 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Transferability of a Foundation Model for Fundus Images: Application to Hypertensive Retinopathy
Jan 27, 2024Using deep learning models pre-trained on Imagenet is the traditional solution for medical image classification to deal with data scarcity. Nevertheless, relevant literature supports that this strategy may offer limited gains due to the high dissimilarity between domains. Currently, the paradigm of adapting domain-specialized foundation models is proving to be a promising alternative. However, how to perform such knowledge transfer, and the benefits and limitations it presents, are under study. The CGI-HRDC challenge for Hypertensive Retinopathy diagnosis on fundus images introduces an appealing opportunity to evaluate the transferability of a recently released vision-language foundation model of the retina, FLAIR. In this work, we explore the potential of using FLAIR features as starting point for fundus image classification, and we compare its performance with regard to Imagenet initialization on two popular transfer learning methods: Linear Probing (LP) and Fine-Tuning (FP). Our empirical observations suggest that, in any case, the use of the traditional strategy provides performance gains. In contrast, direct transferability from FLAIR model allows gains of 2.5%. When fine-tuning the whole network, the performance gap increases up to 4%. In this case, we show that avoiding feature deterioration via LP initialization of the classifier allows the best re-use of the rich pre-trained features. Although direct transferability using LP still offers limited performance, we believe that foundation models such as FLAIR will drive the evolution of deep-learning-based fundus image analysis.
A Foundation LAnguage-Image model of the Retina : Encoding expert knowledge in text supervision
Aug 15, 2023Foundation vision-language models are currently transforming computer vision, and are on the rise in medical imaging fueled by their very promising generalization capabilities. However, the initial attempts to transfer this new paradigm to medical imaging have shown less impressive performances than those observed in other domains, due to the significant domain shift and the complex, expert domain knowledge inherent to medical-imaging tasks. Motivated by the need for domain-expert foundation models, we present FLAIR, a pre-trained vision-language model for universal retinal fundus image understanding. To this end, we compiled 37 open-access, mostly categorical fundus imaging datasets from various sources, with up to 97 different target conditions and 284,660 images. We integrate the expert's domain knowledge in the form of descriptive textual prompts, during both pre-training and zero-shot inference, enhancing the less-informative categorical supervision of the data. Such a textual expert's knowledge, which we compiled from the relevant clinical literature and community standards, describes the fine-grained features of the pathologies as well as the hierarchies and dependencies between them. We report comprehensive evaluations, which illustrate the benefit of integrating expert knowledge and the strong generalization capabilities of FLAIR under difficult scenarios with domain shifts or unseen categories. When adapted with a lightweight linear probe, FLAIR outperforms fully-trained, dataset-focused models, more so in the few-shot regimes. Interestingly, FLAIR outperforms by a large margin more generalist, larger-scale image-language models, which emphasizes the potential of embedding experts' domain knowledge and the limitations of generalist models in medical imaging.
Cost-Sensitive Regularization for Diabetic Retinopathy Grading from Eye Fundus Images
Oct 01, 2020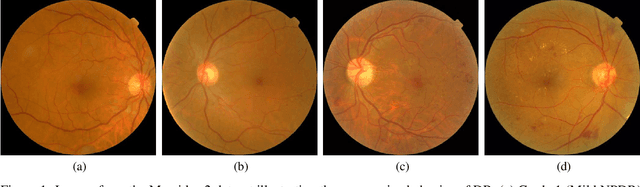
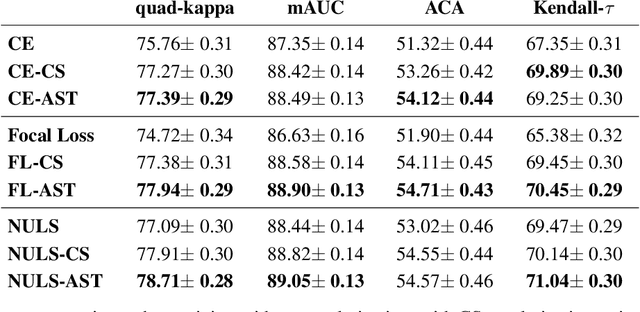

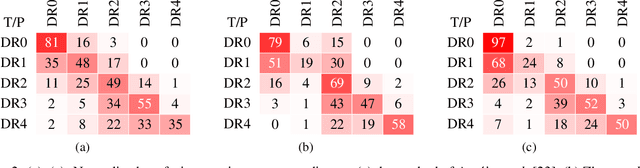
Assessing the degree of disease severity in biomedical images is a task similar to standard classification but constrained by an underlying structure in the label space. Such a structure reflects the monotonic relationship between different disease grades. In this paper, we propose a straightforward approach to enforce this constraint for the task of predicting Diabetic Retinopathy (DR) severity from eye fundus images based on the well-known notion of Cost-Sensitive classification. We expand standard classification losses with an extra term that acts as a regularizer, imposing greater penalties on predicted grades when they are farther away from the true grade associated to a particular image. Furthermore, we show how to adapt our method to the modelling of label noise in each of the sub-problems associated to DR grading, an approach we refer to as Atomic Sub-Task modeling. This yields models that can implicitly take into account the inherent noise present in DR grade annotations. Our experimental analysis on several public datasets reveals that, when a standard Convolutional Neural Network is trained using this simple strategy, improvements of 3-5\% of quadratic-weighted kappa scores can be achieved at a negligible computational cost. Code to reproduce our results is released at https://github.com/agaldran/cost_sensitive_loss_classification.
