 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHOST: Gaussian Hypothesis Open-Set Technique
Feb 05, 2025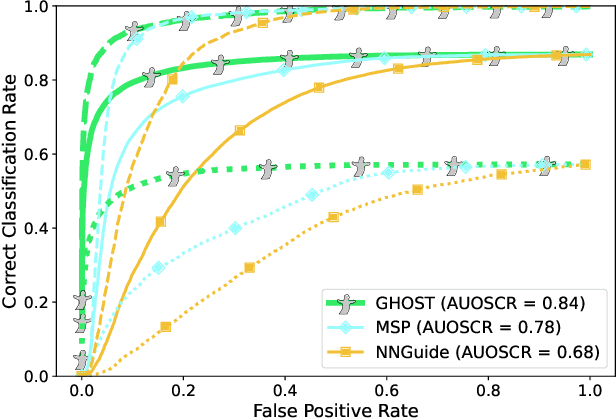

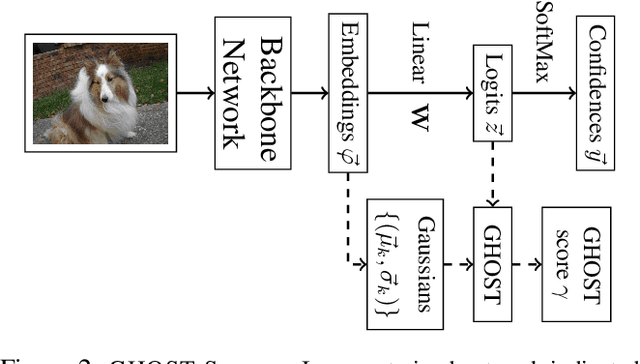
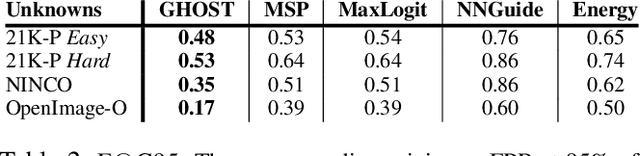
Evaluations of large-scale recognition methods typically focus on overall performance. While this approach is common, it often fails to provide insights into performance across individual classes, which can lead to fairness issues and misrepresentation. Addressing these gaps is crucial for accurately assessing how well methods handle novel or unseen classes and ensuring a fair evaluation. To address fairness in Open-Set Recognition (OSR), we demonstrate that per-class performance can vary dramatically. We introduce Gaussian Hypothesis Open Set Technique (GHOST), a novel hyperparameter-free algorithm that models deep features using class-wise multivariate Gaussian distributions with diagonal covariance matrices. We apply Z-score normalization to logits to mitigate the impact of feature magnitudes that deviate from the model's expectations, thereby reducing the likelihood of the network assigning a high score to an unknown sample. We evaluate GHOST across multiple ImageNet-1K pre-trained deep networks and test it with four different unknown datasets. Using standard metrics such as AUOSCR, AUROC and FPR95, we achieve statistically significant improvements, advancing the state-of-the-art in large-scale OSR. Source code is provided online.
Quo Vadis RankList-based System in Face Recognition?
