 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Loss Re-weighting Works If You Stop Early: Training Dynamics of Unconstrained Features
Jan 17, 2026The application of loss reweighting in modern deep learning presents a nuanced picture. While it fails to alter the terminal learning phase in overparameterized deep neural networks (DNNs) trained on high-dimensional datasets, empirical evidence consistently shows it offers significant benefits early in training. To transparently demonstrate and analyze this phenomenon, we introduce a small-scale model (SSM). This model is specifically designed to abstract the inherent complexities of both the DNN architecture and the input data, while maintaining key information about the structure of imbalance within its spectral components. On the one hand, the SSM reveals how vanilla empirical risk minimization preferentially learns to distinguish majority classes over minorities early in training, consequently delaying minority learning. In stark contrast, reweighting restores balanced learning dynamics, enabling the simultaneous learning of features associated with both majorities and minorities.
How Muon's Spectral Design Benefits Generalization: A Study on Imbalanced Data
Oct 27, 2025



The growing adoption of spectrum-aware matrix-valued optimizers such as Muon and Shampoo in deep learning motivates a systematic study of their generalization properties and, in particular, when they might outperform competitive algorithms. We approach this question by introducing appropriate simplifying abstractions as follows: First, we use imbalanced data as a testbed. Second, we study the canonical form of such optimizers, which is Spectral Gradient Descent (SpecGD) -- each update step is $UV^T$ where $U\Sigma V^T$ is the truncated SVD of the gradient. Third, within this framework we identify a canonical setting for which we precisely quantify when SpecGD outperforms vanilla Euclidean GD. For a Gaussian mixture data model and both linear and bilinear models, we show that unlike GD, which prioritizes learning dominant principal components of the data first, SpecGD learns all principal components of the data at equal rates. We demonstrate how this translates to a growing gap in balanced accuracy favoring SpecGD early in training and further show that the gap remains consistent even when the GD counterpart uses adaptive step-sizes via normalization. By extending the analysis to deep linear models, we show that depth amplifies these effects. We empirically verify our theoretical findings on a variety of imbalanced datasets. Our experiments compare practical variants of spectral methods, like Muon and Shampoo, against their Euclidean counterparts and Adam. The results validate our findings that these spectral optimizers achieve superior generalization by promoting a more balanced learning of the data's underlying components.
On the Geometry of Semantics in Next-token Prediction
May 13, 2025Modern language models demonstrate a remarkable ability to capture linguistic meaning despite being trained solely through next-token prediction (NTP). We investigate how this conceptually simple training objective leads models to extract and encode latent semantic and grammatical concepts. Our analysis reveals that NTP optimization implicitly guides models to encode concepts via singular value decomposition (SVD) factors of a centered data-sparsity matrix that captures next-word co-occurrence patterns. While the model never explicitly constructs this matrix, learned word and context embeddings effectively factor it to capture linguistic structure. We find that the most important SVD factors are learned first during training, motivating the use of spectral clustering of embeddings to identify human-interpretable semantics, including both classical k-means and a new orthant-based method directly motivated by our interpretation of concepts. Overall, our work bridges distributional semantics, neural collapse geometry, and neural network training dynamics, providing insights into how NTP's implicit biases shape the emergence of meaning representations in language models.
