 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Alignment Mitigates Reward Hacking in Reinforcement Learning for Language Models
May 24, 2026Reward hacking arises when a model improves a proxy reward by exploiting shortcuts rather than solving the intended task. We study this failure mode through the geometry of reinforcement learning updates in language models and argue that hacking emerges when optimization drifts away from a stable low-dimensional learning trajectory. We analyze this drift through dominant singular directions of parameter updates and show that reward-hacking runs exhibit substantially larger directional change than clean runs. Motivated by this observation, we introduce trusted-direction projection, which constrains gradients to remain within a clean reference subspace. Across reward-hacking experiments on mathematical reasoning, the proposed approach delays shortcut exploitation and better preserves task performance.
Spend Less, Reason Better: Budget-Aware Value Tree Search for LLM Agents
Mar 13, 2026Test-time scaling has become a dominant paradigm for improving LLM agent reliability, yet current approaches treat compute as an abundant resource, allowing agents to exhaust token and tool budgets on redundant steps or dead-end trajectories. Existing budget-aware methods either require expensive fine-tuning or rely on coarse, trajectory-level heuristics that cannot intervene mid-execution. We propose the Budget-Aware Value Tree (BAVT), a training-free inference-time framework that models multi-hop reasoning as a dynamic search tree guided by step-level value estimation within a single LLM backbone. Another key innovation is a budget-conditioned node selection mechanism that uses the remaining resource ratio as a natural scaling exponent over node values, providing a principled, parameter-free transition from broad exploration to greedy exploitation as the budget depletes. To combat the well-known overconfidence of LLM self-evaluation, BAVT employs a residual value predictor that scores relative progress rather than absolute state quality, enabling reliable pruning of uninformative or redundant tool calls. We further provide a theoretical convergence guarantee, proving that BAVT reaches a terminal answer with probability at least $1-ε$ under an explicit finite budget bound. Extensive evaluations on four multi-hop QA benchmarks across two model families demonstrate that BAVT consistently outperforms parallel sampling baselines. Most notably, BAVT under strict low-budget constraints surpasses baseline performance at $4\times$ the resource allocation, establishing that intelligent budget management fundamentally outperforms brute-force compute scaling.
When RAG Hurts: Diagnosing and Mitigating Attention Distraction in Retrieval-Augmented LVLMs
Jan 30, 2026While Retrieval-Augmented Generation (RAG) is one of the dominant paradigms for enhancing Large Vision-Language Models (LVLMs) on knowledge-based VQA tasks, recent work attributes RAG failures to insufficient attention towards the retrieved context, proposing to reduce the attention allocated to image tokens. In this work, we identify a distinct failure mode that previous study overlooked: Attention Distraction (AD). When the retrieved context is sufficient (highly relevant or including the correct answer), the retrieved text suppresses the visual attention globally, and the attention on image tokens shifts away from question-relevant regions. This leads to failures on questions the model could originally answer correctly without the retrieved text. To mitigate this issue, we propose MAD-RAG, a training-free intervention that decouples visual grounding from context integration through a dual-question formulation, combined with attention mixing to preserve image-conditioned evidence. Extensive experiments on OK-VQA, E-VQA, and InfoSeek demonstrate that MAD-RAG consistently outperforms existing baselines across different model families, yielding absolute gains of up to 4.76%, 9.20%, and 6.18% over the vanilla RAG baseline. Notably, MAD-RAG rectifies up to 74.68% of failure cases with negligible computational overhead.
