 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient AI in Practice: Training and Deployment of Efficient LLMs for Industry Applications
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable performance across a wide range of industrial applications, from search and recommendations to generative tasks. Although scaling laws indicate that larger models generally yield better generalization and performance, their substantial computational requirements often render them impractical for many real-world scenarios at scale. In this paper, we present methods and insights for training small language models (SLMs) that deliver high performance and efficiency in deployment. We focus on two key techniques: (1) knowledge distillation and (2) model compression via quantization and pruning. These approaches enable SLMs to retain much of the quality of their larger counterparts while significantly reducing training, serving costs, and latency. We detail the impact of these techniques on a variety of use cases at a large professional social network platform and share deployment lessons - including hardware optimization strategies that enhance speed and throughput for both predictive and reasoning-based applications.
The Space Complexity of Approximating Logistic Loss
Dec 03, 2024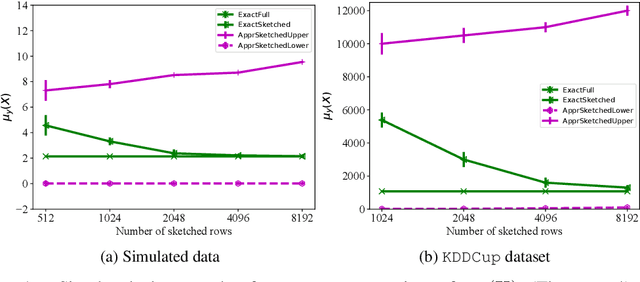
We provide space complexity lower bounds for data structures that approximate logistic loss up to $\epsilon$-relative error on a logistic regression problem with data $\mathbf{X} \in \mathbb{R}^{n \times d}$ and labels $\mathbf{y} \in \{-1,1\}^d$. The space complexity of existing coreset constructions depend on a natural complexity measure $\mu_\mathbf{y}(\mathbf{X})$, first defined in (Munteanu, 2018). We give an $\tilde{\Omega}(\frac{d}{\epsilon^2})$ space complexity lower bound in the regime $\mu_\mathbf{y}(\mathbf{X}) = O(1)$ that shows existing coresets are optimal in this regime up to lower order factors. We also prove a general $\tilde{\Omega}(d\cdot \mu_\mathbf{y}(\mathbf{X}))$ space lower bound when $\epsilon$ is constant, showing that the dependency on $\mu_\mathbf{y}(\mathbf{X})$ is not an artifact of mergeable coresets. Finally, we refute a prior conjecture that $\mu_\mathbf{y}(\mathbf{X})$ is hard to compute by providing an efficient linear programming formulation, and we empirically compare our algorithm to prior approximate methods.
Stochastic Rounding Implicitly Regularizes Tall-and-Thin Matrices
Mar 18, 2024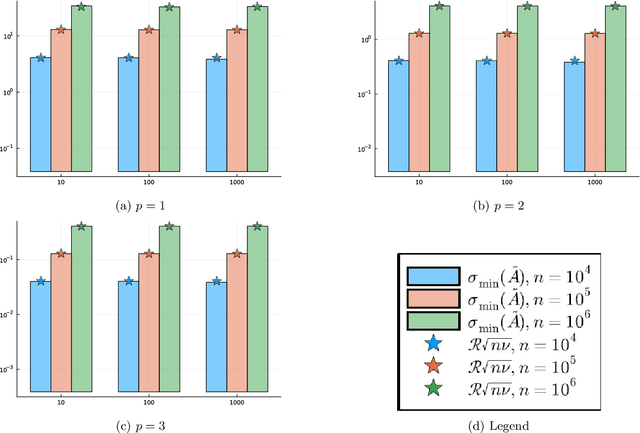
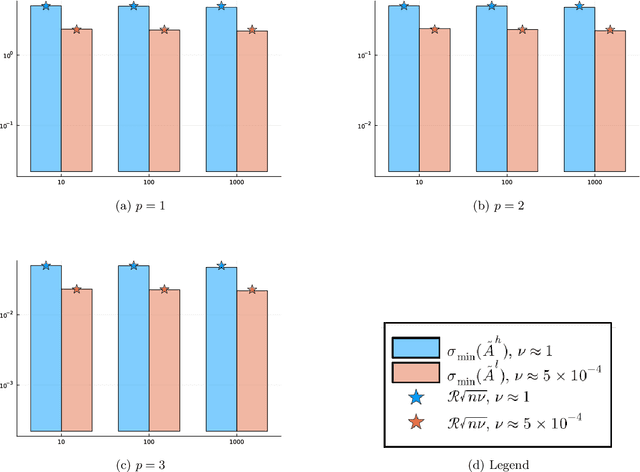

Motivated by the popularity of stochastic rounding in the context of machine learning and the training of large-scale deep neural network models, we consider stochastic nearness rounding of real matrices $\mathbf{A}$ with many more rows than columns. We provide novel theoretical evidence, supported by extensive experimental evaluation that, with high probability, the smallest singular value of a stochastically rounded matrix is well bounded away from zero -- regardless of how close $\mathbf{A}$ is to being rank deficient and even if $\mathbf{A}$ is rank-deficient. In other words, stochastic rounding \textit{implicitly regularizes} tall and skinny matrices $\mathbf{A}$ so that the rounded version has full column rank. Our proofs leverage powerful results in random matrix theory, and the idea that stochastic rounding errors do not concentrate in low-dimensional column spaces.