DARE the Extreme: Revisiting Delta-Parameter Pruning For Fine-Tuned Models
Oct 12, 2024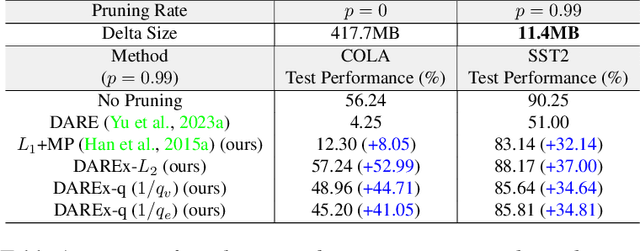
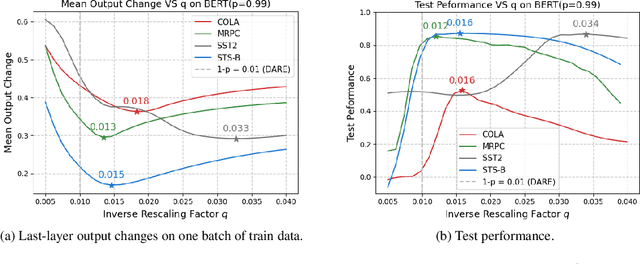
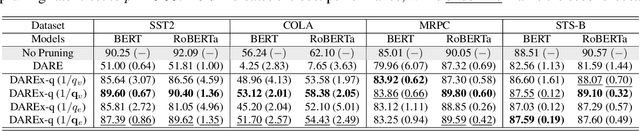
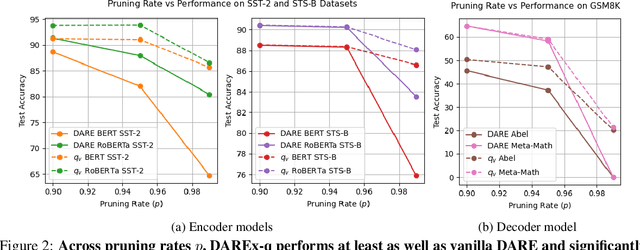
Storing open-source fine-tuned models separately introduces redundancy and increases response times in applications utilizing multiple models. Delta-parameter pruning (DPP), particularly the random drop and rescale (DARE) method proposed by Yu et al., addresses this by pruning the majority of delta parameters--the differences between fine-tuned and pre-trained model weights--while typically maintaining minimal performance loss. However, DARE fails when either the pruning rate or the magnitude of the delta parameters is large. We highlight two key reasons for this failure: (1) an excessively large rescaling factor as pruning rates increase, and (2) high mean and variance in the delta parameters. To push DARE's limits, we introduce DAREx (DARE the eXtreme), which features two algorithmic improvements: (1) DAREx-q, a rescaling factor modification that significantly boosts performance at high pruning rates (e.g., >30 % on COLA and SST2 for encoder models, with even greater gains in decoder models), and (2) DAREx-L2, which combines DARE with AdamR, an in-training method that applies appropriate delta regularization before DPP. We also demonstrate that DAREx-q can be seamlessly combined with vanilla parameter-efficient fine-tuning techniques like LoRA and can facilitate structural DPP. Additionally, we revisit the application of importance-based pruning techniques within DPP, demonstrating that they outperform random-based methods when delta parameters are large. Through this comprehensive study, we develop a pipeline for selecting the most appropriate DPP method under various practical scenarios.
Implicit Geometry of Next-token Prediction: From Language Sparsity Patterns to Model Representations
Aug 27, 2024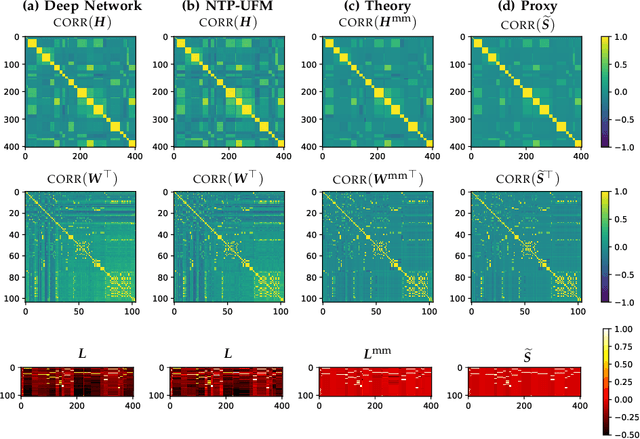
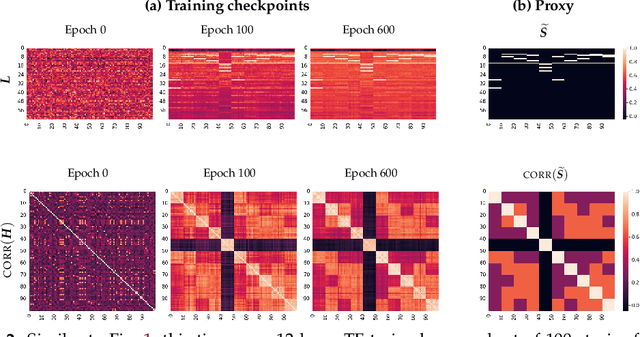
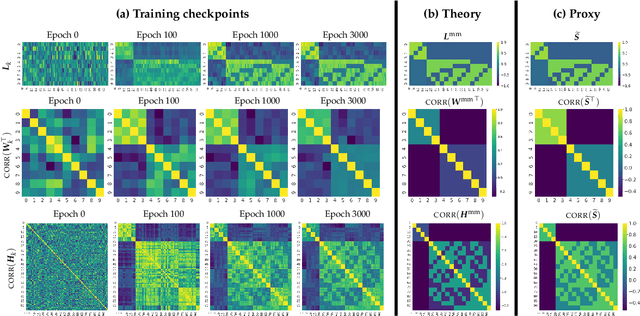

Next-token prediction (NTP) over large text corpora has become the go-to paradigm to train large language models. Yet, it remains unclear how NTP influences the mapping of linguistic patterns to geometric properties of the resulting model representations. We frame training of large language models as soft-label classification over sparse probabilistic label vectors, coupled with an analytical approximation that allows unrestricted generation of context embeddings. This approach links NTP training to rank-constrained, nuclear-norm regularized optimization in the logit domain, offering a framework for analyzing the geometry of word and context embeddings. In large embedding spaces, we find that NTP implicitly favors learning logits with a sparse plus low-rank structure. While the sparse component captures the co-occurrence frequency of context-word pairs, the orthogonal low-rank component, which becomes dominant as training progresses, depends solely on the sparsity pattern of the co-occurrence matrix. Consequently, when projected onto an appropriate subspace, representations of contexts that are followed by the same set of next-tokens collapse, a phenomenon we term subspace-collapse. We validate our findings on synthetic and small-scale real language datasets. Finally, we outline potential research directions aimed at deepening the understanding of NTP's influence on the learning of linguistic patterns and regularities.
