 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Multimodal Deepfake Detection Using Intra- and Cross-Modal Inconsistencies
Nov 28, 2023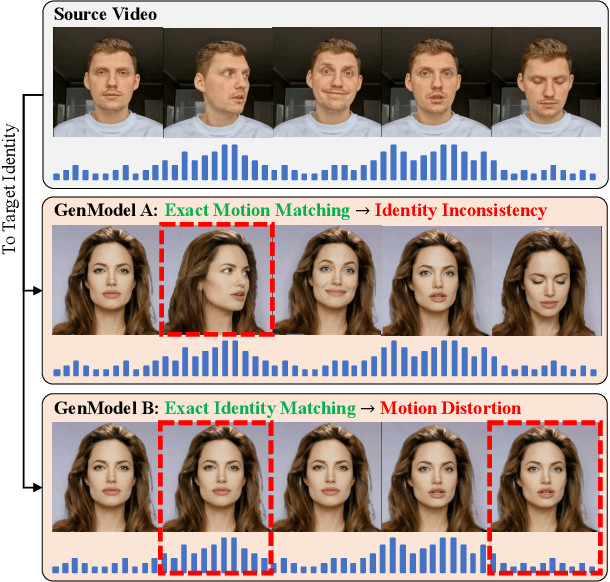
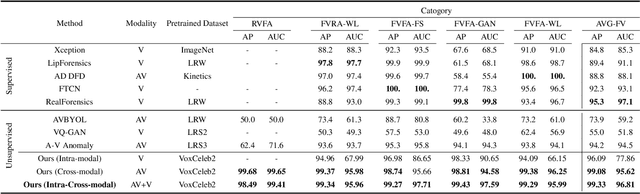
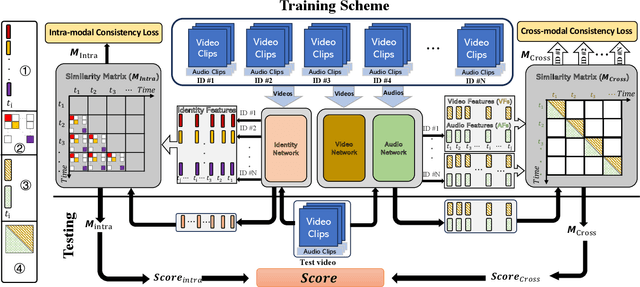
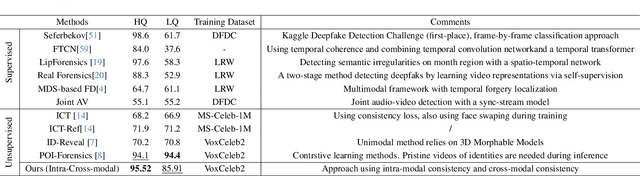
Deepfake videos present an increasing threat to society with potentially negative impact on criminal justice, democracy, and personal safety and privacy. Meanwhile, detecting deepfakes, at scale, remains a very challenging tasks that often requires labeled training data from existing deepfake generation methods. Further, even the most accurate supervised learning, deepfake detection methods do not generalize to deepfakes generated using new generation methods. In this paper, we introduce a novel unsupervised approach for detecting deepfake videos by measuring of intra- and cross-modal consistency among multimodal features; specifically visual, audio, and identity features. The fundamental hypothesis behind the proposed detection method is that since deepfake generation attempts to transfer the facial motion of one identity to another, these methods will eventually encounter a trade-off between motion and identity that enviably leads to detectable inconsistencies. We validate our method through extensive experimentation, demonstrating the existence of significant intra- and cross- modal inconsistencies in deepfake videos, which can be effectively utilized to detect them with high accuracy. Our proposed method is scalable because it does not require pristine samples at inference, generalizable because it is trained only on real data, and is explainable since it can pinpoint the exact location of modality inconsistencies which are then verifiable by a human expert.
