 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Structure via Consensus for Face Segmentation and Parsing
Paper and Code
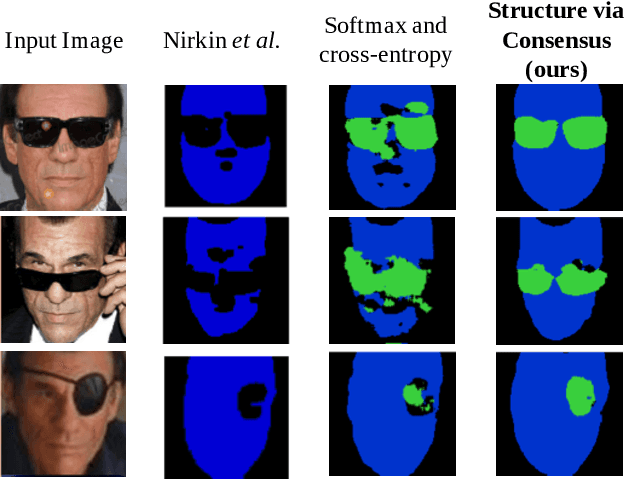
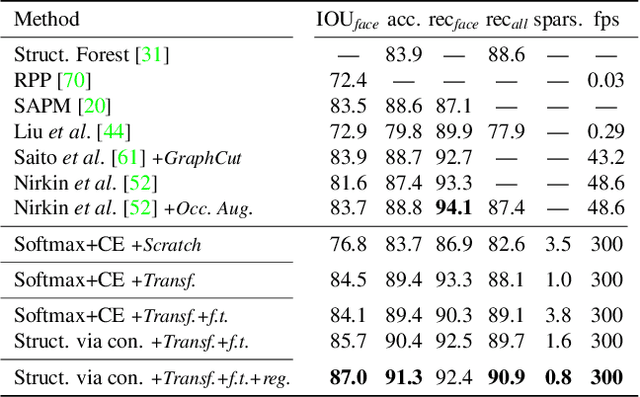

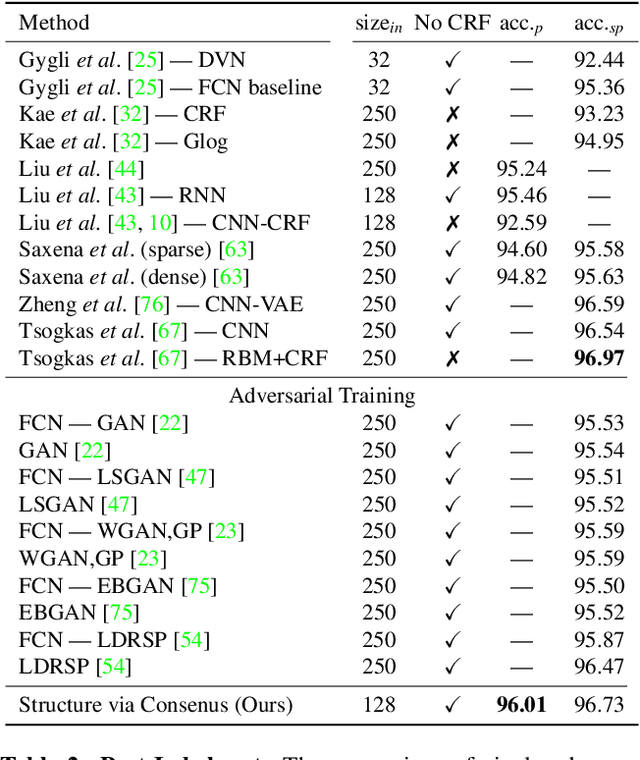
Face segmentation is the task of densely labeling pixels on the face according to their semantics. While current methods place an emphasis on developing sophisticated architectures, use conditional random fields for smoothness, or rather employ adversarial training, we follow an alternative path towards robust face segmentation and parsing. Occlusions, along with other parts of the face, have a proper structure that needs to be propagated in the model during training. Unlike state-of-the-art methods that treat face segmentation as an independent pixel prediction problem, we argue instead that it should hold highly correlated outputs within the same object pixels. We thereby offer a novel learning mechanism to enforce structure in the prediction via consensus, guided by a robust loss function that forces pixel objects to be consistent with each other. Our face parser is trained by transferring knowledge from another model, yet it encourages spatial consistency while fitting the labels. Different than current practice, our method enjoys pixel-wise predictions, yet paves the way for fewer artifacts, less sparse masks, and spatially coherent outputs.