Learnable Community-Aware Transformer for Brain Connectome Analysis with Token Clustering
Mar 13, 2024Neuroscientific research has revealed that the complex brain network can be organized into distinct functional communities, each characterized by a cohesive group of regions of interest (ROIs) with strong interconnections. These communities play a crucial role in comprehending the functional organization of the brain and its implications for neurological conditions, including Autism Spectrum Disorder (ASD) and biological differences, such as in gender. Traditional models have been constrained by the necessity of predefined community clusters, limiting their flexibility and adaptability in deciphering the brain's functional organization. Furthermore, these models were restricted by a fixed number of communities, hindering their ability to accurately represent the brain's dynamic nature. In this study, we present a token clustering brain transformer-based model ($\texttt{TC-BrainTF}$) for joint community clustering and classification. Our approach proposes a novel token clustering (TC) module based on the transformer architecture, which utilizes learnable prompt tokens with orthogonal loss where each ROI embedding is projected onto the prompt embedding space, effectively clustering ROIs into communities and reducing the dimensions of the node representation via merging with communities. Our results demonstrate that our learnable community-aware model $\texttt{TC-BrainTF}$ offers improved accuracy in identifying ASD and classifying genders through rigorous testing on ABIDE and HCP datasets. Additionally, the qualitative analysis on $\texttt{TC-BrainTF}$ has demonstrated the effectiveness of the designed TC module and its relevance to neuroscience interpretations.
Learning High-Order Relationships of Brain Regions
Dec 02, 2023Discovering reliable and informative interactions among brain regions from functional magnetic resonance imaging (fMRI) signals is essential in neuroscientific predictions of cognition. Most of the current methods fail to accurately characterize those interactions because they only focus on pairwise connections and overlook the high-order relationships of brain regions. We delve into this problem and argue that these high-order relationships should be maximally informative and minimally redundant (MIMR). However, identifying such high-order relationships is challenging and highly under-explored. Methods that can be tailored to our context are also non-existent. In response to this gap, we propose a novel method named HyBRiD that aims to extract MIMR high-order relationships from fMRI data. HyBRiD employs a Constructor to identify hyperedge structures, and a Weighter to compute a weight for each hyperedge. HyBRiD achieves the MIMR objective through an innovative information bottleneck framework named multi-head drop-bottleneck with theoretical guarantees. Our comprehensive experiments demonstrate the effectiveness of our model. Our model outperforms the state-of-the-art predictive model by an average of 12.1%, regarding the quality of hyperedges measured by CPM, a standard protocol for studying brain connections.
