 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a PET/CT Foundation Model for Cross-Modal Anatomical and Functional Imaging
Mar 04, 2025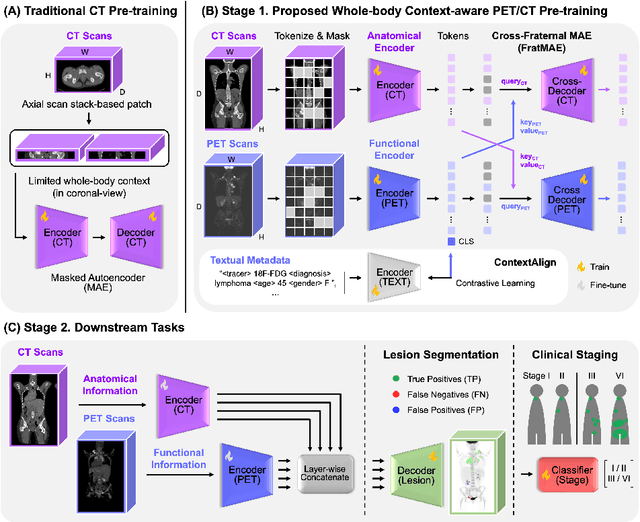


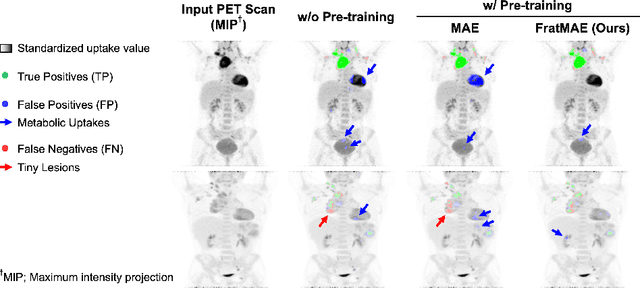
In oncology, Positron Emission Tomography-Computed Tomography (PET/CT) is widely used in cancer diagnosis, staging, and treatment monitoring, as it combines anatomical details from CT with functional metabolic activity and molecular marker expression information from PET. However, existing artificial intelligence-driven PET/CT analyses rely predominantly on task-specific models trained from scratch or on limited datasets, limiting their generalizability and robustness. To address this, we propose a foundation model approach specifically designed for multimodal PET/CT imaging. We introduce the Cross-Fraternal Twin Masked Autoencoder (FratMAE), a novel framework that effectively integrates whole-body anatomical and functional or molecular information. FratMAE employs separate Vision Transformer (ViT) encoders for PET and CT scans, along with cross-attention decoders that enable synergistic interactions between modalities during masked autoencoder training. Additionally, it incorporates textual metadata to enhance PET representation learning. By pre-training on PET/CT datasets, FratMAE captures intricate cross-modal relationships and global uptake patterns, achieving superior performance on downstream tasks and demonstrating its potential as a generalizable foundation model.