Textual Equilibrium Propagation for Deep Compound AI Systems
Jan 28, 2026Large language models (LLMs) are increasingly deployed as part of compound AI systems that coordinate multiple modules (e.g., retrievers, tools, verifiers) over long-horizon workflows. Recent approaches that propagate textual feedback globally (e.g., TextGrad) make it feasible to optimize such pipelines, but we find that performance degrades as system depth grows. In particular, long-horizon agentic workflows exhibit two depth-scaling failure modes: 1) exploding textual gradient, where textual feedback grows exponentially with depth, leading to prohibitively long message and amplifies evaluation biases; and 2) vanishing textual gradient, where limited long-context ability causes models overemphasize partial feedback and compression of lengthy feedback causes downstream messages to lose specificity gradually as they propagate many hops upstream. To mitigate these issues, we introduce Textual Equilibrium Propagation (TEP), a local learning principle inspired by Equilibrium Propagation in energy-based models. TEP includes two phases: 1) a free phase where a local LLM critics iteratively refine prompts until reaching equilibrium (no further improvements are suggested); and 2) a nudged phase which applies proximal prompt edits with bounded modification intensity, using task-level objectives that propagate via forward signaling rather than backward feedback chains. This design supports local prompt optimization followed by controlled adaptation toward global goals without the computational burden and signal degradation of global textual backpropagation. Across long-horizon QA benchmarks and multi-agent tool-use dataset, TEP consistently improves accuracy and efficiency over global propagation methods such as TextGrad. The gains grows with depth, while preserving the practicality of black-box LLM components in deep compound AI system.
Advantage Shaping as Surrogate Reward Maximization: Unifying Pass@K Policy Gradients
Oct 27, 2025This note reconciles two seemingly distinct approaches to policy gradient optimization for the Pass@K objective in reinforcement learning with verifiable rewards: (1) direct REINFORCE-style methods, and (2) advantage-shaping techniques that directly modify GRPO. We show that these are two sides of the same coin. By reverse-engineering existing advantage-shaping algorithms, we reveal that they implicitly optimize surrogate rewards. We specifically interpret practical ``hard-example up-weighting'' modifications to GRPO as reward-level regularization. Conversely, starting from surrogate reward objectives, we provide a simple recipe for deriving both existing and new advantage-shaping methods. This perspective provides a lens for RLVR policy gradient optimization beyond our original motivation of Pass@K.
Efficient Forward-Only Data Valuation for Pretrained LLMs and VLMs
Aug 13, 2025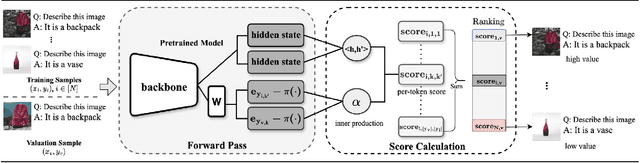
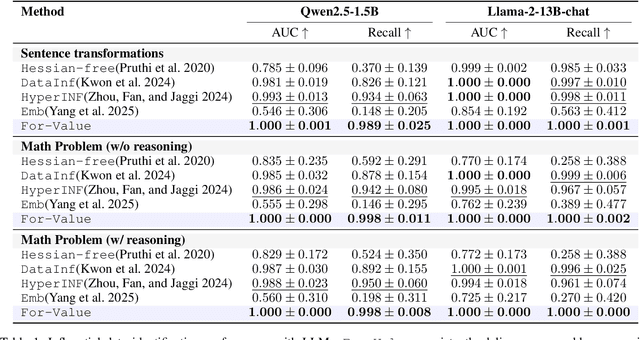
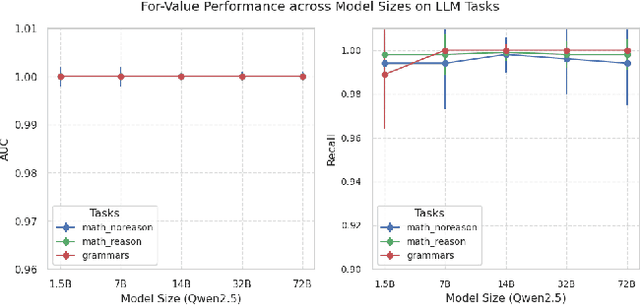
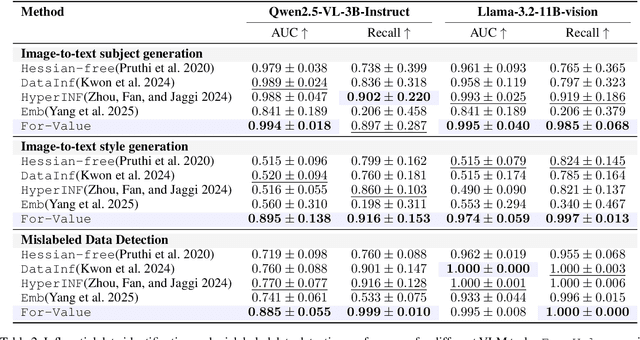
Quantifying the influence of individual training samples is essential for enhancing the transparency and accountability of large language models (LLMs) and vision-language models (VLMs). However, existing data valuation methods often rely on Hessian information or model retraining, making them computationally prohibitive for billion-parameter models. In this work, we introduce For-Value, a forward-only data valuation framework that enables scalable and efficient influence estimation for both LLMs and VLMs. By leveraging the rich representations of modern foundation models, For-Value computes influence scores using a simple closed-form expression based solely on a single forward pass, thereby eliminating the need for costly gradient computations. Our theoretical analysis demonstrates that For-Value accurately estimates per-sample influence by capturing alignment in hidden representations and prediction errors between training and validation samples. Extensive experiments show that For-Value matches or outperforms gradient-based baselines in identifying impactful fine-tuning examples and effectively detecting mislabeled data.