Oct 02, 2024
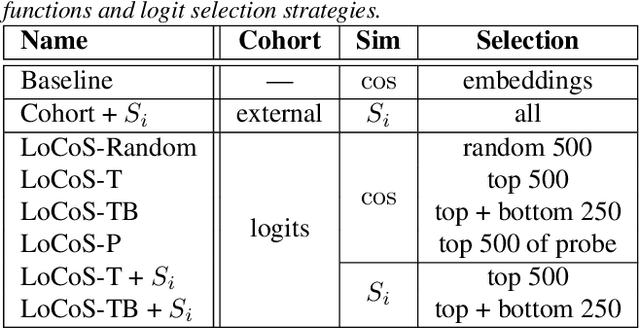

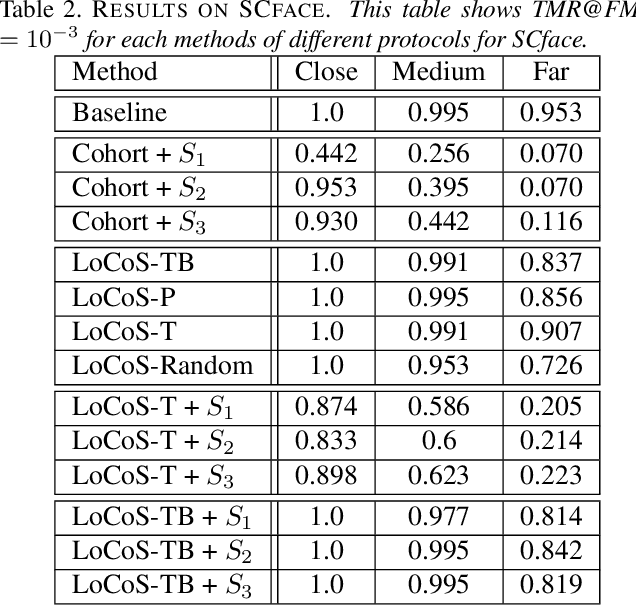
Face recognition in the wild has gained a lot of focus in the last few years, and many face recognition models are designed to verify faces in medium-quality images. Especially due to the availability of large training datasets with similar conditions, deep face recognition models perform exceptionally well in such tasks. However, in other tasks where substantially less training data is available, such methods struggle, especially when required to compare high-quality enrollment images with low-quality probes. On the other hand, traditional RankList-based methods have been developed that compare faces indirectly by comparing to cohort faces with similar conditions. In this paper, we revisit these RankList methods and extend them to use the logits of the state-of-the-art DaliFace network, instead of an external cohort. We show that through a reasonable Logit-Cohort Selection (LoCoS) the performance of RankList-based functions can be improved drastically. Experiments on two challenging face recognition datasets not only demonstrate the enhanced performance of our proposed method but also set the stage for future advancements in handling diverse image qualities.
Watchlist Challenge: 3rd Open-set Face Detection and Identification
Sep 11, 2024In the current landscape of biometrics and surveillance, the ability to accurately recognize faces in uncontrolled settings is paramount. The Watchlist Challenge addresses this critical need by focusing on face detection and open-set identification in real-world surveillance scenarios. This paper presents a comprehensive evaluation of participating algorithms, using the enhanced UnConstrained College Students (UCCS) dataset with new evaluation protocols. In total, four participants submitted four face detection and nine open-set face recognition systems. The evaluation demonstrates that while detection capabilities are generally robust, closed-set identification performance varies significantly, with models pre-trained on large-scale datasets showing superior performance. However, open-set scenarios require further improvement, especially at higher true positive identification rates, i.e., lower thresholds.
AdvSecureNet: A Python Toolkit for Adversarial Machine Learning
Sep 04, 2024

Machine learning models are vulnerable to adversarial attacks. Several tools have been developed to research these vulnerabilities, but they often lack comprehensive features and flexibility. We introduce AdvSecureNet, a PyTorch based toolkit for adversarial machine learning that is the first to natively support multi-GPU setups for attacks, defenses, and evaluation. It is the first toolkit that supports both CLI and API interfaces and external YAML configuration files to enhance versatility and reproducibility. The toolkit includes multiple attacks, defenses and evaluation metrics. Rigiorous software engineering practices are followed to ensure high code quality and maintainability. The project is available as an open-source project on GitHub at https://github.com/melihcatal/advsecurenet and installable via PyPI.
Refining Tuberculosis Detection in CXR Imaging: Addressing Bias in Deep Neural Networks via Interpretability
Jul 19, 2024


Automatic classification of active tuberculosis from chest X-ray images has the potential to save lives, especially in low- and mid-income countries where skilled human experts can be scarce. Given the lack of available labeled data to train such systems and the unbalanced nature of publicly available datasets, we argue that the reliability of deep learning models is limited, even if they can be shown to obtain perfect classification accuracy on the test data. One way of evaluating the reliability of such systems is to ensure that models use the same regions of input images for predictions as medical experts would. In this paper, we show that pre-training a deep neural network on a large-scale proxy task, as well as using mixed objective optimization network (MOON), a technique to balance different classes during pre-training and fine-tuning, can improve the alignment of decision foundations between models and experts, as compared to a model directly trained on the target dataset. At the same time, these approaches keep perfect classification accuracy according to the area under the receiver operating characteristic curve (AUROC) on the test set, and improve generalization on an independent, unseen dataset. For the purpose of reproducibility, our source code is made available online.
