 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedVTP: Training-Free Acceleration of Diffusion Vision-Language Models Inference via Masked Token-Guided Visual Token Pruning
Nov 16, 2025



Vision-Language Models (VLMs) have achieved remarkable progress in multimodal reasoning and generation, yet their high computational demands remain a major challenge. Diffusion Vision-Language Models (DVLMs) are particularly attractive because they enable parallel token decoding, but the large number of visual tokens still significantly hinders their inference efficiency. While visual token pruning has been extensively studied for autoregressive VLMs (AVLMs), it remains largely unexplored for DVLMs. In this work, we propose RedVTP, a response-driven visual token pruning strategy that leverages the inference dynamics of DVLMs. Our method estimates visual token importance using attention from the masked response tokens. Based on the observation that these importance scores remain consistent across steps, RedVTP prunes the less important visual tokens from the masked tokens after the first inference step, thereby maximizing inference efficiency. Experiments show that RedVTP improves token generation throughput of LLaDA-V and LaViDa by up to 186% and 28.05%, respectively, and reduces inference latency by up to 64.97% and 21.87%, without compromising-and in some cases improving-accuracy.
Mitigating Hallucinations in Vision-Language Models through Image-Guided Head Suppression
May 22, 2025Despite their remarkable progress in multimodal understanding tasks, large vision language models (LVLMs) often suffer from "hallucinations", generating texts misaligned with the visual context. Existing methods aimed at reducing hallucinations through inference time intervention incur a significant increase in latency. To mitigate this, we present SPIN, a task-agnostic attention-guided head suppression strategy that can be seamlessly integrated during inference, without incurring any significant compute or latency overhead. We investigate whether hallucination in LVLMs can be linked to specific model components. Our analysis suggests that hallucinations can be attributed to a dynamic subset of attention heads in each layer. Leveraging this insight, for each text query token, we selectively suppress attention heads that exhibit low attention to image tokens, keeping the top-K attention heads intact. Extensive evaluations on visual question answering and image description tasks demonstrate the efficacy of SPIN in reducing hallucination scores up to 2.7x while maintaining F1, and improving throughput by 1.8x compared to existing alternatives. Code is available at https://github.com/YUECHE77/SPIN.
OASIS: Optimized Lightweight Autoencoder System for Distributed In-Sensor computing
May 04, 2025



In-sensor computing, which integrates computation directly within the sensor, has emerged as a promising paradigm for machine vision applications such as AR/VR and smart home systems. By processing data on-chip before transmission, it alleviates the bandwidth bottleneck caused by high-resolution, high-frame-rate image transmission, particularly in video applications. We envision a system architecture that integrates a CMOS image sensor (CIS) with a logic chip via advanced packaging, where the logic chip processes early-stage deep neural network (DNN) layers. However, its limited compute and memory make deploying advanced DNNs challenging. A simple solution is to split the model, executing the first part on the logic chip and the rest off-chip. However, modern DNNs require multiple layers before dimensionality reduction, limiting their ability to achieve the primary goal of in-sensor computing: minimizing data bandwidth. To address this, we propose a dual-branch autoencoder-based vision architecture that deploys a lightweight encoder on the logic chip while the task-specific network runs off-chip. The encoder is trained using a triple loss function: (1) task-specific loss to optimize accuracy, (2) entropy loss to enforce compact and compressible representations, and (3) reconstruction loss (mean-square error) to preserve essential visual information. This design enables a four-order-of-magnitude reduction in output activation dimensionality compared to input images, resulting in a $2{-}4.5\times$ decrease in energy consumption, as validated by our hardware-backed semi-analytical energy models. We evaluate our approach on CNN and ViT-based models across applications in smart home and augmented reality domains, achieving state-of-the-art accuracy with energy efficiency of up to 22.7 TOPS/W.