On the Effect of Negative Gradient in Group Relative Deep Reinforcement Optimization
May 24, 2025Reinforcement learning (RL) has become popular in enhancing the reasoning capabilities of large language models (LLMs), with Group Relative Policy Optimization (GRPO) emerging as a widely used algorithm in recent systems. Despite GRPO's widespread adoption, we identify a previously unrecognized phenomenon we term Lazy Likelihood Displacement (LLD), wherein the likelihood of correct responses marginally increases or even decreases during training. This behavior mirrors a recently discovered misalignment issue in Direct Preference Optimization (DPO), attributed to the influence of negative gradients. We provide a theoretical analysis of GRPO's learning dynamic, identifying the source of LLD as the naive penalization of all tokens in incorrect responses with the same strength. To address this, we develop a method called NTHR, which downweights penalties on tokens contributing to the LLD. Unlike prior DPO-based approaches, NTHR takes advantage of GRPO's group-based structure, using correct responses as anchors to identify influential tokens. Experiments on math reasoning benchmarks demonstrate that NTHR effectively mitigates LLD, yielding consistent performance gains across models ranging from 0.5B to 3B parameters.
MedReason: Eliciting Factual Medical Reasoning Steps in LLMs via Knowledge Graphs
Apr 01, 2025



Medical tasks such as diagnosis and treatment planning require precise and complex reasoning, particularly in life-critical domains. Unlike mathematical reasoning, medical reasoning demands meticulous, verifiable thought processes to ensure reliability and accuracy. However, there is a notable lack of datasets that provide transparent, step-by-step reasoning to validate and enhance the medical reasoning ability of AI models. To bridge this gap, we introduce MedReason, a large-scale high-quality medical reasoning dataset designed to enable faithful and explainable medical problem-solving in large language models (LLMs). We utilize a structured medical knowledge graph (KG) to convert clinical QA pairs into logical chains of reasoning, or ``thinking paths'', which trace connections from question elements to answers via relevant KG entities. Each path is validated for consistency with clinical logic and evidence-based medicine. Our pipeline generates detailed reasoning for various medical questions from 7 medical datasets, resulting in a dataset of 32,682 question-answer pairs, each with detailed, step-by-step explanations. Experiments demonstrate that fine-tuning with our dataset consistently boosts medical problem-solving capabilities, achieving significant gains of up to 7.7% for DeepSeek-Ditill-8B. Our top-performing model, MedReason-8B, outperforms the Huatuo-o1-8B, a state-of-the-art medical reasoning model, by up to 4.2% on the clinical benchmark MedBullets. We also engage medical professionals from diverse specialties to assess our dataset's quality, ensuring MedReason offers accurate and coherent medical reasoning. Our data, models, and code will be publicly available.
Can Textual Gradient Work in Federated Learning?
