 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Objective Evaluation Framework for Analyzing Utility-Fairness Trade-Offs in Machine Learning Systems
Mar 14, 2025The evaluation of fairness models in Machine Learning involves complex challenges, such as defining appropriate metrics, balancing trade-offs between utility and fairness, and there are still gaps in this stage. This work presents a novel multi-objective evaluation framework that enables the analysis of utility-fairness trade-offs in Machine Learning systems. The framework was developed using criteria from Multi-Objective Optimization that collect comprehensive information regarding this complex evaluation task. The assessment of multiple Machine Learning systems is summarized, both quantitatively and qualitatively, in a straightforward manner through a radar chart and a measurement table encompassing various aspects such as convergence, system capacity, and diversity. The framework's compact representation of performance facilitates the comparative analysis of different Machine Learning strategies for decision-makers, in real-world applications, with single or multiple fairness requirements. The framework is model-agnostic and flexible to be adapted to any kind of Machine Learning systems, that is, black- or white-box, any kind and quantity of evaluation metrics, including multidimensional fairness criteria. The functionality and effectiveness of the proposed framework is shown with different simulations, and an empirical study conducted on a real-world dataset with various Machine Learning systems.
Fair Foundation Models for Medical Image Analysis: Challenges and Perspectives
Feb 24, 2025Ensuring equitable Artificial Intelligence (AI) in healthcare demands systems that make unbiased decisions across all demographic groups, bridging technical innovation with ethical principles. Foundation Models (FMs), trained on vast datasets through self-supervised learning, enable efficient adaptation across medical imaging tasks while reducing dependency on labeled data. These models demonstrate potential for enhancing fairness, though significant challenges remain in achieving consistent performance across demographic groups. Our review indicates that effective bias mitigation in FMs requires systematic interventions throughout all stages of development. While previous approaches focused primarily on model-level bias mitigation, our analysis reveals that fairness in FMs requires integrated interventions throughout the development pipeline, from data documentation to deployment protocols. This comprehensive framework advances current knowledge by demonstrating how systematic bias mitigation, combined with policy engagement, can effectively address both technical and institutional barriers to equitable AI in healthcare. The development of equitable FMs represents a critical step toward democratizing advanced healthcare technologies, particularly for underserved populations and regions with limited medical infrastructure and computational resources.
Does Data-Efficient Generalization Exacerbate Bias in Foundation Models?
Sep 02, 2024


Foundation models have emerged as robust models with label efficiency in diverse domains. In medical imaging, these models contribute to the advancement of medical diagnoses due to the difficulty in obtaining labeled data. However, it is unclear whether using a large amount of unlabeled data, biased by the presence of sensitive attributes during pre-training, influences the fairness of the model. This research examines the bias in the Foundation model (RetFound) when it is applied to fine-tune the Brazilian Multilabel Ophthalmological Dataset (BRSET), which has a different population than the pre-training dataset. The model evaluation, in comparison with supervised learning, shows that the Foundation Model has the potential to reduce the gap between the maximum AUC and minimum AUC evaluations across gender and age groups. However, in a data-efficient generalization, the model increases the bias when the data amount decreases. These findings suggest that when deploying a Foundation Model in real-life scenarios with limited data, the possibility of fairness issues should be considered.
Using Backbone Foundation Model for Evaluating Fairness in Chest Radiography Without Demographic Data
Aug 28, 2024Ensuring consistent performance across diverse populations and incorporating fairness into machine learning models are crucial for advancing medical image diagnostics and promoting equitable healthcare. However, many databases do not provide protected attributes or contain unbalanced representations of demographic groups, complicating the evaluation of model performance across different demographics and the application of bias mitigation techniques that rely on these attributes. This study aims to investigate the effectiveness of using the backbone of Foundation Models as an embedding extractor for creating groups that represent protected attributes, such as gender and age. We propose utilizing these groups in different stages of bias mitigation, including pre-processing, in-processing, and evaluation. Using databases in and out-of-distribution scenarios, it is possible to identify that the method can create groups that represent gender in both databases and reduce in 4.44% the difference between the gender attribute in-distribution and 6.16% in out-of-distribution. However, the model lacks robustness in handling age attributes, underscoring the need for more fundamentally fair and robust Foundation models. These findings suggest a role in promoting fairness assessment in scenarios where we lack knowledge of attributes, contributing to the development of more equitable medical diagnostics.