Score Normalization for Demographic Fairness in Face Recognition
Jul 19, 2024



Fair biometric algorithms have similar verification performance across different demographic groups given a single decision threshold. Unfortunately, for state-of-the-art face recognition networks, score distributions differ between demographics. Contrary to work that tries to align those distributions by extra training or fine-tuning, we solely focus on score post-processing methods. As proved, well-known sample-centered score normalization techniques, Z-norm and T-norm, do not improve fairness for high-security operating points. Thus, we extend the standard Z/T-norm to integrate demographic information in normalization. Additionally, we investigate several possibilities to incorporate cohort similarities for both genuine and impostor pairs per demographic to improve fairness across different operating points. We run experiments on two datasets with different demographics (gender and ethnicity) and show that our techniques generally improve the overall fairness of five state-of-the-art pre-trained face recognition networks, without downgrading verification performance. We also indicate that an equal contribution of False Match Rate (FMR) and False Non-Match Rate (FNMR) in fairness evaluation is required for the highest gains. Code and protocols are available.
Large-Scale Evaluation of Open-Set Image Classification Techniques
Jun 13, 2024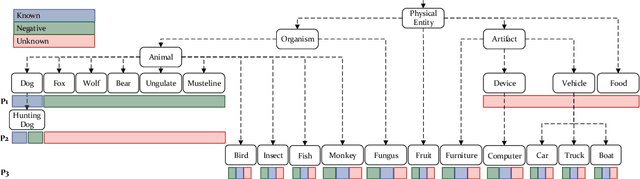
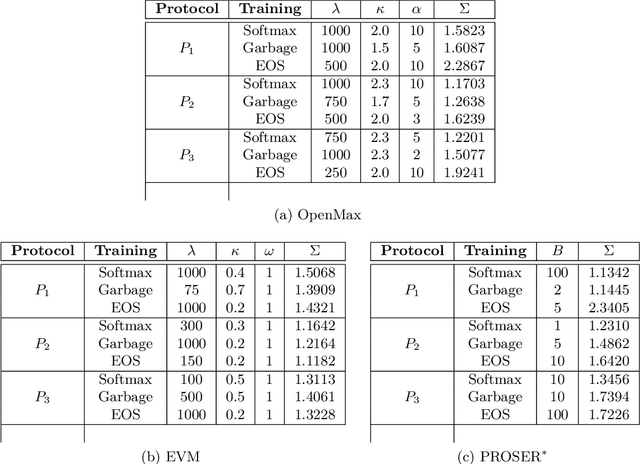

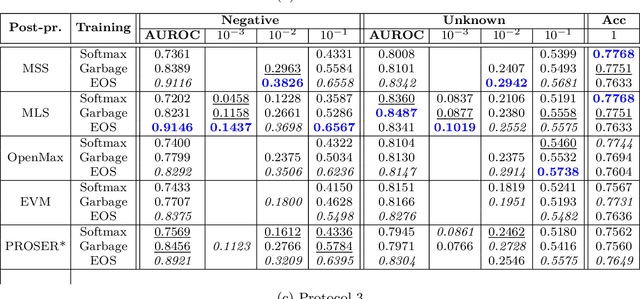
The goal for classification is to correctly assign labels to unseen samples. However, most methods misclassify samples with unseen labels and assign them to one of the known classes. Open-Set Classification (OSC) algorithms aim to maximize both closed and open-set recognition capabilities. Recent studies showed the utility of such algorithms on small-scale data sets, but limited experimentation makes it difficult to assess their performances in real-world problems. Here, we provide a comprehensive comparison of various OSC algorithms, including training-based (SoftMax, Garbage, EOS) and post-processing methods (Maximum SoftMax Scores, Maximum Logit Scores, OpenMax, EVM, PROSER), the latter are applied on features from the former. We perform our evaluation on three large-scale protocols that mimic real-world challenges, where we train on known and negative open-set samples, and test on known and unknown instances. Our results show that EOS helps to improve performance of almost all post-processing algorithms. Particularly, OpenMax and PROSER are able to exploit better-trained networks, demonstrating the utility of hybrid models. However, while most algorithms work well on negative test samples -- samples of open-set classes seen during training -- they tend to perform poorly when tested on samples of previously unseen unknown classes, especially in challenging conditions.