Feb 27, 2025Recent studies highlight the promise of LLM-based prompt optimization, especially with TextGrad, which automates differentiation'' via texts and backpropagates textual feedback. This approach facilitates training in various real-world applications that do not support numerical gradient propagation or loss calculation. In this paper, we systematically explore the potential and challenges of incorporating textual gradient into Federated Learning (FL). Our contributions are fourfold. Firstly, we introduce a novel FL paradigm, Federated Textual Gradient (FedTextGrad), that allows clients to upload locally optimized prompts derived from textual gradients, while the server aggregates the received prompts. Unlike traditional FL frameworks, which are designed for numerical aggregation, FedTextGrad is specifically tailored for handling textual data, expanding the applicability of FL to a broader range of problems that lack well-defined numerical loss functions. Secondly, building on this design, we conduct extensive experiments to explore the feasibility of FedTextGrad. Our findings highlight the importance of properly tuning key factors (e.g., local steps) in FL training. Thirdly, we highlight a major challenge in FedTextGrad aggregation: retaining essential information from distributed prompt updates. Last but not least, in response to this issue, we improve the vanilla variant of FedTextGrad by providing actionable guidance to the LLM when summarizing client prompts by leveraging the Uniform Information Density principle. Through this principled study, we enable the adoption of textual gradients in FL for optimizing LLMs, identify important issues, and pinpoint future directions, thereby opening up a new research area that warrants further investigation.
DARE the Extreme: Revisiting Delta-Parameter Pruning For Fine-Tuned Models
Oct 12, 2024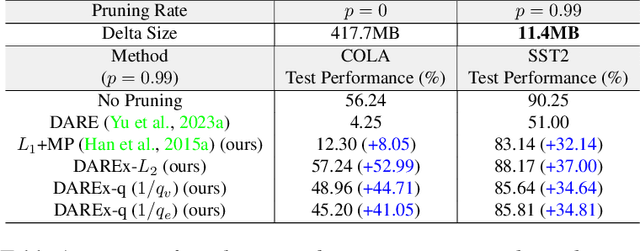
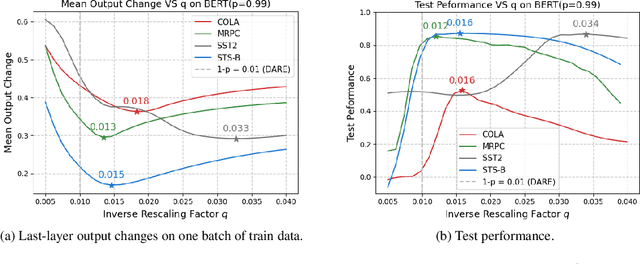
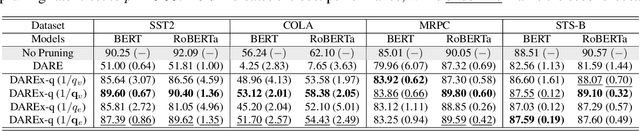
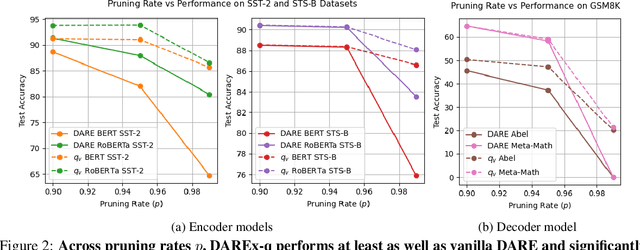
Storing open-source fine-tuned models separately introduces redundancy and increases response times in applications utilizing multiple models. Delta-parameter pruning (DPP), particularly the random drop and rescale (DARE) method proposed by Yu et al., addresses this by pruning the majority of delta parameters--the differences between fine-tuned and pre-trained model weights--while typically maintaining minimal performance loss. However, DARE fails when either the pruning rate or the magnitude of the delta parameters is large. We highlight two key reasons for this failure: (1) an excessively large rescaling factor as pruning rates increase, and (2) high mean and variance in the delta parameters. To push DARE's limits, we introduce DAREx (DARE the eXtreme), which features two algorithmic improvements: (1) DAREx-q, a rescaling factor modification that significantly boosts performance at high pruning rates (e.g., >30 % on COLA and SST2 for encoder models, with even greater gains in decoder models), and (2) DAREx-L2, which combines DARE with AdamR, an in-training method that applies appropriate delta regularization before DPP. We also demonstrate that DAREx-q can be seamlessly combined with vanilla parameter-efficient fine-tuning techniques like LoRA and can facilitate structural DPP. Additionally, we revisit the application of importance-based pruning techniques within DPP, demonstrating that they outperform random-based methods when delta parameters are large. Through this comprehensive study, we develop a pipeline for selecting the most appropriate DPP method under various practical scenarios.