In-Sensor & Neuromorphic Computing are all you need for Energy Efficient Computer Vision
Dec 21, 2022Due to the high activation sparsity and use of accumulates (AC) instead of expensive multiply-and-accumulates (MAC), neuromorphic spiking neural networks (SNNs) have emerged as a promising low-power alternative to traditional DNNs for several computer vision (CV) applications. However, most existing SNNs require multiple time steps for acceptable inference accuracy, hindering real-time deployment and increasing spiking activity and, consequently, energy consumption. Recent works proposed direct encoding that directly feeds the analog pixel values in the first layer of the SNN in order to significantly reduce the number of time steps. Although the overhead for the first layer MACs with direct encoding is negligible for deep SNNs and the CV processing is efficient using SNNs, the data transfer between the image sensors and the downstream processing costs significant bandwidth and may dominate the total energy. To mitigate this concern, we propose an in-sensor computing hardware-software co-design framework for SNNs targeting image recognition tasks. Our approach reduces the bandwidth between sensing and processing by 12-96x and the resulting total energy by 2.32x compared to traditional CV processing, with a 3.8% reduction in accuracy on ImageNet.
P2M-DeTrack: Processing-in-Pixel-in-Memory for Energy-efficient and Real-Time Multi-Object Detection and Tracking
May 28, 2022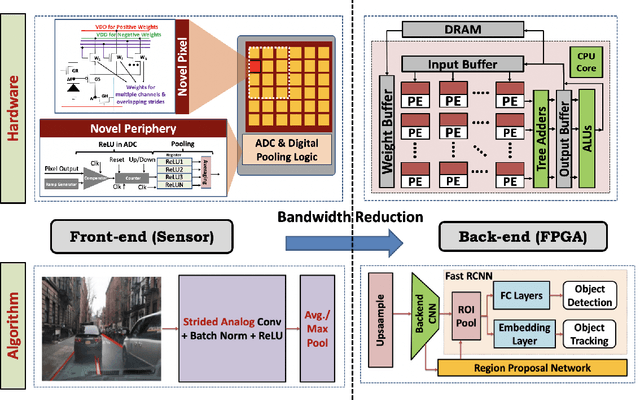
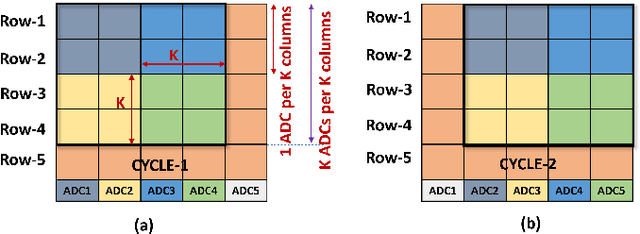
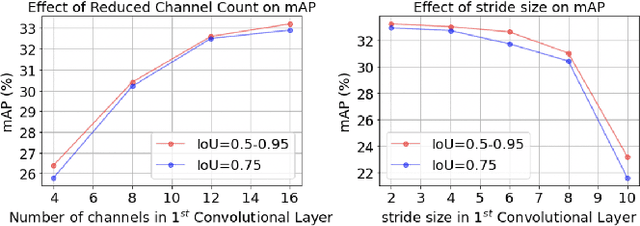
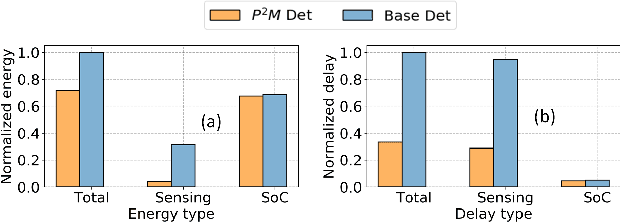
Today's high resolution, high frame rate cameras in autonomous vehicles generate a large volume of data that needs to be transferred and processed by a downstream processor or machine learning (ML) accelerator to enable intelligent computing tasks, such as multi-object detection and tracking. The massive amount of data transfer incurs significant energy, latency, and bandwidth bottlenecks, which hinders real-time processing. To mitigate this problem, we propose an algorithm-hardware co-design framework called Processing-in-Pixel-in-Memory-based object Detection and Tracking (P2M-DeTrack). P2M-DeTrack is based on a custom faster R-CNN-based model that is distributed partly inside the pixel array (front-end) and partly in a separate FPGA/ASIC (back-end). The proposed front-end in-pixel processing down-samples the input feature maps significantly with judiciously optimized strided convolution and pooling. Compared to a conventional baseline design that transfers frames of RGB pixels to the back-end, the resulting P2M-DeTrack designs reduce the data bandwidth between sensor and back-end by up to 24x. The designs also reduce the sensor and total energy (obtained from in-house circuit simulations at Globalfoundries 22nm technology node) per frame by 5.7x and 1.14x, respectively. Lastly, they reduce the sensing and total frame latency by an estimated 1.7x and 3x, respectively. We evaluate our approach on the multi-object object detection (tracking) task of the large-scale BDD100K dataset and observe only a 0.5% reduction in the mean average precision (0.8% reduction in the identification F1 score) compared to the state-of-the-art.
