 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Guided Flow-Matching for Sparse 3D Geological Generation
Apr 07, 2026Constructing high-resolution 3D geological models from sparse 1D borehole and 2D surface data is a highly ill-posed inverse problem. Traditional heuristic and implicit modeling methods fundamentally fail to capture non-linear topological discontinuities under extreme sparsity, often yielding unrealistic artifacts. Furthermore, while deep generative architectures like Diffusion Models have revolutionized continuous domains, they suffer from severe representation collapse when conditioned on sparse categorical grids. To bridge this gap, we propose 3D-GeoFlow, the first Attention-Guided Continuous Flow Matching framework tailored for sparse multimodal geological modeling. By reformulating discrete categorical generation as a simulation-free, continuous vector field regression optimized via Mean Squared Error, our model establishes stable, deterministic optimal transport paths. Crucially, we integrate 3D Attention Gates to dynamically propagate localized borehole features across the volumetric latent space, ensuring macroscopic structural coherence. To validate our framework, we curated a large-scale multimodal dataset comprising 2,200 procedurally generated 3D geological cases. Extensive out-of-distribution (OOD) evaluations demonstrate that 3D-GeoFlow achieves a paradigm shift, significantly outperforming heuristic interpolations and standard diffusion baselines.
Surf2CT: Cascaded 3D Flow Matching Models for Torso 3D CT Synthesis from Skin Surface
May 29, 2025We present Surf2CT, a novel cascaded flow matching framework that synthesizes full 3D computed tomography (CT) volumes of the human torso from external surface scans and simple demographic data (age, sex, height, weight). This is the first approach capable of generating realistic volumetric internal anatomy images solely based on external body shape and demographics, without any internal imaging. Surf2CT proceeds through three sequential stages: (1) Surface Completion, reconstructing a complete signed distance function (SDF) from partial torso scans using conditional 3D flow matching; (2) Coarse CT Synthesis, generating a low-resolution CT volume from the completed SDF and demographic information; and (3) CT Super-Resolution, refining the coarse volume into a high-resolution CT via a patch-wise conditional flow model. Each stage utilizes a 3D-adapted EDM2 backbone trained via flow matching. We trained our model on a combined dataset of 3,198 torso CT scans (approximately 1.13 million axial slices) sourced from Massachusetts General Hospital (MGH) and the AutoPET challenge. Evaluation on 700 paired torso surface-CT cases demonstrated strong anatomical fidelity: organ volumes exhibited small mean percentage differences (range from -11.1% to 4.4%), and muscle/fat body composition metrics matched ground truth with strong correlation (range from 0.67 to 0.96). Lung localization had minimal bias (mean difference -2.5 mm), and surface completion significantly improved metrics (Chamfer distance: from 521.8 mm to 2.7 mm; Intersection-over-Union: from 0.87 to 0.98). Surf2CT establishes a new paradigm for non-invasive internal anatomical imaging using only external data, opening opportunities for home-based healthcare, preventive medicine, and personalized clinical assessments without the risks associated with conventional imaging techniques.
Cascaded 3D Diffusion Models for Whole-body 3D 18-F FDG PET/CT synthesis from Demographics
May 28, 2025We propose a cascaded 3D diffusion model framework to synthesize high-fidelity 3D PET/CT volumes directly from demographic variables, addressing the growing need for realistic digital twins in oncologic imaging, virtual trials, and AI-driven data augmentation. Unlike deterministic phantoms, which rely on predefined anatomical and metabolic templates, our method employs a two-stage generative process. An initial score-based diffusion model synthesizes low-resolution PET/CT volumes from demographic variables alone, providing global anatomical structures and approximate metabolic activity. This is followed by a super-resolution residual diffusion model that refines spatial resolution. Our framework was trained on 18-F FDG PET/CT scans from the AutoPET dataset and evaluated using organ-wise volume and standardized uptake value (SUV) distributions, comparing synthetic and real data between demographic subgroups. The organ-wise comparison demonstrated strong concordance between synthetic and real images. In particular, most deviations in metabolic uptake values remained within 3-5% of the ground truth in subgroup analysis. These findings highlight the potential of cascaded 3D diffusion models to generate anatomically and metabolically accurate PET/CT images, offering a robust alternative to traditional phantoms and enabling scalable, population-informed synthetic imaging for clinical and research applications.
OWT: A Foundational Organ-Wise Tokenization Framework for Medical Imaging
May 08, 2025Recent advances in representation learning often rely on holistic, black-box embeddings that entangle multiple semantic components, limiting interpretability and generalization. These issues are especially critical in medical imaging. To address these limitations, we propose an Organ-Wise Tokenization (OWT) framework with a Token Group-based Reconstruction (TGR) training paradigm. Unlike conventional approaches that produce holistic features, OWT explicitly disentangles an image into separable token groups, each corresponding to a distinct organ or semantic entity. Our design ensures each token group encapsulates organ-specific information, boosting interpretability, generalization, and efficiency while allowing fine-grained control in downstream tasks. Experiments on CT and MRI datasets demonstrate the effectiveness of OWT in not only achieving strong image reconstruction and segmentation performance, but also enabling novel semantic-level generation and retrieval applications that are out of reach for standard holistic embedding methods. These findings underscore the potential of OWT as a foundational framework for semantically disentangled representation learning, offering broad scalability and applicability to real-world medical imaging scenarios and beyond.
