 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Latent Entropy Estimation Disentanglement: Controlled Attribute Leakage for Face Recognition
Apr 13, 2026Face recognition embeddings encode identity, but they also encode other factors such as gender and ethnicity. Depending on how these factors are used by a downstream system, separating them from the information needed for verification is important for both privacy and fairness. We propose Variational Latent Entropy Estimation Disentanglement (VLEED), a post-hoc method that transforms pretrained embeddings with a variational autoencoder and encourages a distilled representation where the categorical variable of interest is separated from identity-relevant information. VLEED uses a mutual information-based objective realised through the estimation of the entropy of the categorical attribute in the latent space, and provides stable training with fine-grained control over information removal. We evaluate our method on IJB-C, RFW, and VGGFace2 for gender and ethnicity disentanglement, and compare it to various state-of-the-art methods. We report verification utility, predictability of the disentangled variable under linear and nonlinear classifiers, and group disparity metrics based on false match rates. Our results show that VLEED offers a wide range of privacy-utility tradeoffs over existing methods and can also reduce recognition bias across demographic groups.
Demographic Fairness in Multimodal LLMs: A Benchmark of Gender and Ethnicity Bias in Face Verification
Mar 26, 2026Multimodal Large Language Models (MLLMs) have recently been explored as face verification systems that determine whether two face images are of the same person. Unlike dedicated face recognition systems, MLLMs approach this task through visual prompting and rely on general visual and reasoning abilities. However, the demographic fairness of these models remains largely unexplored. In this paper, we present a benchmarking study that evaluates nine open-source MLLMs from six model families, ranging from 2B to 8B parameters, on the IJB-C and RFW face verification protocols across four ethnicity groups and two gender groups. We measure verification accuracy with the Equal Error Rate and True Match Rate at multiple operating points per demographic group, and we quantify demographic disparity with four FMR-based fairness metrics. Our results show that FaceLLM-8B, the only face-specialised model in our study, substantially outperforms general-purpose MLLMs on both benchmarks. The bias patterns we observe differ from those commonly reported for traditional face recognition, with different groups being most affected depending on the benchmark and the model. We also note that the most accurate models are not necessarily the fairest and that models with poor overall accuracy can appear fair simply because they produce uniformly high error rates across all demographic groups.
FantasyID: A dataset for detecting digital manipulations of ID-documents
Jul 28, 2025Advancements in image generation led to the availability of easy-to-use tools for malicious actors to create forged images. These tools pose a serious threat to the widespread Know Your Customer (KYC) applications, requiring robust systems for detection of the forged Identity Documents (IDs). To facilitate the development of the detection algorithms, in this paper, we propose a novel publicly available (including commercial use) dataset, FantasyID, which mimics real-world IDs but without tampering with legal documents and, compared to previous public datasets, it does not contain generated faces or specimen watermarks. FantasyID contains ID cards with diverse design styles, languages, and faces of real people. To simulate a realistic KYC scenario, the cards from FantasyID were printed and captured with three different devices, constituting the bonafide class. We have emulated digital forgery/injection attacks that could be performed by a malicious actor to tamper the IDs using the existing generative tools. The current state-of-the-art forgery detection algorithms, such as TruFor, MMFusion, UniFD, and FatFormer, are challenged by FantasyID dataset. It especially evident, in the evaluation conditions close to practical, with the operational threshold set on validation set so that false positive rate is at 10%, leading to false negative rates close to 50% across the board on the test set. The evaluation experiments demonstrate that FantasyID dataset is complex enough to be used as an evaluation benchmark for detection algorithms.