Region Masking to Accelerate Video Processing on Neuromorphic Hardware
Mar 21, 2025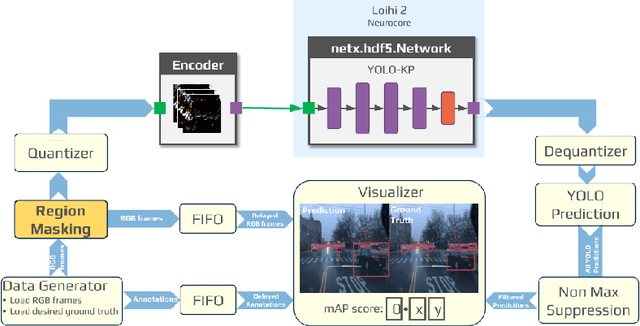
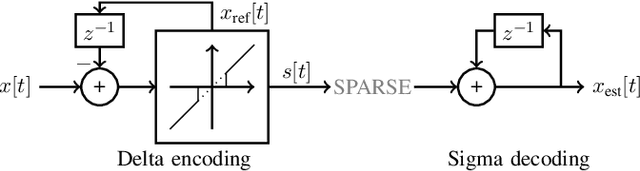
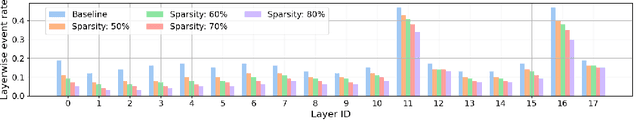
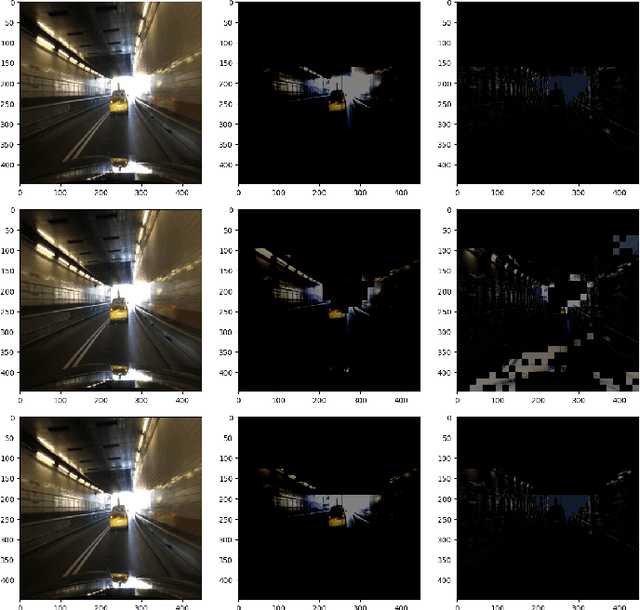
The rapidly growing demand for on-chip edge intelligence on resource-constrained devices has motivated approaches to reduce energy and latency of deep learning models. Spiking neural networks (SNNs) have gained particular interest due to their promise to reduce energy consumption using event-based processing. We assert that while sigma-delta encoding in SNNs can take advantage of the temporal redundancy across video frames, they still involve a significant amount of redundant computations due to processing insignificant events. In this paper, we propose a region masking strategy that identifies regions of interest at the input of the SNN, thereby eliminating computation and data movement for events arising from unimportant regions. Our approach demonstrates that masking regions at the input not only significantly reduces the overall spiking activity of the network, but also provides significant improvement in throughput and latency. We apply region masking during video object detection on Loihi 2, demonstrating that masking approximately 60% of input regions can reduce energy-delay product by 1.65x over a baseline sigma-delta network, with a degradation in mAP@0.5 by 1.09%.
Energy-Efficient & Real-Time Computer Vision with Intelligent Skipping via Reconfigurable CMOS Image Sensors
Sep 25, 2024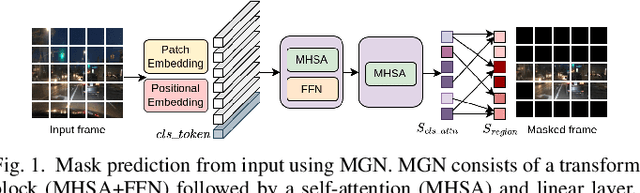
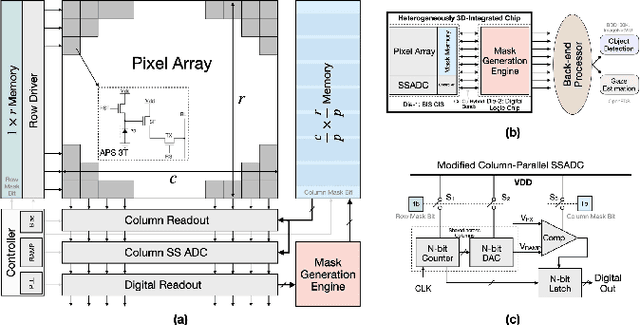
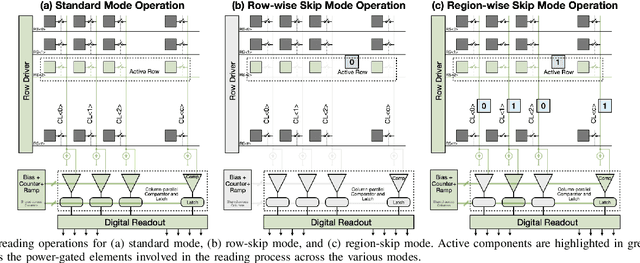
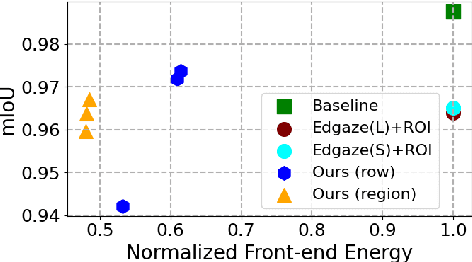
Current video-based computer vision (CV) applications typically suffer from high energy consumption due to reading and processing all pixels in a frame, regardless of their significance. While previous works have attempted to reduce this energy by skipping input patches or pixels and using feedback from the end task to guide the skipping algorithm, the skipping is not performed during the sensor read phase. As a result, these methods can not optimize the front-end sensor energy. Moreover, they may not be suitable for real-time applications due to the long latency of modern CV networks that are deployed in the back-end. To address this challenge, this paper presents a custom-designed reconfigurable CMOS image