MAST-Pro: Dynamic Mixture-of-Experts for Adaptive Segmentation of Pan-Tumors with Knowledge-Driven Prompts
Mar 18, 2025Accurate tumor segmentation is crucial for cancer diagnosis and treatment. While foundation models have advanced general-purpose segmentation, existing methods still struggle with: (1) limited incorporation of medical priors, (2) imbalance between generic and tumor-specific features, and (3) high computational costs for clinical adaptation. To address these challenges, we propose MAST-Pro (Mixture-of-experts for Adaptive Segmentation of pan-Tumors with knowledge-driven Prompts), a novel framework that integrates dynamic Mixture-of-Experts (D-MoE) and knowledge-driven prompts for pan-tumor segmentation. Specifically, text and anatomical prompts provide domain-specific priors, guiding tumor representation learning, while D-MoE dynamically selects experts to balance generic and tumor-specific feature learning, improving segmentation accuracy across diverse tumor types. To enhance efficiency, we employ Parameter-Efficient Fine-Tuning (PEFT), optimizing MAST-Pro with significantly reduced computational overhead. Experiments on multi-anatomical tumor datasets demonstrate that MAST-Pro outperforms state-of-the-art approaches, achieving up to a 5.20% improvement in average DSC while reducing trainable parameters by 91.04%, without compromising accuracy.
Prediction of Frozen Region Growth in Kidney Cryoablation Intervention Using a 3D Flow-Matching Model
Mar 06, 2025This study presents a 3D flow-matching model designed to predict the progression of the frozen region (iceball) during kidney cryoablation. Precise intraoperative guidance is critical in cryoablation to ensure complete tumor eradication while preserving adjacent healthy tissue. However, conventional methods, typically based on physics driven or diffusion based simulations, are computationally demanding and often struggle to represent complex anatomical structures accurately. To address these limitations, our approach leverages intraoperative CT imaging to inform the model. The proposed 3D flow matching model is trained to learn a continuous deformation field that maps early-stage CT scans to future predictions. This transformation not only estimates the volumetric expansion of the iceball but also generates corresponding segmentation masks, effectively capturing spatial and morphological changes over time. Quantitative analysis highlights the model robustness, demonstrating strong agreement between predictions and ground-truth segmentations. The model achieves an Intersection over Union (IoU) score of 0.61 and a Dice coefficient of 0.75. By integrating real time CT imaging with advanced deep learning techniques, this approach has the potential to enhance intraoperative guidance in kidney cryoablation, improving procedural outcomes and advancing the field of minimally invasive surgery.
Developing a PET/CT Foundation Model for Cross-Modal Anatomical and Functional Imaging
Mar 04, 2025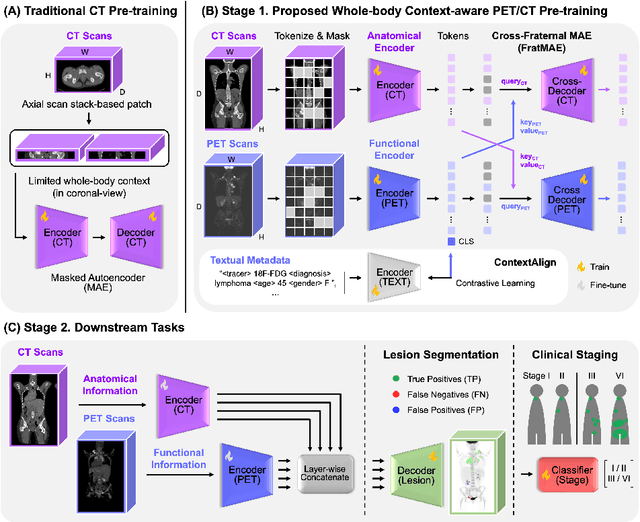


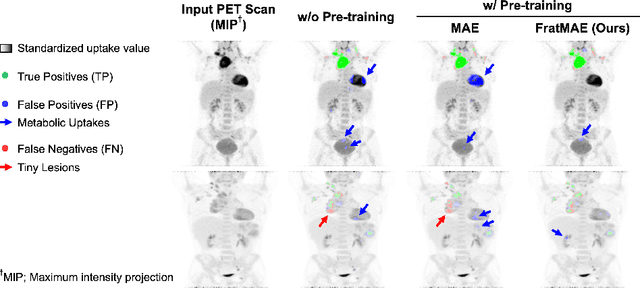
In oncology, Positron Emission Tomography-Computed Tomography (PET/CT) is widely used in cancer diagnosis, staging, and treatment monitoring, as it combines anatomical details from CT with functional metabolic activity and molecular marker expression information from PET. However, existing artificial intelligence-driven PET/CT analyses rely predominantly on task-specific models trained from scratch or on limited datasets, limiting their generalizability and robustness. To address this, we propose a foundation model approach specifically designed for multimodal PET/CT imaging. We introduce the Cross-Fraternal Twin Masked Autoencoder (FratMAE), a novel framework that effectively integrates whole-body anatomical and functional or molecular information. FratMAE employs separate Vision Transformer (ViT) encoders for PET and CT scans, along with cross-attention decoders that enable synergistic interactions between modalities during masked autoencoder training. Additionally, it incorporates textual metadata to enhance PET representation learning. By pre-training on PET/CT datasets, FratMAE captures intricate cross-modal relationships and global uptake patterns, achieving superior performance on downstream tasks and demonstrating its potential as a generalizable foundation model.