HintsOfTruth: A Multimodal Checkworthiness Detection Dataset with Real and Synthetic Claims
Feb 17, 2025
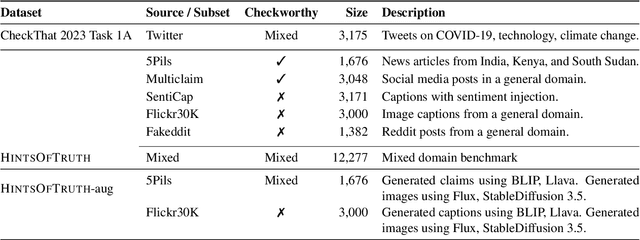
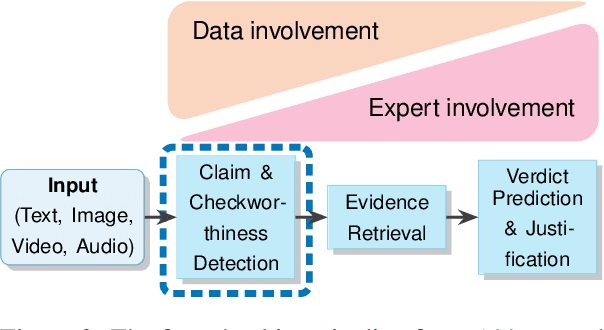
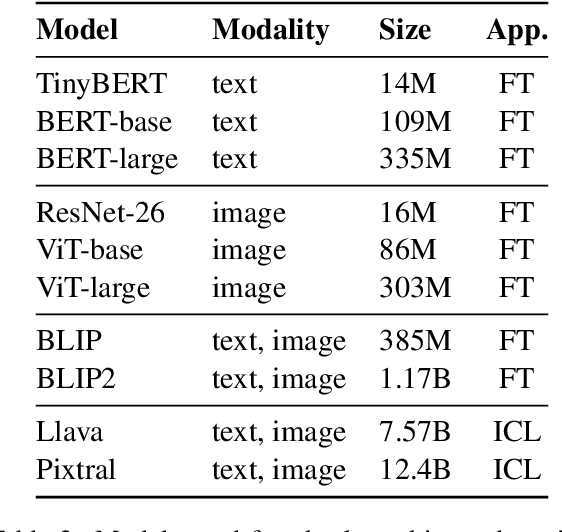
Misinformation can be countered with fact-checking, but the process is costly and slow. Identifying checkworthy claims is the first step, where automation can help scale fact-checkers' efforts. However, detection methods struggle with content that is 1) multimodal, 2) from diverse domains, and 3) synthetic. We introduce HintsOfTruth, a public dataset for multimodal checkworthiness detection with $27$K real-world and synthetic image/claim pairs. The mix of real and synthetic data makes this dataset unique and ideal for benchmarking detection methods. We compare fine-tuned and prompted Large Language Models (LLMs). We find that well-configured lightweight text-based encoders perform comparably to multimodal models but the first only focus on identifying non-claim-like content. Multimodal LLMs can be more accurate but come at a significant computational cost, making them impractical for large-scale applications. When faced with synthetic data, multimodal models perform more robustly
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
HyperFace: Generating Synthetic Face Recognition Datasets by Exploring Face Embedding Hypersphere
Nov 13, 2024Face recognition datasets are often collected by crawling Internet and without individuals' consents, raising ethical and privacy concerns. Generating synthetic datasets for training face recognition models has emerged as a promising alternative. However, the generation of synthetic datasets remains challenging as it entails adequate inter-class and intra-class variations. While advances in generative models have made it easier to increase intra-class variations in face datasets (such as pose, illumination, etc.), generating sufficient inter-class variation is still a difficult task. In this paper, we formulate the dataset generation as a packing problem on the embedding space (represented on a hypersphere) of a face recognition model and propose a new synthetic dataset generation approach, called HyperFace. We formalize our packing problem as an optimization problem and solve it with a gradient descent-based approach. Then, we use a conditional face generator model to synthesize face images from the optimized embeddings. We use our generated datasets to train face recognition models and evaluate the trained models on several benchmarking real datasets. Our experimental results show that models trained with HyperFace achieve state-of-the-art performance in training face recognition using synthetic datasets.