P2M: A Processing-in-Pixel-in-Memory Paradigm for Resource-Constrained TinyML Applications
Mar 17, 2022

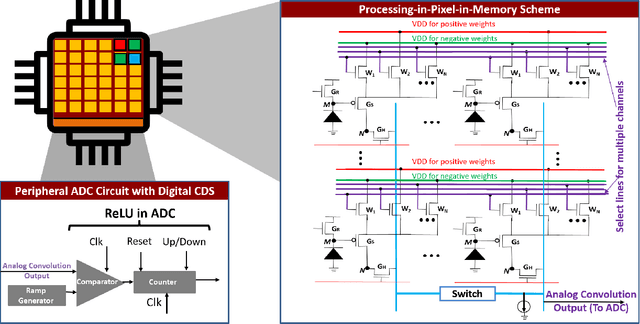

The demand to process vast amounts of data generated from state-of-the-art high resolution cameras has motivated novel energy-efficient on-device AI solutions. Visual data in such cameras are usually captured in the form of analog voltages by a sensor pixel array, and then converted to the digital domain for subsequent AI processing using analog-to-digital converters (ADC). Recent research has tried to take advantage of massively parallel low-power analog/digital computing in the form of near- and in-sensor processing, in which the AI computation is performed partly in the periphery of the pixel array and partly in a separate on-board CPU/accelerator. Unfortunately, high-resolution input images still need to be streamed between the camera and the AI processing unit, frame by frame, causing energy, bandwidth, and security bottlenecks. To mitigate this problem, we propose a novel Processing-in-Pixel-in-memory (P2M) paradigm, that customizes the pixel array by adding support for analog multi-channel, multi-bit convolution, batch normalization, and ReLU (Rectified Linear Units). Our solution includes a holistic algorithm-circuit co-design approach and the resulting P2M paradigm can be used as a drop-in replacement for embedding memory-intensive first few layers of convolutional neural network (CNN) models within foundry-manufacturable CMOS image sensor platforms. Our experimental results indicate that P2M reduces data transfer bandwidth from sensors and analog to digital conversions by ~21x, and the energy-delay product (EDP) incurred in processing a MobileNetV2 model on a TinyML use case for visual wake words dataset (VWW) by up to ~11x compared to standard near-processing or in-sensor implementations, without any significant drop in test accuracy.