Refining Tuberculosis Detection in CXR Imaging: Addressing Bias in Deep Neural Networks via Interpretability
Jul 19, 2024


Automatic classification of active tuberculosis from chest X-ray images has the potential to save lives, especially in low- and mid-income countries where skilled human experts can be scarce. Given the lack of available labeled data to train such systems and the unbalanced nature of publicly available datasets, we argue that the reliability of deep learning models is limited, even if they can be shown to obtain perfect classification accuracy on the test data. One way of evaluating the reliability of such systems is to ensure that models use the same regions of input images for predictions as medical experts would. In this paper, we show that pre-training a deep neural network on a large-scale proxy task, as well as using mixed objective optimization network (MOON), a technique to balance different classes during pre-training and fine-tuning, can improve the alignment of decision foundations between models and experts, as compared to a model directly trained on the target dataset. At the same time, these approaches keep perfect classification accuracy according to the area under the receiver operating characteristic curve (AUROC) on the test set, and improve generalization on an independent, unseen dataset. For the purpose of reproducibility, our source code is made available online.
The Little W-Net That Could: State-of-the-Art Retinal Vessel Segmentation with Minimalistic Models
Sep 03, 2020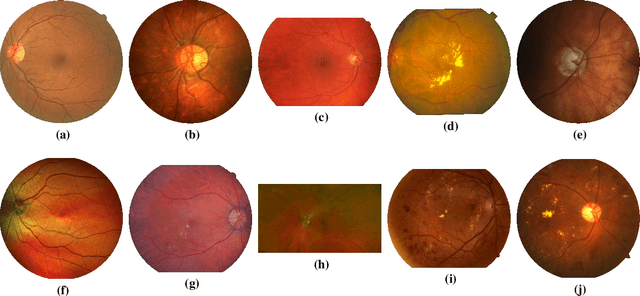
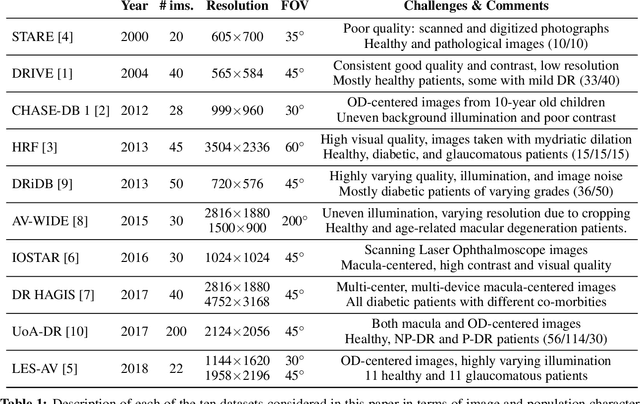
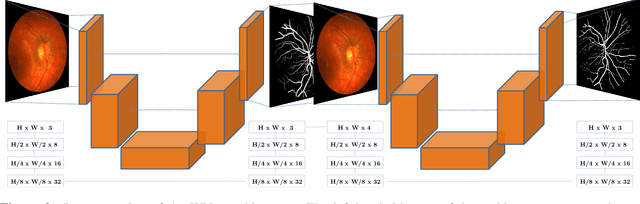
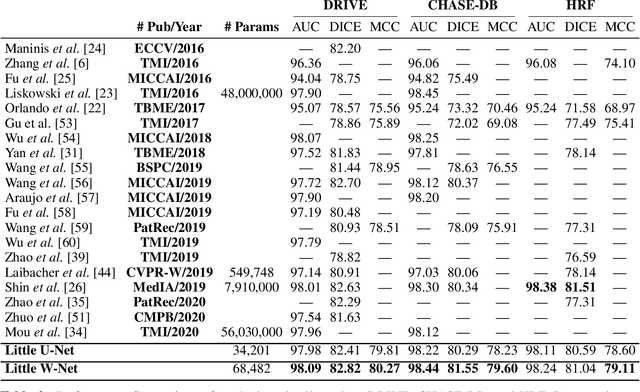
The segmentation of the retinal vasculature from eye fundus images represents one of the most fundamental tasks in retinal image analysis. Over recent years, increasingly complex approaches based on sophisticated Convolutional Neural Network architectures have been slowly pushing performance on well-established benchmark datasets. In this paper, we take a step back and analyze the real need of such complexity. Specifically, we demonstrate that a minimalistic version of a standard U-Net with several orders of magnitude less parameters, carefully trained and rigorously evaluated, closely approximates the performance of current best techniques. In addition, we propose a simple extension, dubbed W-Net, which reaches outstanding performance on several popular datasets, still using orders of magnitude less learnable weights than any previously published approach. Furthermore, we provide the most comprehensive cross-dataset performance analysis to date, involving up to 10 different databases. Our analysis demonstrates that the retinal vessel segmentation problem is far from solved when considering test images that differ substantially from the training data, and that this task represents an ideal scenario for the exploration of domain adaptation techniques. In this context, we experiment with a simple self-labeling strategy that allows us to moderately enhance cross-dataset performance, indicating that there is still much room for improvement in this area. Finally, we also test our approach on the Artery/Vein segmentation problem, where we again achieve results well-aligned with the state-of-the-art, at a fraction of the model complexity in recent literature. All the code to reproduce the results in this paper is released.
