 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelta Knowledge Distillation for Large Language Models
Sep 18, 2025Knowledge distillation (KD) is a widely adopted approach for compressing large neural networks by transferring knowledge from a large teacher model to a smaller student model. In the context of large language models, token level KD, typically minimizing the KL divergence between student output distribution and teacher output distribution, has shown strong empirical performance. However, prior work assumes student output distribution and teacher output distribution share the same optimal representation space, a premise that may not hold in many cases. To solve this problem, we propose Delta Knowledge Distillation (Delta-KD), a novel extension of token level KD that encourages the student to approximate an optimal representation space by explicitly preserving the distributional shift Delta introduced during the teacher's supervised finetuning (SFT). Empirical results on ROUGE metrics demonstrate that Delta KD substantially improves student performance while preserving more of the teacher's knowledge.
BoxFusion: Reconstruction-Free Open-Vocabulary 3D Object Detection via Real-Time Multi-View Box Fusion
Jun 18, 2025Open-vocabulary 3D object detection has gained significant interest due to its critical applications in autonomous driving and embodied AI. Existing detection methods, whether offline or online, typically rely on dense point cloud reconstruction, which imposes substantial computational overhead and memory constraints, hindering real-time deployment in downstream tasks. To address this, we propose a novel reconstruction-free online framework tailored for memory-efficient and real-time 3D detection. Specifically, given streaming posed RGB-D video input, we leverage Cubify Anything as a pre-trained visual foundation model (VFM) for single-view 3D object detection by bounding boxes, coupled with CLIP to capture open-vocabulary semantics of detected objects. To fuse all detected bounding boxes across different views into a unified one, we employ an association module for correspondences of multi-views and an optimization module to fuse the 3D bounding boxes of the same instance predicted in multi-views. The association module utilizes 3D Non-Maximum Suppression (NMS) and a box correspondence matching module, while the optimization module uses an IoU-guided efficient random optimization technique based on particle filtering to enforce multi-view consistency of the 3D bounding boxes while minimizing computational complexity. Extensive experiments on ScanNetV2 and CA-1M datasets demonstrate that our method achieves state-of-the-art performance among online methods. Benefiting from this novel reconstruction-free paradigm for 3D object detection, our method exhibits great generalization abilities in various scenarios, enabling real-time perception even in environments exceeding 1000 square meters.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025



Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.
A Survey on Post-training of Large Language Models
Mar 08, 2025The emergence of Large Language Models (LLMs) has fundamentally transformed natural language processing, making them indispensable across domains ranging from conversational systems to scientific exploration. However, their pre-trained architectures often reveal limitations in specialized contexts, including restricted reasoning capacities, ethical uncertainties, and suboptimal domain-specific performance. These challenges necessitate advanced post-training language models (PoLMs) to address these shortcomings, such as OpenAI-o1/o3 and DeepSeek-R1 (collectively known as Large Reasoning Models, or LRMs). This paper presents the first comprehensive survey of PoLMs, systematically tracing their evolution across five core paradigms: Fine-tuning, which enhances task-specific accuracy; Alignment, which ensures alignment with human preferences; Reasoning, which advances multi-step inference despite challenges in reward design; Efficiency, which optimizes resource utilization amidst increasing complexity; and Integration and Adaptation, which extend capabilities across diverse modalities while addressing coherence issues. Charting progress from ChatGPT's foundational alignment strategies to DeepSeek-R1's innovative reasoning advancements, we illustrate how PoLMs leverage datasets to mitigate biases, deepen reasoning capabilities, and enhance domain adaptability. Our contributions include a pioneering synthesis of PoLM evolution, a structured taxonomy categorizing techniques and datasets, and a strategic agenda emphasizing the role of LRMs in improving reasoning proficiency and domain flexibility. As the first survey of its scope, this work consolidates recent PoLM advancements and establishes a rigorous intellectual framework for future research, fostering the development of LLMs that excel in precision, ethical robustness, and versatility across scientific and societal applications.
Developing a PET/CT Foundation Model for Cross-Modal Anatomical and Functional Imaging
Mar 04, 2025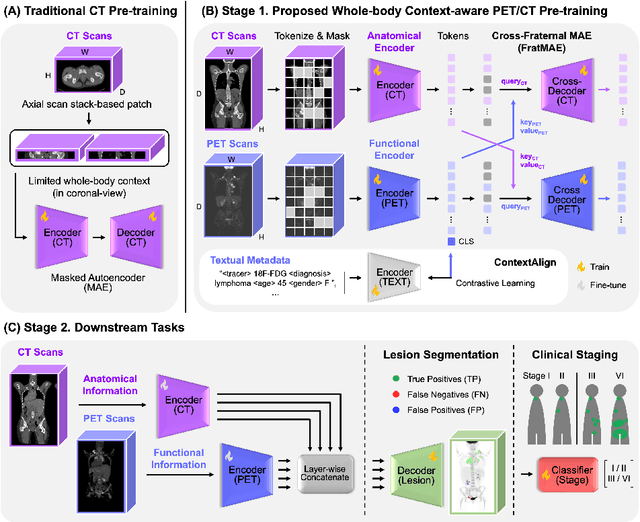


