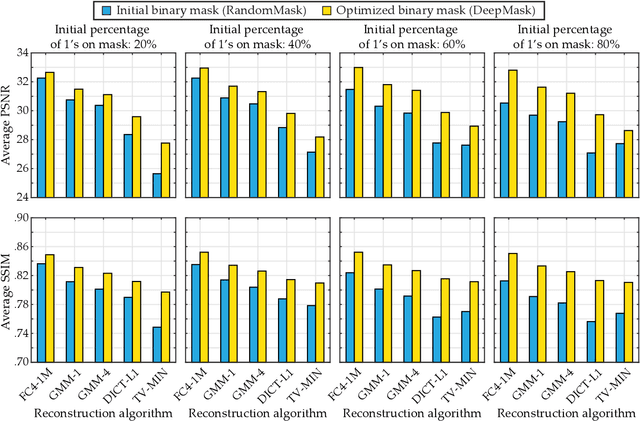
In this paper, we propose a novel encoder-decoder neural network model referred to as DeepBinaryMask for video compressive sensing. In video compressive sensing one frame is acquired using a set of coded masks (sensing matrix) from which a number of video frames is reconstructed, equal to the number of coded masks. The proposed framework is an end-to-end model where the sensing matrix is trained along with the video reconstruction. The encoder learns the binary elements of the sensing matrix and the decoder is trained to recover the unknown video sequence. The reconstruction performance is found to improve when using the trained sensing mask from the network as compared to other mask designs such as random, across a wide variety of compressive sensing reconstruction algorithms. Finally, our analysis and discussion offers insights into understanding the characteristics of the trained mask designs that lead to the improved reconstruction quality.