Pursuing Sources of Heterogeneity in Modeling Clustered Population
Mar 10, 2020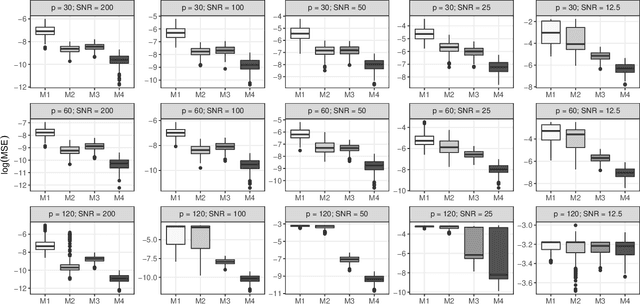
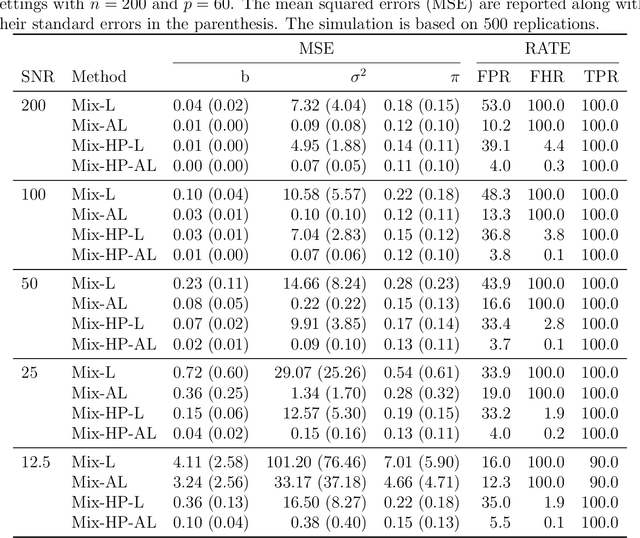
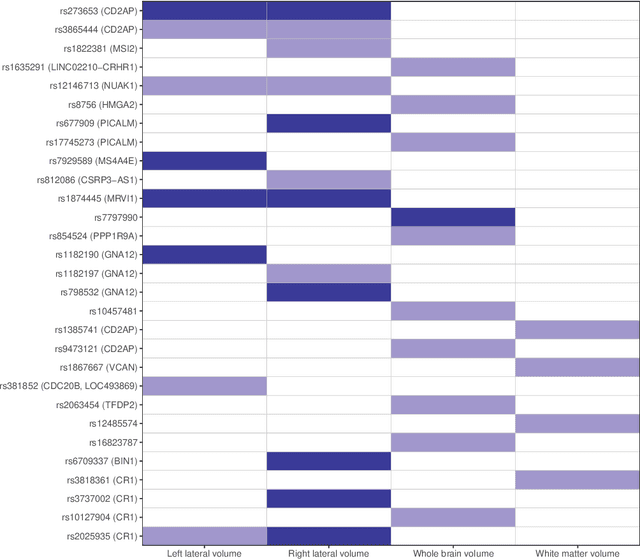

Researchers often have to deal with heterogeneous population with mixed regression relationships, increasingly so in the era of data explosion. In such problems, when there are many candidate predictors, it is not only of interest to identify the predictors that are associated with the outcome, but also to distinguish the true sources of heterogeneity, i.e., to identify the predictors that have different effects among the clusters and thus are the true contributors to the formation of the clusters. We clarify the concepts of the source of heterogeneity that account for potential scale differences of the clusters and propose a regularized finite mixture effects regression to achieve heterogeneity pursuit and feature selection simultaneously. As the name suggests, the problem is formulated under an effects-model parameterization, in which the cluster labels are missing and the effect of each predictor on the outcome is decomposed to a common effect term and a set of cluster-specific terms. A constrained sparse estimation of these effects leads to the identification of both the variables with common effects and those with heterogeneous effects. We propose an efficient algorithm and show that our approach can achieve both estimation and selection consistency. Simulation studies further demonstrate the effectiveness of our method under various practical scenarios. Three applications are presented, namely, an imaging genetics study for linking genetic factors and brain neuroimaging traits in Alzheimer's disease, a public health study for exploring the association between suicide risk among adolescents and their school district characteristics, and a sport analytics study for understanding how the salary levels of baseball players are associated with their performance and contractual status.