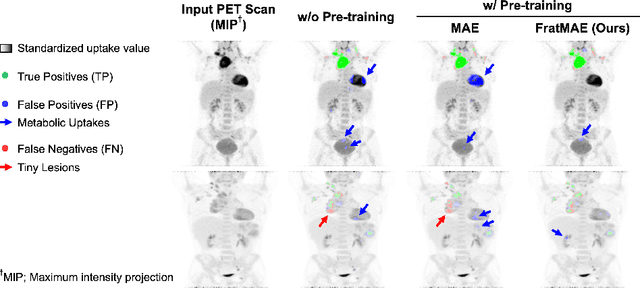
In oncology, Positron Emission Tomography-Computed Tomography (PET/CT) is widely used in cancer diagnosis, staging, and treatment monitoring, as it combines anatomical details from CT with functional metabolic activity and molecular marker expression information from PET. However, existing artificial intelligence-driven PET/CT analyses rely predominantly on task-specific models trained from scratch or on limited datasets, limiting their generalizability and robustness. To address this, we propose a foundation model approach specifically designed for multimodal PET/CT imaging. We introduce the Cross-Fraternal Twin Masked Autoencoder (FratMAE), a novel framework that effectively integrates whole-body anatomical and functional or molecular information. FratMAE employs separate Vision Transformer (ViT) encoders for PET and CT scans, along with cross-attention decoders that enable synergistic interactions between modalities during masked autoencoder training. Additionally, it incorporates textual metadata to enhance PET representation learning. By pre-training on PET/CT datasets, FratMAE captures intricate cross-modal relationships and global uptake patterns, achieving superior performance on downstream tasks and demonstrating its potential as a generalizable foundation model.
Efficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs
Dec 11, 2024



Object goal navigation (ObjectNav) is a fundamental task of embodied AI that requires the agent to find a target object in unseen environments. This task is particularly challenging as it demands both perceptual and cognitive processes for effective perception and decision-making. While perception has gained significant progress powered by the rapidly developed visual foundation models, the progress on the cognitive side remains limited to either implicitly learning from massive navigation demonstrations or explicitly leveraging pre-defined heuristic rules. Inspired by neuroscientific evidence that humans consistently update their cognitive states while searching for objects in unseen environments, we present CogNav, which attempts to model this cognitive process with the help of large language models. Specifically, we model the cognitive process with a finite state machine composed of cognitive states ranging from exploration to identification. The transitions between the states are determined by a large language model based on an online built heterogeneous cognitive map containing spatial and semantic information of the scene being explored. Extensive experiments on both synthetic and real-world environments demonstrate that our cognitive modeling significantly improves ObjectNav efficiency, with human-like navigation behaviors. In an open-vocabulary and zero-shot setting, our method advances the SOTA of the HM3D benchmark from 69.3% to 87.2%. The code and data will be released.
Neural Observation Field Guided Hybrid Optimization of Camera Placement
Dec 11, 2024



Camera placement is crutial in multi-camera systems such as virtual reality, autonomous driving, and high-quality reconstruction. The camera placement challenge lies in the nonlinear nature of high-dimensional parameters and the unavailability of gradients for target functions like coverage and visibility. Consequently, most existing methods tackle this challenge by leveraging non-gradient-based optimization methods.In this work, we present a hybrid camera placement optimization approach that incorporates both gradient-based and non-gradient-based optimization methods. This design allows our method to enjoy the advantages of smooth optimization convergence and robustness from gradient-based and non-gradient-based optimization, respectively. To bridge the two disparate optimization methods, we propose a neural observation field, which implicitly encodes the coverage and observation quality. The neural observation field provides the measurements of the camera observations and corresponding gradients without the assumption of target scenes, making our method applicable to diverse scenarios, including 2D planar shapes, 3D objects, and room-scale 3D scenes.Extensive experiments on diverse datasets demonstrate that our method achieves state-of-the-art performance, while requiring only a fraction (8x less) of the typical computation time. Furthermore, we conducted a real-world experiment using a custom-built capture system, confirming the resilience of our approach to real-world environmental noise.
* Accepted by Robotics and Automation Letters (RAL 2024)
TAROT: A Hierarchical Framework with Multitask Co-Pretraining on Semi-Structured Data towards Effective Person-Job Fit
Jan 17, 2024Person-job fit is an essential part of online recruitment platforms in serving various downstream applications like Job Search and Candidate Recommendation. Recently, pretrained large language models have further enhanced the effectiveness by leveraging richer textual information in user profiles and job descriptions apart from user behavior features and job metadata. However, the general domain-oriented design struggles to capture the unique structural information within user profiles and job descriptions, leading to a loss of latent semantic correlations. We propose TAROT, a hierarchical multitask co-pretraining framework, to better utilize structural and semantic information for informative text embeddings. TAROT targets semi-structured text in profiles and jobs, and it is co-pretained with multi-grained pretraining tasks to constrain the acquired semantic information at each level. Experiments on a real-world LinkedIn dataset show significant performance improvements, proving its effectiveness in person-job fit tasks.
API-Assisted Code Generation for Question Answering on Varied Table Structures
Oct 23, 2023



A persistent challenge to table question answering (TableQA) by generating executable programs has been adapting to varied table structures, typically requiring domain-specific logical forms. In response, this paper introduces a unified TableQA framework that: (1) provides a unified representation for structured tables as multi-index Pandas data frames, (2) uses Python as a powerful querying language, and (3) uses few-shot prompting to translate NL questions into Python programs, which are executable on Pandas data frames. Furthermore, to answer complex relational questions with extended program functionality and external knowledge, our framework allows customized APIs that Python programs can call. We experiment with four TableQA datasets that involve tables of different structures -- relational, multi-table, and hierarchical matrix shapes -- and achieve prominent improvements over past state-of-the-art systems. In ablation studies, we (1) show benefits from our multi-index representation and APIs over baselines that use only an LLM, and (2) demonstrate that our approach is modular and can incorporate additional APIs.