EchoFM: Foundation Model for Generalizable Echocardiogram Analysis
Oct 30, 2024



Foundation models have recently gained significant attention because of their generalizability and adaptability across multiple tasks and data distributions. Although medical foundation models have emerged, solutions for cardiac imaging, especially echocardiography videos, are still unexplored. In this paper, we introduce EchoFM, a foundation model specifically designed to represent and analyze echocardiography videos. In EchoFM, we propose a self-supervised learning framework that captures both spatial and temporal variability patterns through a spatio-temporal consistent masking strategy and periodic-driven contrastive learning. This framework can effectively capture the spatio-temporal dynamics of echocardiography and learn the representative video features without any labels. We pre-train our model on an extensive dataset comprising over 290,000 echocardiography videos covering 26 scan views across different imaging modes, with up to 20 million frames of images. The pre-trained EchoFM can then be easily adapted and fine-tuned for a variety of downstream tasks, serving as a robust backbone model. Our evaluation was systemically designed for four downstream tasks after the echocardiography examination routine. Experiment results show that EchoFM surpasses state-of-the-art methods, including specialized echocardiography methods, self-supervised pre-training models, and general-purposed pre-trained foundation models, across all downstream tasks.
Retrieval Instead of Fine-tuning: A Retrieval-based Parameter Ensemble for Zero-shot Learning
Oct 13, 2024



Foundation models have become a cornerstone in deep learning, with techniques like Low-Rank Adaptation (LoRA) offering efficient fine-tuning of large models. Similarly, methods such as Retrieval-Augmented Generation (RAG), which leverage vectorized databases, have further improved model performance by grounding outputs in external information. While these approaches have demonstrated notable success, they often require extensive training or labeled data, which can limit their adaptability in resource-constrained environments. To address these challenges, we introduce Retrieval-based Parameter Ensemble (RPE), a new method that creates a vectorized database of LoRAs, enabling efficient retrieval and application of model adaptations to new tasks. RPE minimizes the need for extensive training and eliminates the requirement for labeled data, making it particularly effective for zero-shot learning. Additionally, RPE is well-suited for privacy-sensitive domains like healthcare, as it modifies model parameters without accessing raw data. When applied to tasks such as medical report generation and image segmentation, RPE not only proved effective but also surpassed supervised fine-tuning methods in certain cases, highlighting its potential to enhance both computational efficiency and privacy in deep learning applications.
ECHOPulse: ECG controlled echocardio-grams video generation
Oct 04, 2024



Echocardiography (ECHO) is essential for cardiac assessments, but its video quality and interpretation heavily relies on manual expertise, leading to inconsistent results from clinical and portable devices. ECHO video generation offers a solution by improving automated monitoring through synthetic data and generating high-quality videos from routine health data. However, existing models often face high computational costs, slow inference, and rely on complex conditional prompts that require experts' annotations. To address these challenges, we propose ECHOPULSE, an ECG-conditioned ECHO video generation model. ECHOPULSE introduces two key advancements: (1) it accelerates ECHO video generation by leveraging VQ-VAE tokenization and masked visual token modeling for fast decoding, and (2) it conditions on readily accessible ECG signals, which are highly coherent with ECHO videos, bypassing complex conditional prompts. To the best of our knowledge, this is the first work to use time-series prompts like ECG signals for ECHO video generation. ECHOPULSE not only enables controllable synthetic ECHO data generation but also provides updated cardiac function information for disease monitoring and prediction beyond ECG alone. Evaluations on three public and private datasets demonstrate state-of-the-art performance in ECHO video generation across both qualitative and quantitative measures. Additionally, ECHOPULSE can be easily generalized to other modality generation tasks, such as cardiac MRI, fMRI, and 3D CT generation. Demo can seen from \url{https://github.com/levyisthebest/ECHOPulse_Prelease}.