Face Reconstruction from Face Embeddings using Adapter to a Face Foundation Model
Nov 06, 2024



Face recognition systems extract embedding vectors from face images and use these embeddings to verify or identify individuals. Face reconstruction attack (also known as template inversion) refers to reconstructing face images from face embeddings and using the reconstructed face image to enter a face recognition system. In this paper, we propose to use a face foundation model to reconstruct face images from the embeddings of a blackbox face recognition model. The foundation model is trained with 42M images to generate face images from the facial embeddings of a fixed face recognition model. We propose to use an adapter to translate target embeddings into the embedding space of the foundation model. The generated images are evaluated on different face recognition models and different datasets, demonstrating the effectiveness of our method to translate embeddings of different face recognition models. We also evaluate the transferability of reconstructed face images when attacking different face recognition models. Our experimental results show that our reconstructed face images outperform previous reconstruction attacks against face recognition models.
Unveiling Synthetic Faces: How Synthetic Datasets Can Expose Real Identities
Oct 31, 2024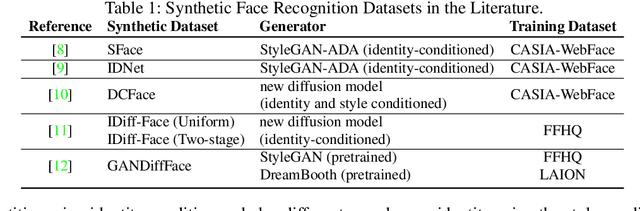



Synthetic data generation is gaining increasing popularity in different computer vision applications. Existing state-of-the-art face recognition models are trained using large-scale face datasets, which are crawled from the Internet and raise privacy and ethical concerns. To address such concerns, several works have proposed generating synthetic face datasets to train face recognition models. However, these methods depend on generative models, which are trained on real face images. In this work, we design a simple yet effective membership inference attack to systematically study if any of the existing synthetic face recognition datasets leak any information from the real data used to train the generator model. We provide an extensive study on 6 state-of-the-art synthetic face recognition datasets, and show that in all these synthetic datasets, several samples from the original real dataset are leaked. To our knowledge, this paper is the first work which shows the leakage from training data of generator models into the generated synthetic face recognition datasets. Our study demonstrates privacy pitfalls in synthetic face recognition datasets and paves the way for future studies on generating responsible synthetic face datasets.
Evaluating the Effectiveness of Attack-Agnostic Features for Morphing Attack Detection
Oct 22, 2024



Morphing attacks have diversified significantly over the past years, with new methods based on generative adversarial networks (GANs) and diffusion models posing substantial threats to face recognition systems. Recent research has demonstrated the effectiveness of features extracted from large vision models pretrained on bonafide data only (attack-agnostic features) for detecting deep generative images. Building on this, we investigate the potential of these image representations for morphing attack detection (MAD). We develop supervised detectors by training a simple binary linear SVM on the extracted features and one-class detectors by modeling the distribution of bonafide features with a Gaussian Mixture Model (GMM). Our method is evaluated across a comprehensive set of attacks and various scenarios, including generalization to unseen attacks, different source datasets, and print-scan data. Our results indicate that attack-agnostic features can effectively detect morphing attacks, outperforming traditional supervised and one-class detectors from the literature in most scenarios. Additionally, we provide insights into the strengths and limitations of each considered representation and discuss potential future research directions to further enhance the robustness and generalizability of our approach.
Score Normalization for Demographic Fairness in Face Recognition
Jul 19, 2024



Fair biometric algorithms have similar verification performance across different demographic groups given a single decision threshold. Unfortunately, for state-of-the-art face recognition networks, score distributions differ between demographics. Contrary to work that tries to align those distributions by extra training or fine-tuning, we solely focus on score post-processing methods. As proved, well-known sample-centered score normalization techniques, Z-norm and T-norm, do not improve fairness for high-security operating points. Thus, we extend the standard Z/T-norm to integrate demographic information in normalization. Additionally, we investigate several possibilities to incorporate cohort similarities for both genuine and impostor pairs per demographic to improve fairness across different operating points. We run experiments on two datasets with different demographics (gender and ethnicity) and show that our techniques generally improve the overall fairness of five state-of-the-art pre-trained face recognition networks, without downgrading verification performance. We also indicate that an equal contribution of False Match Rate (FMR) and False Non-Match Rate (FNMR) in fairness evaluation is required for the highest gains. Code and protocols are available.