Biased Binary Attribute Classifiers Ignore the Majority Classes
Mar 21, 2024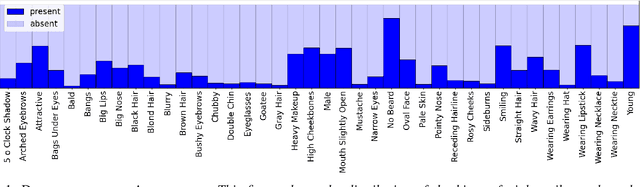
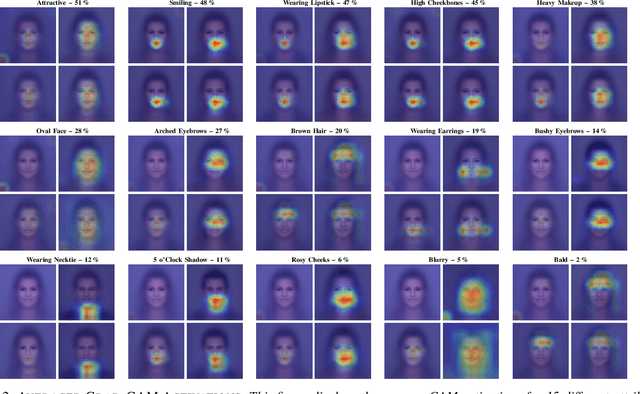
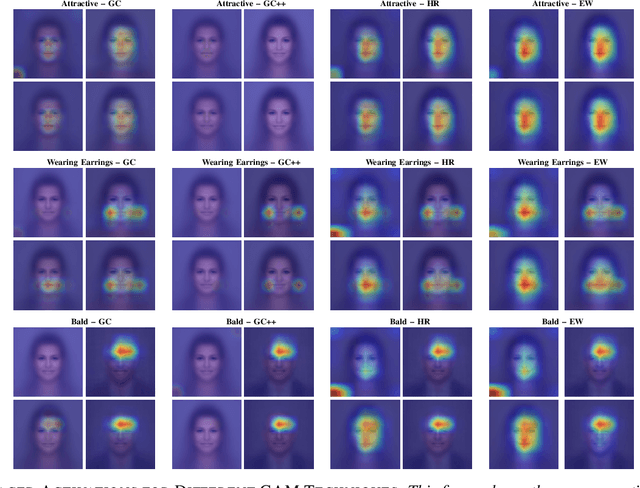

To visualize the regions of interest that classifiers base their decisions on, different Class Activation Mapping (CAM) methods have been developed. However, all of these techniques target categorical classifiers only, though most real-world tasks are binary classification. In this paper, we extend gradient-based CAM techniques to work with binary classifiers and visualize the active regions for binary facial attribute classifiers. When training an unbalanced binary classifier on an imbalanced dataset, it is well-known that the majority class, i.e. the class with many training samples, is mostly predicted much better than minority class with few training instances. In our experiments on the CelebA dataset, we verify these results, when training an unbalanced classifier to extract 40 facial attributes simultaneously. One would expect that the biased classifier has learned to extract features mainly for the majority classes and that the proportional energy of the activations mainly reside in certain specific regions of the image where the attribute is located. However, we find very little regular activation for samples of majority classes, while the active regions for minority classes seem mostly reasonable and overlap with our expectations. These results suggest that biased classifiers mainly rely on bias activation for majority classes. When training a balanced classifier on the imbalanced data by employing attribute-specific class weights, majority and minority classes are classified similarly well and show expected activations for almost all attributes
