 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Transferability of a Foundation Model for Fundus Images: Application to Hypertensive Retinopathy
Jan 27, 2024Using deep learning models pre-trained on Imagenet is the traditional solution for medical image classification to deal with data scarcity. Nevertheless, relevant literature supports that this strategy may offer limited gains due to the high dissimilarity between domains. Currently, the paradigm of adapting domain-specialized foundation models is proving to be a promising alternative. However, how to perform such knowledge transfer, and the benefits and limitations it presents, are under study. The CGI-HRDC challenge for Hypertensive Retinopathy diagnosis on fundus images introduces an appealing opportunity to evaluate the transferability of a recently released vision-language foundation model of the retina, FLAIR. In this work, we explore the potential of using FLAIR features as starting point for fundus image classification, and we compare its performance with regard to Imagenet initialization on two popular transfer learning methods: Linear Probing (LP) and Fine-Tuning (FP). Our empirical observations suggest that, in any case, the use of the traditional strategy provides performance gains. In contrast, direct transferability from FLAIR model allows gains of 2.5%. When fine-tuning the whole network, the performance gap increases up to 4%. In this case, we show that avoiding feature deterioration via LP initialization of the classifier allows the best re-use of the rich pre-trained features. Although direct transferability using LP still offers limited performance, we believe that foundation models such as FLAIR will drive the evolution of deep-learning-based fundus image analysis.
A Foundation LAnguage-Image model of the Retina : Encoding expert knowledge in text supervision
Aug 15, 2023Foundation vision-language models are currently transforming computer vision, and are on the rise in medical imaging fueled by their very promising generalization capabilities. However, the initial attempts to transfer this new paradigm to medical imaging have shown less impressive performances than those observed in other domains, due to the significant domain shift and the complex, expert domain knowledge inherent to medical-imaging tasks. Motivated by the need for domain-expert foundation models, we present FLAIR, a pre-trained vision-language model for universal retinal fundus image understanding. To this end, we compiled 37 open-access, mostly categorical fundus imaging datasets from various sources, with up to 97 different target conditions and 284,660 images. We integrate the expert's domain knowledge in the form of descriptive textual prompts, during both pre-training and zero-shot