sensor (CIS) system that improves energy efficiency by selectively skipping uneventful regions or rows within a frame during the sensor's readout phase, and the subsequent analog-to-digital conversion (ADC) phase. A novel masking algorithm intelligently directs the skipping process in real-time, optimizing both the front-end sensor and back-end neural networks for applications including autonomous driving and augmented/virtual reality (AR/VR). Our system can also operate in standard mode without skipping, depending on application needs. We evaluate our hardware-algorithm co-design framework on object detection based on BDD100K and ImageNetVID, and gaze estimation based on OpenEDS, achieving up to 53% reduction in front-end sensor energy while maintaining state-of-the-art (SOTA) accuracy.
MaskVD: Region Masking for Efficient Video Object Detection
Jul 16, 2024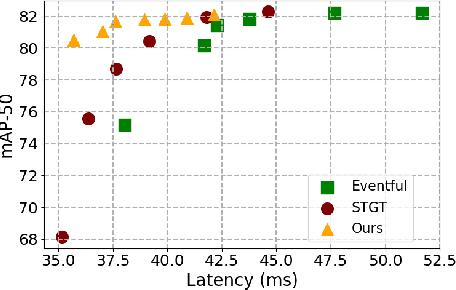
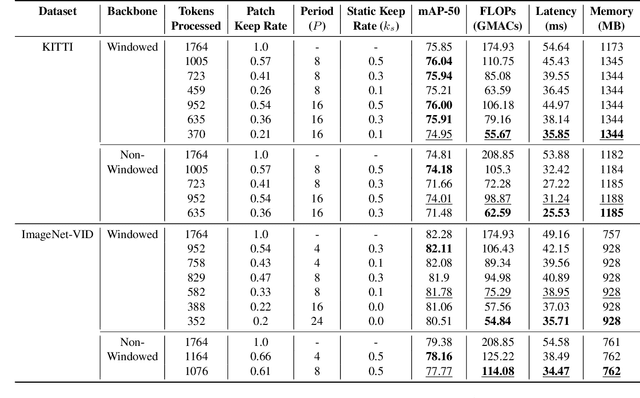
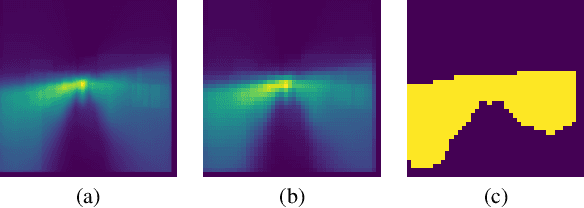
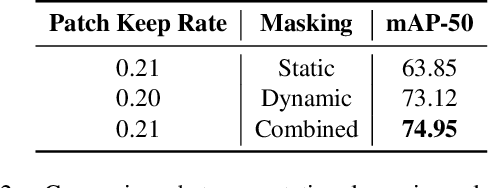
Video tasks are compute-heavy and thus pose a challenge when deploying in real-time applications, particularly for tasks that require state-of-the-art Vision Transformers (ViTs). Several research efforts have tried to address this challenge by leveraging the fact that large portions of the video undergo very little change across frames, leading to redundant computations in frame-based video processing. In particular, some works leverage pixel or semantic differences across frames, however, this yields limited latency benefits with significantly increased memory overhead. This paper, in contrast, presents a strategy for masking regions in video frames that leverages the semantic information in images and the temporal correlation between frames to significantly reduce FLOPs and latency with little to no penalty in performance over baseline models. In particular, we demonstrate that by leveraging extracted features from previous frames, ViT backbones directly benefit from region masking, skipping up to 80% of input regions, improving FLOPs and latency by 3.14x and 1.5x. We improve memory and latency over the state-of-the-art (SOTA) by 2.3x and 1.14x, while maintaining similar detection performance. Additionally, our approach demonstrates promising results on convolutional neural networks (CNNs) and provides latency improvements over the SOTA up to 1.3x using specialized computational kernels.