Open-Set Face Recognition with Maximal Entropy and Objectosphere Loss
Nov 01, 2023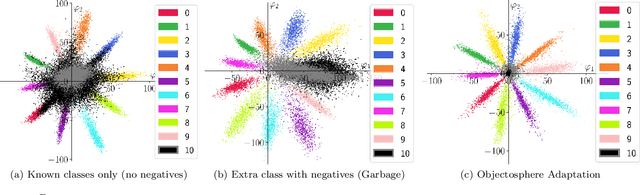
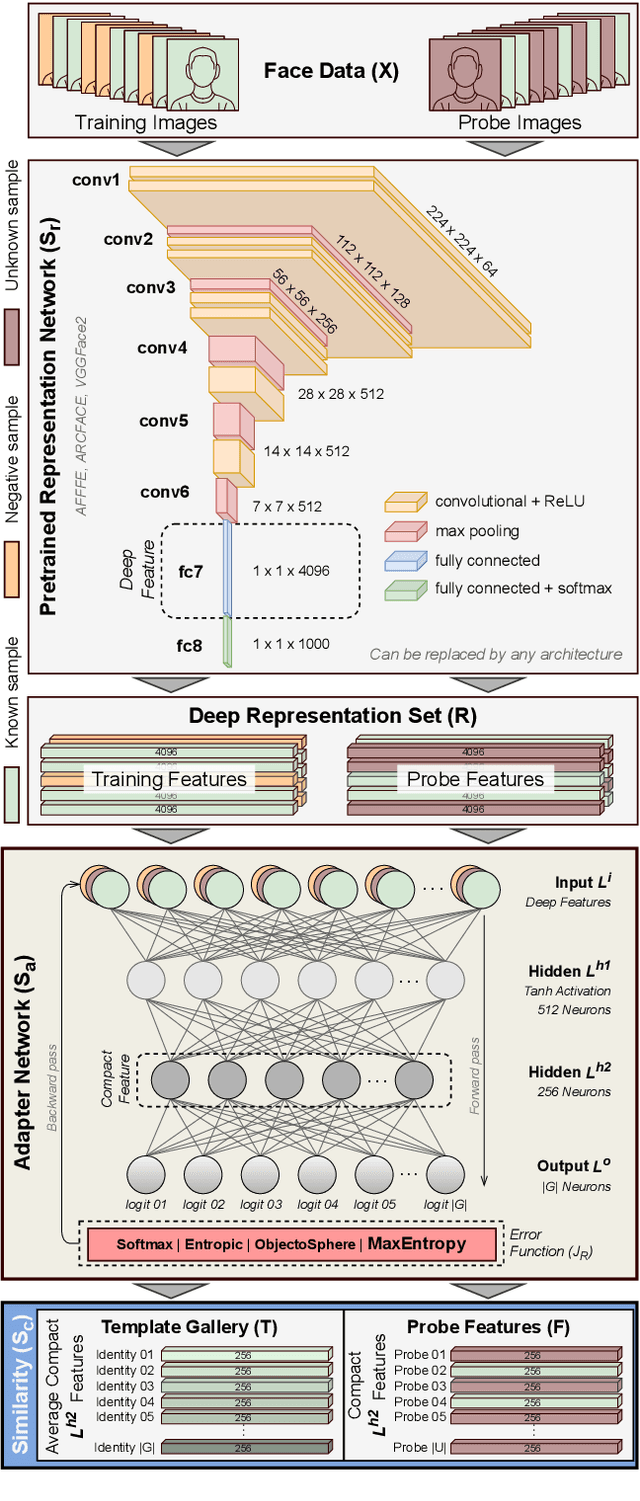
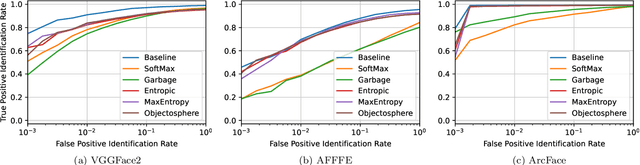
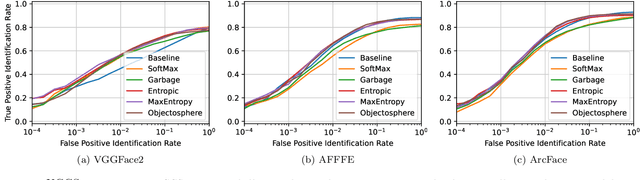
Open-set face recognition characterizes a scenario where unknown individuals, unseen during the training and enrollment stages, appear on operation time. This work concentrates on watchlists, an open-set task that is expected to operate at a low False Positive Identification Rate and generally includes only a few enrollment samples per identity. We introduce a compact adapter network that benefits from additional negative face images when combined with distinct cost functions, such as Objectosphere Loss (OS) and the proposed Maximal Entropy Loss (MEL). MEL modifies the traditional Cross-Entropy loss in favor of increasing the entropy for negative samples and attaches a penalty to known target classes in pursuance of gallery specialization. The proposed approach adopts pre-trained deep neural networks (DNNs) for face recognition as feature extractors. Then, the adapter network takes deep feature representations and acts as a substitute for the output layer of the pre-trained DNN in exchange for an agile domain adaptation. Promising results have been achieved following open-set protocols for three different datasets: LFW, IJB-C, and UCCS as well as state-of-the-art performance when supplementary negative data is properly selected to fine-tune the adapter network.