inference, enhancing the less-informative categorical supervision of the data. Such a textual expert's knowledge, which we compiled from the relevant clinical literature and community standards, describes the fine-grained features of the pathologies as well as the hierarchies and dependencies between them. We report comprehensive evaluations, which illustrate the benefit of integrating expert knowledge and the strong generalization capabilities of FLAIR under difficult scenarios with domain shifts or unseen categories. When adapted with a lightweight linear probe, FLAIR outperforms fully-trained, dataset-focused models, more so in the few-shot regimes. Interestingly, FLAIR outperforms by a large margin more generalist, larger-scale image-language models, which emphasizes the potential of embedding experts' domain knowledge and the limitations of generalist models in medical imaging.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
Feb 16, 2022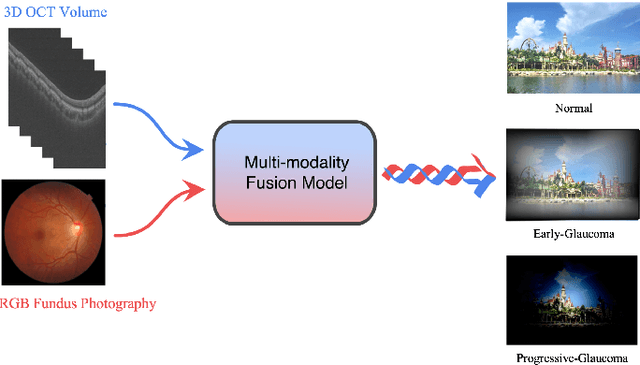
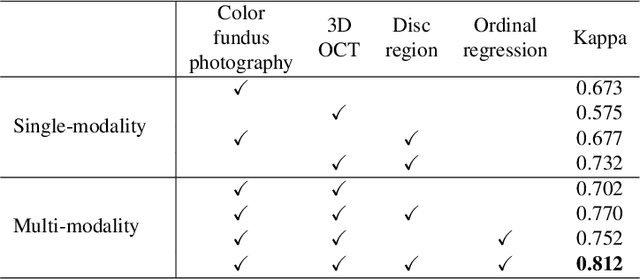
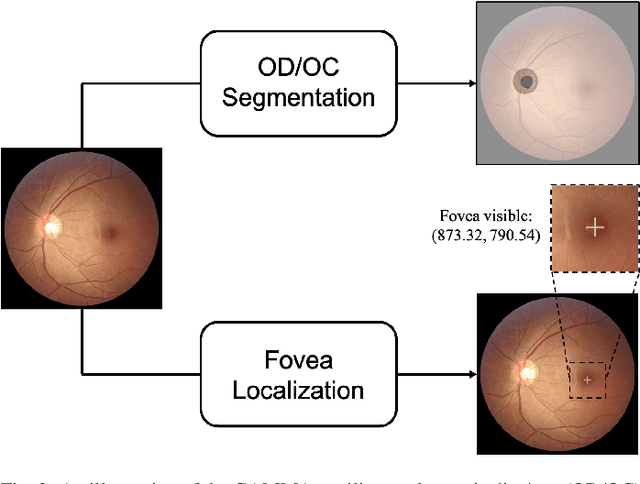
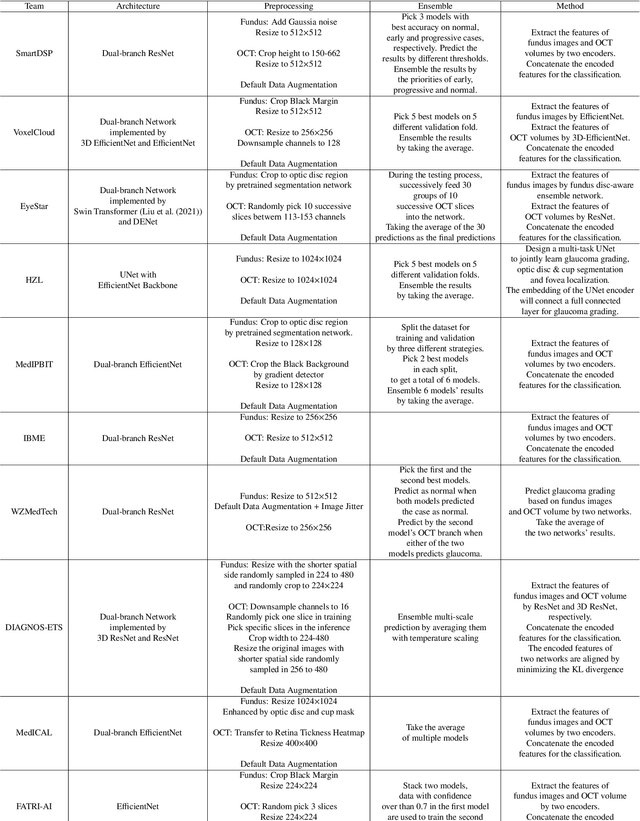
Color fundus photography and Optical Coherence Tomography (OCT) are the two most cost-effective tools for glaucoma screening. Both two modalities of images have prominent biomarkers to indicate glaucoma suspected. Clinically, it is often recommended to take both of the screenings for a more accurate and reliable diagnosis. However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment. Inspired by the success of Retinal Fundus Glaucoma Challenge (REFUGE) we held previously, we set up the Glaucoma grAding from Multi-Modality imAges (GAMMA) Challenge to encourage the development of fundus \& OCT-based glaucoma grading. The primary task of the challenge is to grade glaucoma from both the 2D fundus images and 3D OCT scanning volumes. As part of GAMMA, we have publicly released a glaucoma annotated dataset with both 2D fundus color photography and 3D OCT volumes, which is the first multi-modality dataset for glaucoma grading. In addition, an evaluation framework is also established to evaluate the performance of the submitted methods. During the challenge, 1272 results were submitted, and finally, top-10 teams were selected to the final stage. We analysis their results and summarize their methods in the paper. Since all these teams submitted their source code in the challenge, a detailed ablation study is also conducted to verify the effectiveness of the particular modules proposed. We find many of the proposed techniques are practical for the clinical diagnosis of glaucoma. As the first in-depth study of fundus \& OCT multi-modality glaucoma grading, we believe the GAMMA Challenge will be an essential starting point for future research.
