 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoltage-Controlled Magnetic Tunnel Junction based ADC-less Global Shutter Processing-in-Pixel for Extreme-Edge Intelligence
Oct 14, 2024



The vast amount of data generated by camera sensors has prompted the exploration of energy-efficient processing solutions for deploying computer vision tasks on edge devices. Among the various approaches studied, processing-in-pixel integrates massively parallel analog computational capabilities at the extreme-edge, i.e., within the pixel array and exhibits enhanced energy and bandwidth efficiency by generating the output activations of the first neural network layer rather than the raw sensory data. In this article, we propose an energy and bandwidth efficient ADC-less processing-in-pixel architecture. This architecture implements an optimized binary activation neural network trained using Hoyer regularizer for high accuracy on complex vision tasks. In addition, we also introduce a global shutter burst memory read scheme utilizing fast and disturb-free read operation leveraging innovative use of nanoscale voltage-controlled magnetic tunnel junctions (VC-MTJs). Moreover, we develop an algorithmic framework incorporating device and circuit constraints (characteristic device switching behavior and circuit non-linearity) based on state-of-the-art fabricated VC-MTJ characteristics and extensive circuit simulations using commercial GlobalFoundries 22nm FDX technology. Finally, we evaluate the proposed system's performance on two complex datasets - CIFAR10 and ImageNet, showing improvements in front-end and communication energy efficiency by 8.2x and 8.5x respectively and reduction in bandwidth by 6x compared to traditional computer vision systems, without any significant drop in the test accuracy.
Technology-Circuit-Algorithm Tri-Design for Processing-in-Pixel-in-Memory (P2M)
Apr 06, 2023



The massive amounts of data generated by camera sensors motivate data processing inside pixel arrays, i.e., at the extreme-edge. Several critical developments have fueled recent interest in the processing-in-pixel-in-memory paradigm for a wide range of visual machine intelligence tasks, including (1) advances in 3D integration technology to enable complex processing inside each pixel in a 3D integrated manner while maintaining pixel density, (2) analog processing circuit techniques for massively parallel low-energy in-pixel computations, and (3) algorithmic techniques to mitigate non-idealities associated with analog processing through hardware-aware training schemes. This article presents a comprehensive technology-circuit-algorithm landscape that connects technology capabilities, circuit design strategies, and algorithmic optimizations to power, performance, area, bandwidth reduction, and application-level accuracy metrics. We present our results using a comprehensive co-design framework incorporating hardware and algorithmic optimizations for various complex real-life visual intelligence tasks mapped onto our P2M paradigm.
Neuromorphic-P2M: Processing-in-Pixel-in-Memory Paradigm for Neuromorphic Image Sensors
Jan 22, 2023