A Precise Characterization of SGD Stability Using Loss Surface Geometry
Jan 22, 2024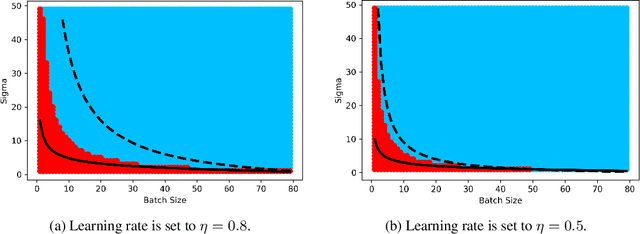
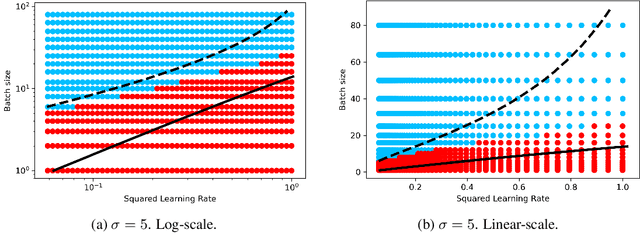
Stochastic Gradient Descent (SGD) stands as a cornerstone optimization algorithm with proven real-world empirical successes but relatively limited theoretical understanding. Recent research has illuminated a key factor contributing to its practical efficacy: the implicit regularization it instigates. Several studies have investigated the linear stability property of SGD in the vicinity of a stationary point as a predictive proxy for sharpness and generalization error in overparameterized neural networks (Wu et al., 2022; Jastrzebski et al., 2019; Cohen et al., 2021). In this paper, we delve deeper into the relationship between linear stability and sharpness. More specifically, we meticulously delineate the necessary and sufficient conditions for linear stability, contingent on hyperparameters of SGD and the sharpness at the optimum. Towards this end, we introduce a novel coherence measure of the loss Hessian that encapsulates pertinent geometric properties of the loss function that are relevant to the linear stability of SGD. It enables us to provide a simplified sufficient condition for identifying linear instability at an optimum. Notably, compared to previous works, our analysis relies on significantly milder assumptions and is applicable for a broader class of loss functions than known before, encompassing not only mean-squared error but also cross-entropy loss.
Sketching Algorithms for Sparse Dictionary Learning: PTAS and Turnstile Streaming
Oct 29, 2023Sketching algorithms have recently proven to be a powerful approach both for designing low-space streaming algorithms as well as fast polynomial time approximation schemes (PTAS). In this work, we develop new techniques to extend the applicability of sketching-based approaches to the sparse dictionary learning and the Euclidean $k$-means clustering problems. In particular, we initiate the study of the challenging setting where the dictionary/clustering assignment for each of the $n$ input points must be output, which has surprisingly received little attention in prior work. On the fast algorithms front, we obtain a new approach for designing PTAS's for the $k$-means clustering problem, which generalizes to the first PTAS for the sparse dictionary learning problem. On the streaming algorithms front, we obtain new upper bounds and lower bounds for dictionary learning and $k$-means clustering. In particular, given a design matrix $\mathbf A\in\mathbb R^{n\times d}$ in a turnstile stream, we show an $\tilde O(nr/\epsilon^2 + dk/\epsilon)$ space upper bound for $r$-sparse dictionary learning of size $k$, an $\tilde O(n/\epsilon^2 + dk/\epsilon)$ space upper bound for $k$-means clustering, as well as an $\tilde O(n)$ space upper bound for $k$-means clustering on random order row insertion streams with a natural "bounded sensitivity" assumption. On the lower bounds side, we obtain a general $\tilde\Omega(n/\epsilon + dk/\epsilon)$ lower bound for $k$-means clustering, as well as an $\tilde\Omega(n/\epsilon^2)$ lower bound for algorithms which can estimate the cost of a single fixed set of candidate centers.
Feature Space Sketching for Logistic Regression
Mar 24, 2023We present novel bounds for coreset construction, feature selection, and dimensionality reduction for logistic regression. All three approaches can be thought of as sketching the logistic regression inputs. On the coreset construction front, we resolve open problems from prior work and present novel bounds for the complexity of coreset construction methods. On the feature selection and dimensionality reduction front, we initiate the study of forward error bounds for logistic regression. Our bounds are tight up to constant factors and our forward error bounds can be extended to Generalized Linear Models.
Inverse Reinforcement Learning in the Continuous Setting with Formal Guarantees
Feb 16, 2021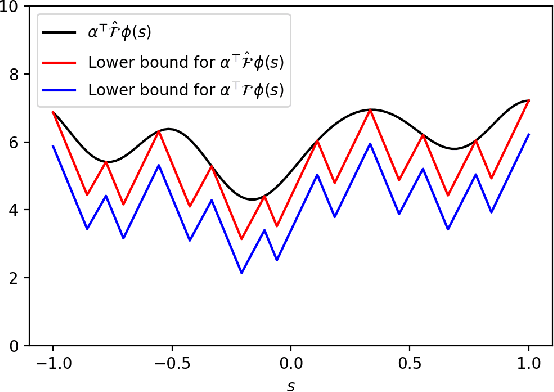
Inverse Reinforcement Learning (IRL) is the problem of finding a reward function which describes observed/known expert behavior. IRL is useful for automated control in situations where the reward function is difficult to specify manually, which impedes reinforcement learning. We provide a new IRL algorithm for the continuous state space setting with unknown transition dynamics by modeling the system using a basis of orthonormal functions. We provide a proof of correctness and formal guarantees on the sample and time complexity of our algorithm.