The hidden label-marginal biases of segmentation losses
Apr 18, 2021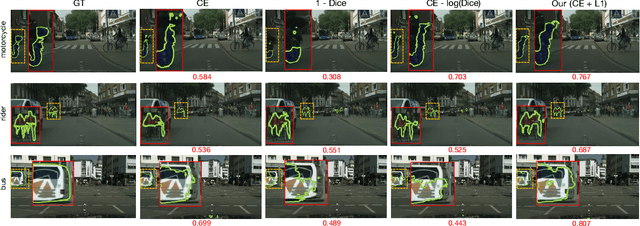
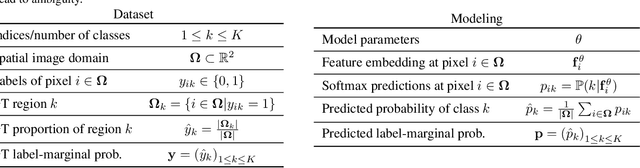
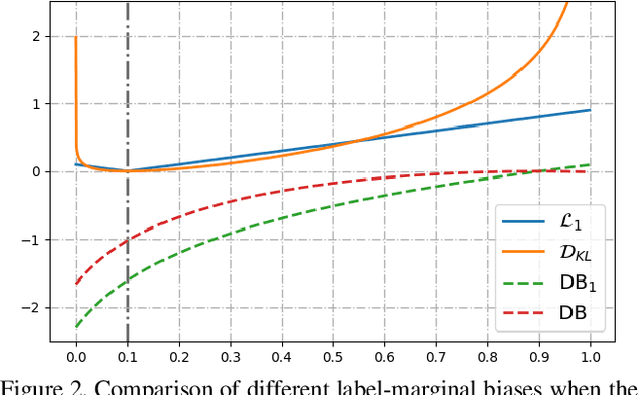
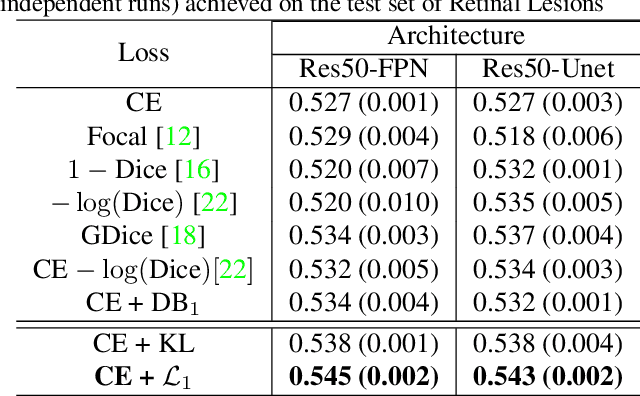
Most segmentation losses are arguably variants of the Cross-Entropy (CE) or Dice loss. In the literature, there is no clear consensus as to which of these losses is a better choice, with varying performances for each across different benchmarks and applications. We develop a theoretical analysis that links these two types of losses, exposing their advantages and weaknesses. First, we explicitly demonstrate that CE and Dice share a much deeper connection than previously thought: CE is an upper bound on both logarithmic and linear Dice losses. Furthermore, we provide an information-theoretic analysis, which highlights hidden label-marginal biases : Dice has an intrinsic bias towards imbalanced solutions, whereas CE implicitly encourages the ground-truth region proportions. Our theoretical results explain the wide experimental evidence in the medical-imaging literature, whereby Dice losses bring improvements for imbalanced segmentation. It also explains why CE dominates natural-image problems with diverse class proportions, in which case Dice might have difficulty adapting to different label-marginal distributions. Based on our theoretical analysis, we propose a principled and simple solution, which enables to control explicitly the label-marginal bias. Our loss integrates CE with explicit ${\cal L}_1$ regularization, which encourages label marginals to match target class proportions, thereby mitigating class imbalance but without losing generality. Comprehensive experiments and ablation studies over different losses and applications validate our theoretical analysis, as well as the effectiveness of our explicit label-marginal regularizers.