Detection and Continual Learning of Novel Face Presentation Attacks
Aug 27, 2021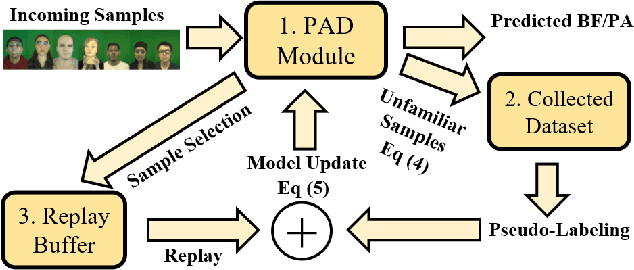


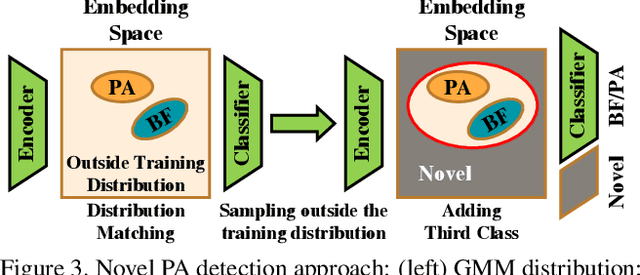
Advances in deep learning, combined with availability of large datasets, have led to impressive improvements in face presentation attack detection research. However, state-of-the-art face antispoofing systems are still vulnerable to novel types of attacks that are never seen during training. Moreover, even if such attacks are correctly detected, these systems lack the ability to adapt to newly encountered attacks. The post-training ability of continually detecting new types of attacks and self-adaptation to identify these attack types, after the initial detection phase, is highly appealing. In this paper, we enable a deep neural network to detect anomalies in the observed input data points as potential new types of attacks by suppressing the confidence-level of the network outside the training samples' distribution. We then use experience replay to update the model to incorporate knowledge about new types of attacks without forgetting the past learned attack types. Experimental results are provided to demonstrate the effectiveness of the proposed method on two benchmark datasets as well as a newly introduced dataset which exhibits a large variety of attack types.
Multispectral Biometrics System Framework: Application to Presentation Attack Detection
Jun 12, 2020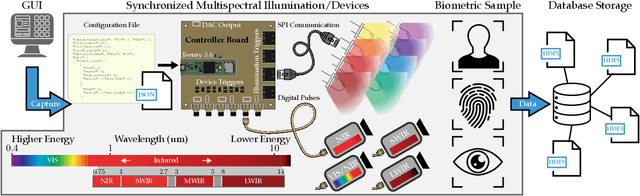
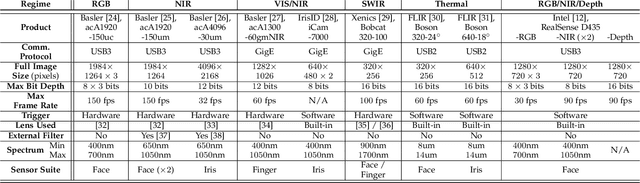
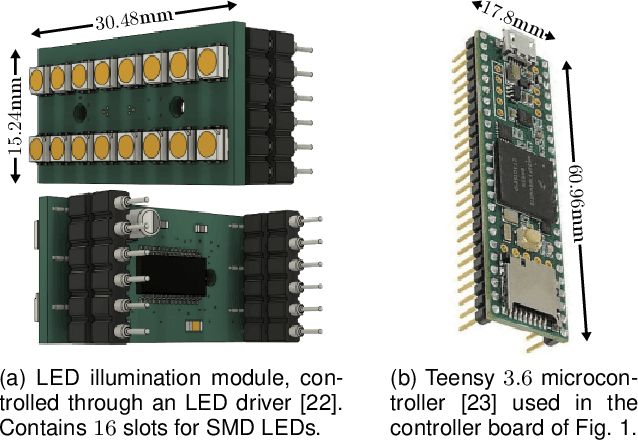
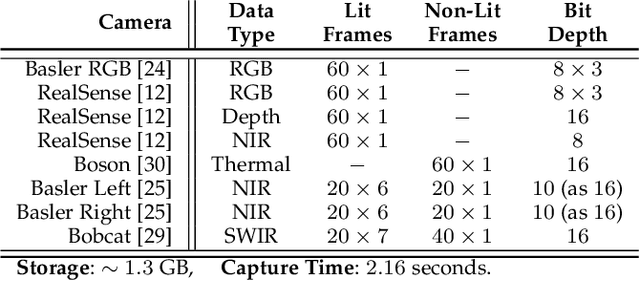
In this work, we present a general framework for building a biometrics system capable of capturing multispectral data from a series of sensors synchronized with active illumination sources. The framework unifies the system design for different biometric modalities and its realization on face, finger and iris data is described in detail. To the best of our knowledge, the presented design is the first to employ such a diverse set of electromagnetic spectrum bands, ranging from visible to long-wave-infrared wavelengths, and is capable of acquiring large volumes of data in seconds. Having performed a series of data collections, we run a comprehensive analysis on the captured data using a deep-learning classifier for presentation attack detection. Our study follows a data-centric approach attempting to highlight the strengths and weaknesses of each spectral band at distinguishing live from fake samples.