Edge devices equipped with computer vision must deal with vast amounts of sensory data with limited computing resources. Hence, researchers have been exploring different energy-efficient solutions such as near-sensor processing, in-sensor processing, and in-pixel processing, bringing the computation closer to the sensor. In particular, in-pixel processing embeds the computation capabilities inside the pixel array and achieves high energy efficiency by generating low-level features instead of the raw data stream from CMOS image sensors. Many different in-pixel processing techniques and approaches have been demonstrated on conventional frame-based CMOS imagers, however, the processing-in-pixel approach for neuromorphic vision sensors has not been explored so far. In this work, we for the first time, propose an asynchronous non-von-Neumann analog processing-in-pixel paradigm to perform convolution operations by integrating in-situ multi-bit multi-channel convolution inside the pixel array performing analog multiply and accumulate (MAC) operations that consume significantly less energy than their digital MAC alternative. To make this approach viable, we incorporate the circuit's non-ideality, leakage, and process variations into a novel hardware-algorithm co-design framework that leverages extensive HSpice simulations of our proposed circuit using the GF22nm FD-SOI technology node. We verified our framework on state-of-the-art neuromorphic vision sensor datasets and show that our solution consumes ~2x lower backend-processor energy while maintaining almost similar front-end (sensor) energy on the IBM DVS128-Gesture dataset than the state-of-the-art while maintaining a high test accuracy of 88.36%.
In-Sensor & Neuromorphic Computing are all you need for Energy Efficient Computer Vision
Dec 21, 2022Due to the high activation sparsity and use of accumulates (AC) instead of expensive multiply-and-accumulates (MAC), neuromorphic spiking neural networks (SNNs) have emerged as a promising low-power alternative to traditional DNNs for several computer vision (CV) applications. However, most existing SNNs require multiple time steps for acceptable inference accuracy, hindering real-time deployment and increasing spiking activity and, consequently, energy consumption. Recent works proposed direct encoding that directly feeds the analog pixel values in the first layer of the SNN in order to significantly reduce the number of time steps. Although the overhead for the first layer MACs with direct encoding is negligible for deep SNNs and the CV processing is efficient using SNNs, the data transfer between the image sensors and the downstream processing costs significant bandwidth and may dominate the total energy. To mitigate this concern, we propose an in-sensor computing hardware-software co-design framework for SNNs targeting image recognition tasks. Our approach reduces the bandwidth between sensing and processing by 12-96x and the resulting total energy by 2.32x compared to traditional CV processing, with a 3.8% reduction in accuracy on ImageNet.
P2M-DeTrack: Processing-in-Pixel-in-Memory for Energy-efficient and Real-Time Multi-Object Detection and Tracking
May 28, 2022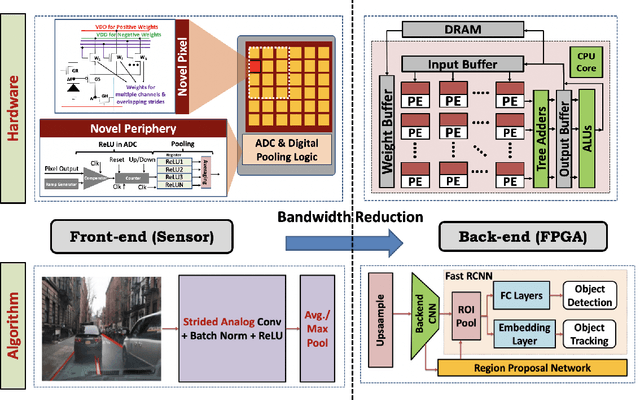
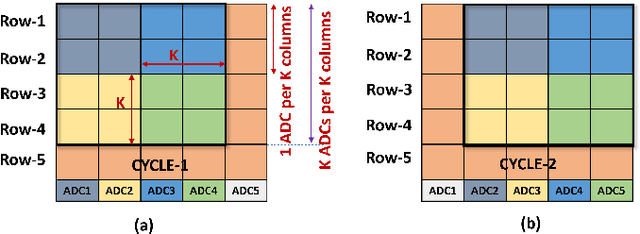
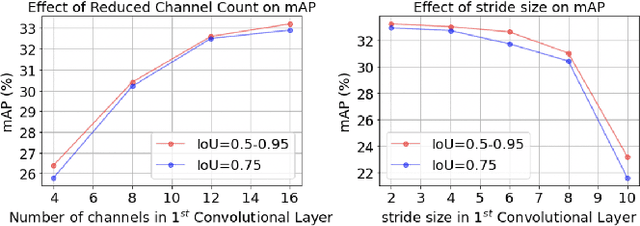
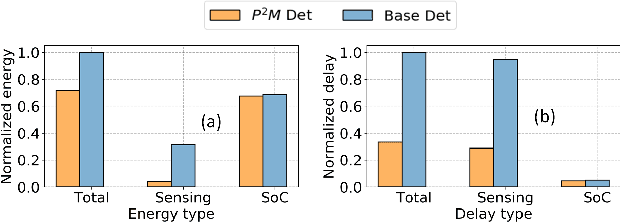
Today's high resolution, high frame rate cameras in autonomous vehicles generate a large volume of data that needs to be transferred and processed by a downstream processor or machine learning (ML) accelerator to enable intelligent computing tasks, such as multi-object detection and tracking. The massive amount of data transfer incurs significant energy, latency, and bandwidth bottlenecks, which hinders real-time processing. To mitigate this problem, we propose an algorithm-hardware co-design framework called Processing-in-Pixel-in-Memory-based object Detection and Tracking (P2M-DeTrack). P2M-DeTrack is based on a custom faster R-CNN-based model that is distributed partly inside the pixel array (front-end) and partly in a separate FPGA/ASIC (back-end). The proposed front-end in-pixel processing down-samples the input feature maps significantly with judiciously optimized strided convolution and pooling. Compared to a conventional baseline design that transfers frames of RGB pixels to the back-end, the resulting P2M-DeTrack designs reduce the data bandwidth between sensor and back-end by up to 24x. The designs also reduce the sensor and total energy (obtained from in-house circuit simulations at Globalfoundries 22nm technology node) per frame by 5.7x and 1.14x, respectively. Lastly, they reduce the sensing and total frame latency by an estimated 1.7x and 3x, respectively. We evaluate our approach on the multi-object object detection (tracking) task of the large-scale BDD100K dataset and observe only a 0.5% reduction in the mean average precision (0.8% reduction in the identification F1 score) compared to the state-of-the-art.