On the Evaluation and Real-World Usage Scenarios of Deep Vessel Segmentation for Funduscopy
Sep 12, 2019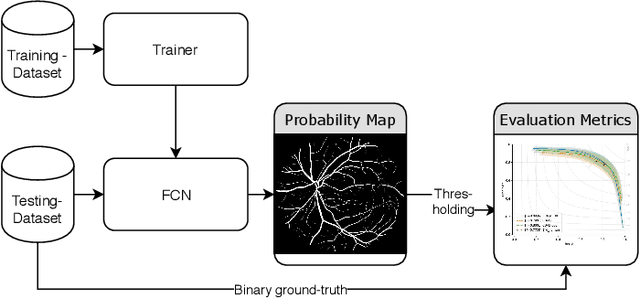


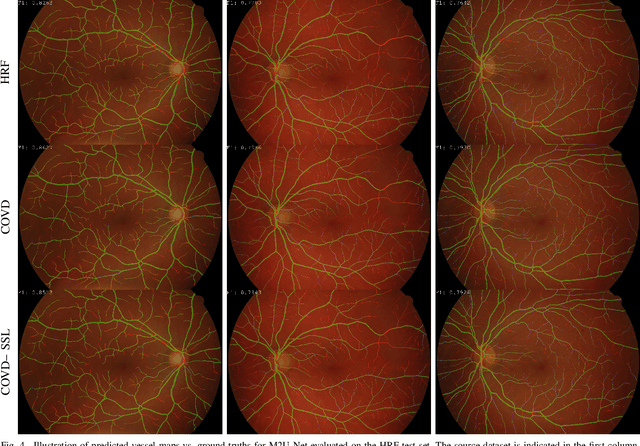
We identify and address three research gaps in the field of vessel segmentation for funduscopy. The first focuses on the task of inference on high-resolution fundus images for which only a limited set of ground-truth data is publicly available. Notably, we highlight that simple rescaling and padding or cropping of lower resolution datasets is surprisingly effective. Additionally we explore the effectiveness of semi-supervised learning for better domain adaptation. Our results show competitive performance on a set of common public retinal vessel datasets using a small and light-weight neural network. For HRF, the only very high-resolution dataset currently available, we reach new state-of-the-art performance by solely relying on training images from lower-resolution datasets. The second topic concerns evaluation metrics. We investigate the variability of the F1-score on the existing datasets and report results for recent SOTA architectures. Our evaluation show that most SOTA results are actually comparable to each other in performance. Last, we address the issue of reproducibility by open-sourcing our complete pipeline.
A Reproducible Study on Remote Heart Rate Measurement
Sep 04, 2017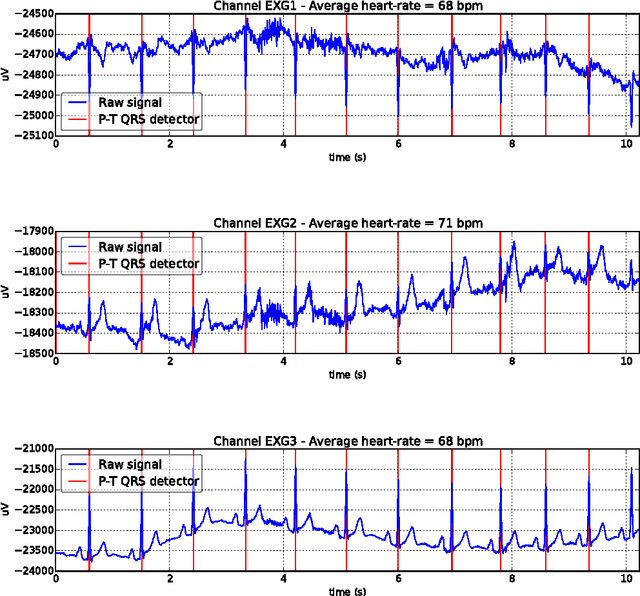


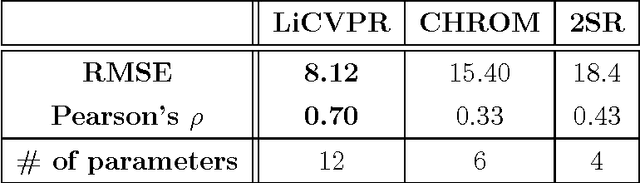
This paper studies the problem of reproducible research in remote photoplethysmography (rPPG). Most of the work published in this domain is assessed on privately-owned databases, making it difficult to evaluate proposed algorithms in a standard and principled manner. As a consequence, we present a new, publicly available database containing a relatively large number of subjects recorded under two different lighting conditions. Also, three state-of-the-art rPPG algorithms from the literature were selected, implemented and released as open source free software. After a thorough, unbiased experimental evaluation in various settings, it is shown that none of the selected algorithms is precise enough to be used in a real-world scenario.