Learning Structure via Consensus for Face Segmentation and Parsing
Nov 10, 2019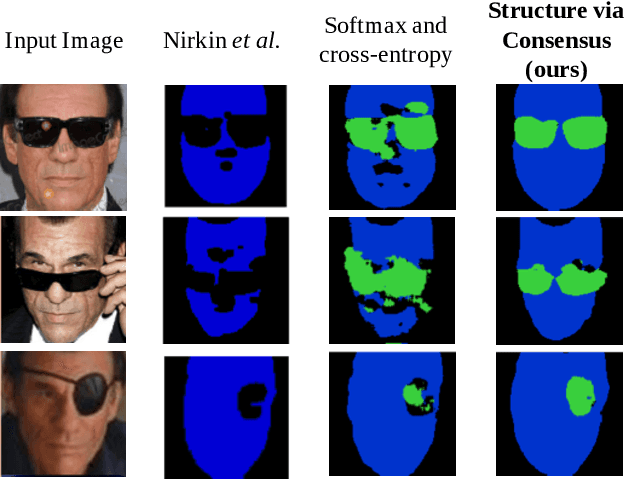
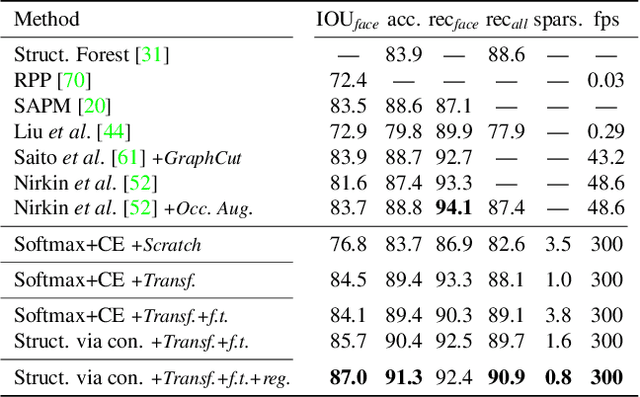

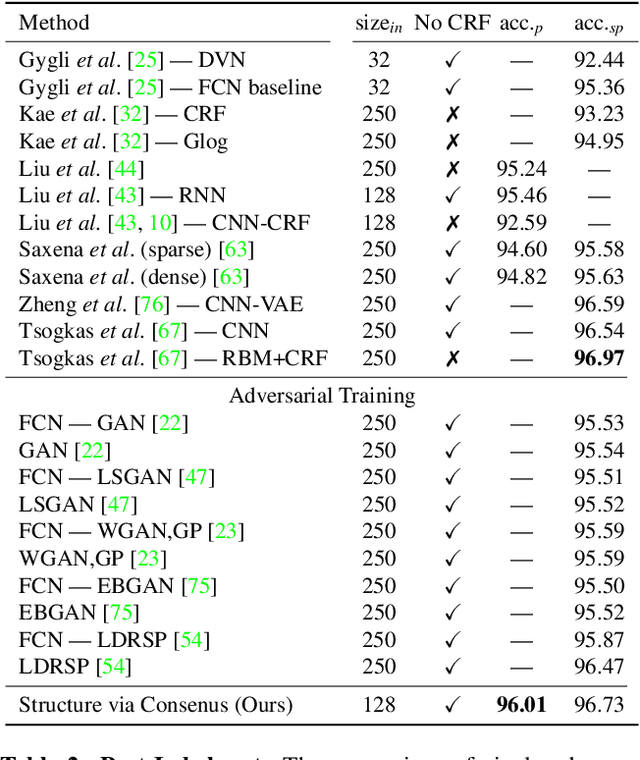
Face segmentation is the task of densely labeling pixels on the face according to their semantics. While current methods place an emphasis on developing sophisticated architectures, use conditional random fields for smoothness, or rather employ adversarial training, we follow an alternative path towards robust face segmentation and parsing. Occlusions, along with other parts of the face, have a proper structure that needs to be propagated in the model during training. Unlike state-of-the-art methods that treat face segmentation as an independent pixel prediction problem, we argue instead that it should hold highly correlated outputs within the same object pixels. We thereby offer a novel learning mechanism to enforce structure in the prediction via consensus, guided by a robust loss function that forces pixel objects to be consistent with each other. Our face parser is trained by transferring knowledge from another model, yet it encourages spatial consistency while fitting the labels. Different than current practice, our method enjoys pixel-wise predictions, yet paves the way for fewer artifacts, less sparse masks, and spatially coherent outputs.