The Little W-Net That Could: State-of-the-Art Retinal Vessel Segmentation with Minimalistic Models
Sep 03, 2020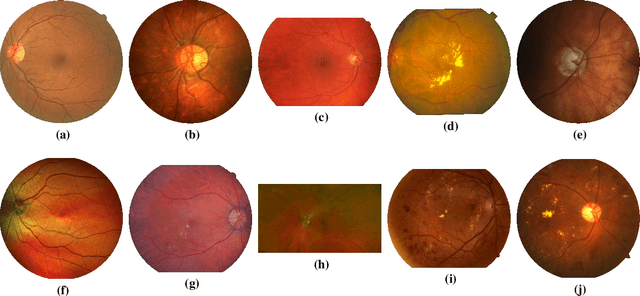
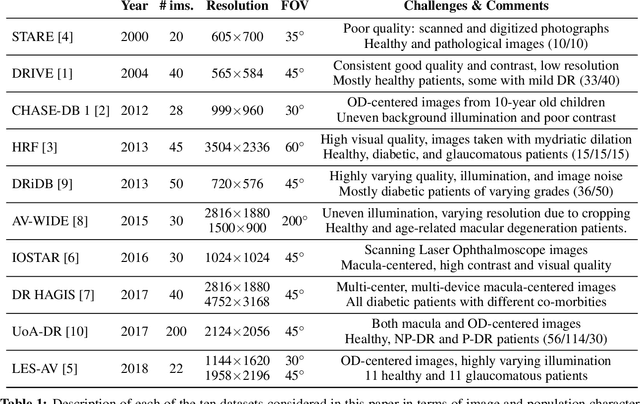
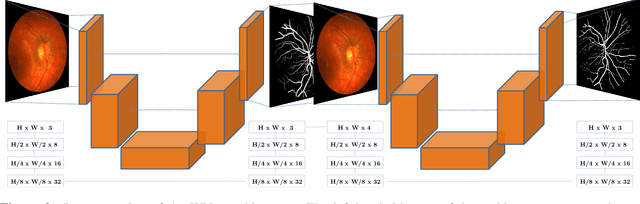
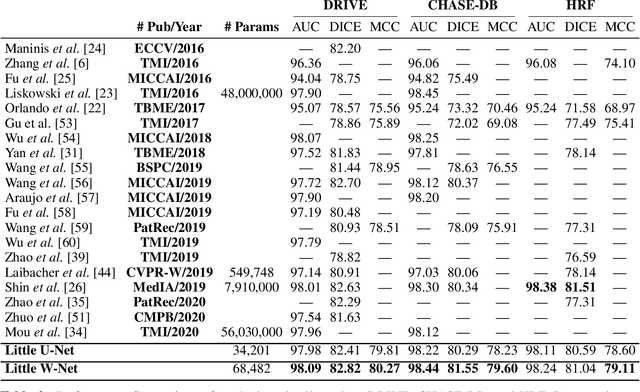
The segmentation of the retinal vasculature from eye fundus images represents one of the most fundamental tasks in retinal image analysis. Over recent years, increasingly complex approaches based on sophisticated Convolutional Neural Network architectures have been slowly pushing performance on well-established benchmark datasets. In this paper, we take a step back and analyze the real need of such complexity. Specifically, we demonstrate that a minimalistic version of a standard U-Net with several orders of magnitude less parameters, carefully trained and rigorously evaluated, closely approximates the performance of current best techniques. In addition, we propose a simple extension, dubbed W-Net, which reaches outstanding performance on several popular datasets, still using orders of magnitude less learnable weights than any previously published approach. Furthermore, we provide the most comprehensive cross-dataset performance analysis to date, involving up to 10 different databases. Our analysis demonstrates that the retinal vessel segmentation problem is far from solved when considering test images that differ substantially from the training data, and that this task represents an ideal scenario for the exploration of domain adaptation techniques. In this context, we experiment with a simple self-labeling strategy that allows us to moderately enhance cross-dataset performance, indicating that there is still much room for improvement in this area. Finally, we also test our approach on the Artery/Vein segmentation problem, where we again achieve results well-aligned with the state-of-the-art, at a fraction of the model complexity in recent literature. All the code to reproduce the results in this paper is released.