Open-set Face Recognition with Neural Ensemble, Maximal Entropy Loss and Feature Augmentation
Aug 23, 2023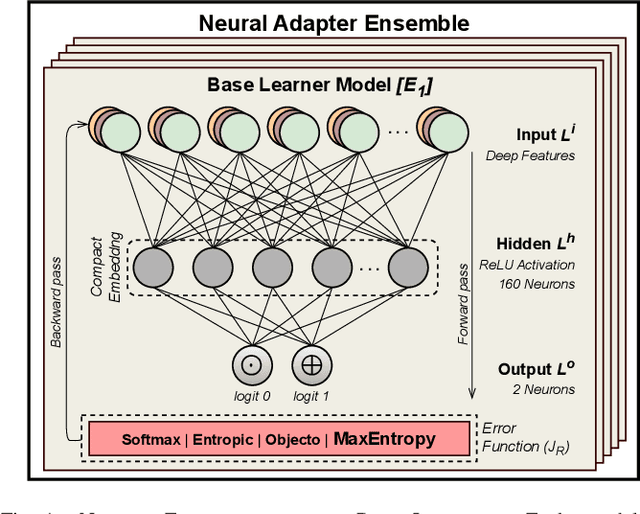
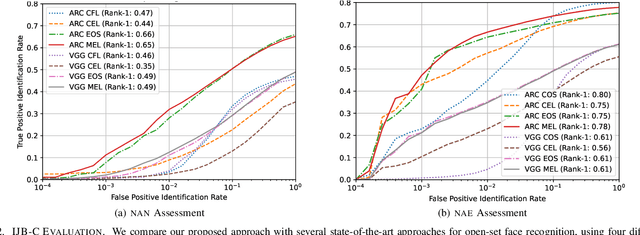

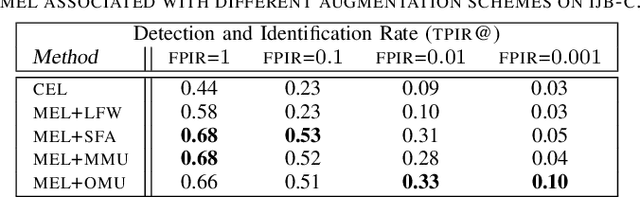
Open-set face recognition refers to a scenario in which biometric systems have incomplete knowledge of all existing subjects. Therefore, they are expected to prevent face samples of unregistered subjects from being identified as previously enrolled identities. This watchlist context adds an arduous requirement that calls for the dismissal of irrelevant faces by focusing mainly on subjects of interest. As a response, this work introduces a novel method that associates an ensemble of compact neural networks with a margin-based cost function that explores additional samples. Supplementary negative samples can be obtained from external databases or synthetically built at the representation level in training time with a new mix-up feature augmentation approach. Deep neural networks pre-trained on large face datasets serve as the preliminary feature extraction module. We carry out experiments on well-known LFW and IJB-C datasets where results show that the approach is able to boost closed and open-set identification rates.