Does Generative Face Completion Help Face Recognition?
Jun 07, 2019
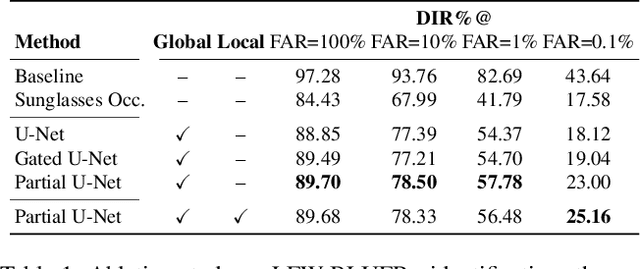
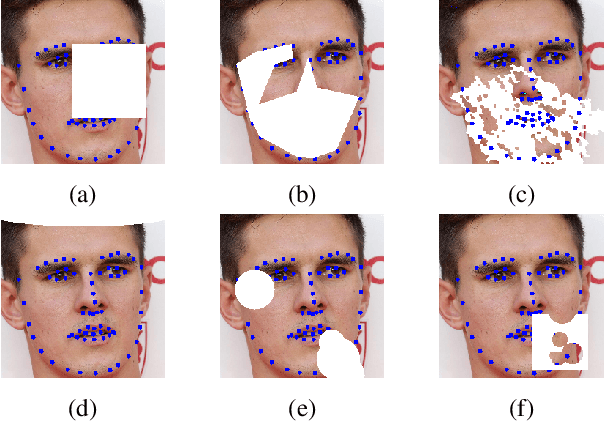

Face occlusions, covering either the majority or discriminative parts of the face, can break facial perception and produce a drastic loss of information. Biometric systems such as recent deep face recognition models are not immune to obstructions or other objects covering parts of the face. While most of the current face recognition methods are not optimized to handle occlusions, there have been a few attempts to improve robustness directly in the training stage. Unlike those, we propose to study the effect of generative face completion on the recognition. We offer a face completion encoder-decoder, based on a convolutional operator with a gating mechanism, trained with an ample set of face occlusions. To systematically evaluate the impact of realistic occlusions on recognition, we propose to play the occlusion game: we render 3D objects onto different face parts, providing precious knowledge of what the impact is of effectively removing those occlusions. Extensive experiments on the Labeled Faces in the Wild (LFW), and its more difficult variant LFW-BLUFR, testify that face completion is able to partially restore face perception in machine vision systems for improved recognition.