Linearizing Models for Efficient yet Robust Private Inference
Feb 08, 2024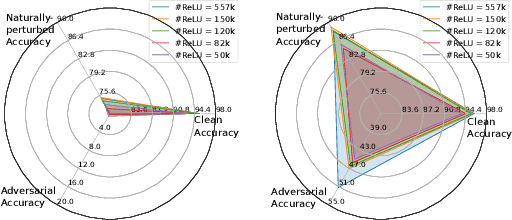

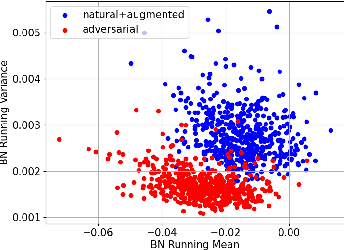

The growing concern about data privacy has led to the development of private inference (PI) frameworks in client-server applications which protects both data privacy and model IP. However, the cryptographic primitives required yield significant latency overhead which limits its wide-spread application. At the same time, changing environments demand the PI service to be robust against various naturally occurring and gradient-based perturbations. Despite several works focused on the development of latency-efficient models suitable for PI, the impact of these models on robustness has remained unexplored. Towards this goal, this paper presents RLNet, a class of robust linearized networks that can yield latency improvement via reduction of high-latency ReLU operations while improving the model performance on both clean and corrupted images. In particular, RLNet models provide a "triple win ticket" of improved classification accuracy on clean, naturally perturbed, and gradient-based perturbed images using a shared-mask shared-weight architecture with over an order of magnitude fewer ReLUs than baseline models. To demonstrate the efficacy of RLNet, we perform extensive experiments with ResNet and WRN model variants on CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets. Our experimental evaluations show that RLNet can yield models with up to 11.14x fewer ReLUs, with accuracy close to the all-ReLU models, on clean, naturally perturbed, and gradient-based perturbed images. Compared with the SoTA non-robust linearized models at similar ReLU budgets, RLNet achieves an improvement in adversarial accuracy of up to ~47%, naturally perturbed accuracy up to ~16.4%, while improving clean image accuracy up to ~1.5%.
FixPix: Fixing Bad Pixels using Deep Learning
Oct 18, 2023Efficient and effective on-line detection and correction of bad pixels can improve yield and increase the expected lifetime of image sensors. This paper presents a comprehensive Deep Learning (DL) based on-line detection-correction approach, suitable for a wide range of pixel corruption rates. A confidence calibrated segmentation approach is introduced, which achieves nearly perfect bad pixel detection, even with few training samples. A computationally light-weight correction algorithm is proposed for low rates of pixel corruption, that surpasses the accuracy of traditional interpolation-based techniques. We also propose an autoencoder based image reconstruction approach which alleviates the need for prior bad pixel detection and yields promising results for high rates of pixel corruption. Unlike previous methods, which use proprietary images, we demonstrate the efficacy of the proposed methods on the open-source Samsung S7 ISP and MIT-Adobe FiveK datasets. Our approaches yield up to 99.6% detection accuracy with <0.6% false positives and corrected images within 1.5% average pixel error from 70% corrupted images.
Technology-Circuit-Algorithm Tri-Design for Processing-in-Pixel-in-Memory (P2M)
Apr 06, 2023The massive amounts of data generated by camera sensors motivate data processing inside pixel arrays, i.e., at the extreme-edge. Several critical developments have fueled recent interest in the processing-in-pixel-in-memory paradigm for a wide range of visual machine intelligence tasks, including (1) advances in 3D integration technology to enable complex processing inside each pixel in a 3D integrated manner while maintaining pixel density, (2) analog processing circuit techniques for massively parallel low-energy in-pixel computations, and (3) algorithmic techniques to mitigate non-idealities associated with analog processing through hardware-aware training schemes. This article presents a comprehensive technology-circuit-algorithm landscape that connects technology capabilities, circuit design strategies, and algorithmic optimizations to power, performance, area, bandwidth reduction, and application-level accuracy metrics. We present our results using a comprehensive co-design framework incorporating hardware and algorithmic optimizations for various complex real-life visual intelligence tasks mapped onto our P2M paradigm.