 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Occam's Razor: How Transformers Prefer Simpler Hypotheses on the Fly
Jun 24, 2025In-context learning (ICL) enables transformers to adapt to new tasks through contextual examples without parameter updates. While existing research has typically studied ICL in fixed-complexity environments, practical language models encounter tasks spanning diverse complexity levels. This paper investigates how transformers navigate hierarchical task structures where higher-complexity categories can perfectly represent any pattern generated by simpler ones. We design well-controlled testbeds based on Markov chains and linear regression that reveal transformers not only identify the appropriate complexity level for each task but also accurately infer the corresponding parameters--even when the in-context examples are compatible with multiple complexity hypotheses. Notably, when presented with data generated by simpler processes, transformers consistently favor the least complex sufficient explanation. We theoretically explain this behavior through a Bayesian framework, demonstrating that transformers effectively implement an in-context Bayesian Occam's razor by balancing model fit against complexity penalties. We further ablate on the roles of model size, training mixture distribution, inference context length, and architecture. Finally, we validate this Occam's razor-like inductive bias on a pretrained GPT-4 model with Boolean-function tasks as case study, suggesting it may be inherent to transformers trained on diverse task distributions.
Implicit Geometry of Next-token Prediction: From Language Sparsity Patterns to Model Representations
Aug 27, 2024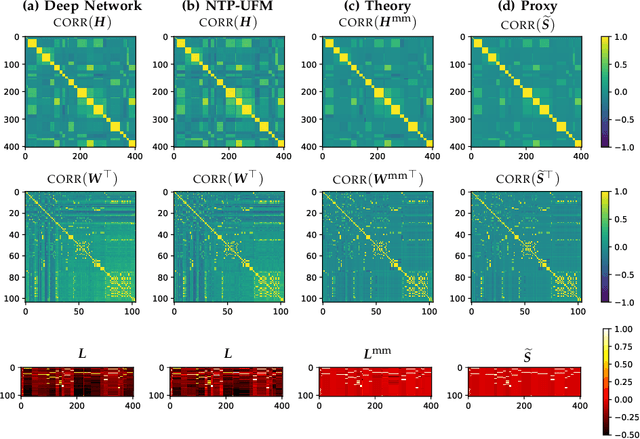
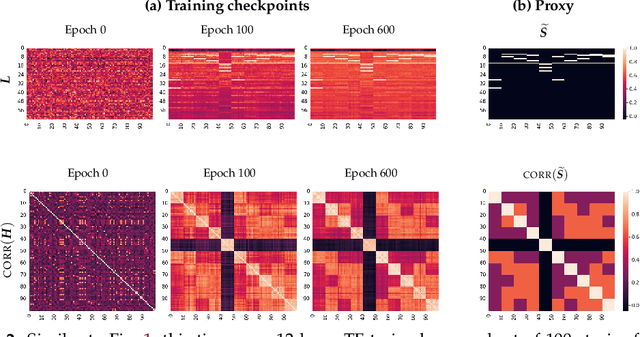
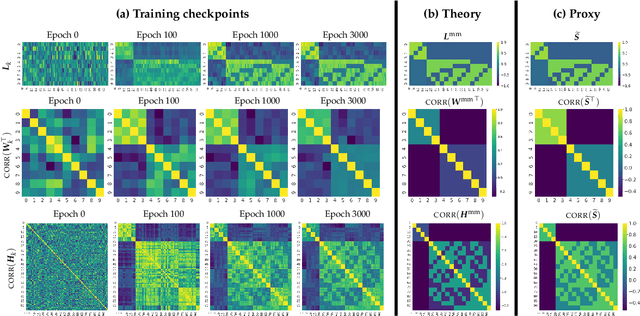

Next-token prediction (NTP) over large text corpora has become the go-to paradigm to train large language models. Yet, it remains unclear how NTP influences the mapping of linguistic patterns to geometric properties of the resulting model representations. We frame training of large language models as soft-label classification over sparse probabilistic label vectors, coupled with an analytical approximation that allows unrestricted generation of context embeddings. This approach links NTP training to rank-constrained, nuclear-norm regularized optimization in the logit domain, offering a framework for analyzing the geometry of word and context embeddings. In large embedding spaces, we find that NTP implicitly favors learning logits with a sparse plus low-rank structure. While the sparse component captures the co-occurrence frequency of context-word pairs, the orthogonal low-rank component, which becomes dominant as training progresses, depends solely on the sparsity pattern of the co-occurrence matrix. Consequently, when projected onto an appropriate subspace, representations of contexts that are followed by the same set of next-tokens collapse, a phenomenon we term subspace-collapse. We validate our findings on synthetic and small-scale real language datasets. Finally, we outline potential research directions aimed at deepening the understanding of NTP's influence on the learning of linguistic patterns and regularities.
Supervised Contrastive Representation Learning: Landscape Analysis with Unconstrained Features
Feb 29, 2024Recent findings reveal that over-parameterized deep neural networks, trained beyond zero training-error, exhibit a distinctive structural pattern at the final layer, termed as Neural-collapse (NC). These results indicate that the final hidden-layer outputs in such networks display minimal within-class variations over the training set. While existing research extensively investigates this phenomenon under cross-entropy loss, there are fewer studies focusing on its contrastive counterpart, supervised contrastive (SC) loss. Through the lens of NC, this paper employs an analytical approach to study the solutions derived from optimizing the SC loss. We adopt the unconstrained features model (UFM) as a representative proxy for unveiling NC-related phenomena in sufficiently over-parameterized deep networks. We show that, despite the non-convexity of SC loss minimization, all local minima are global minima. Furthermore, the minimizer is unique (up to a rotation). We prove our results by formalizing a tight convex relaxation of the UFM. Finally, through this convex formulation, we delve deeper into characterizing the properties of global solutions under label-imbalanced training data.
Supervised-Contrastive Loss Learns Orthogonal Frames and Batching Matters
Jun 13, 2023



Supervised contrastive loss (SCL) is a competitive and often superior alternative to the cross-entropy (CE) loss for classification. In this paper we ask: what differences in the learning process occur when the two different loss functions are being optimized? To answer this question, our main finding is that the geometry of embeddings learned by SCL forms an orthogonal frame (OF) regardless of the number of training examples per class. This is in contrast to the CE loss, for which previous work has shown that it learns embeddings geometries that are highly dependent on the class sizes. We arrive at our finding theoretically, by proving that the global minimizers of an unconstrained features model with SCL loss and entry-wise non-negativity constraints form an OF. We then validate the model's prediction by conducting experiments with standard deep-learning models on benchmark vision datasets. Finally, our analysis and experiments reveal that the batching scheme chosen during SCL training plays a critical role in determining the quality of convergence to the OF geometry. This finding motivates a simple algorithm wherein the addition of a few binding examples in each batch significantly speeds up the occurrence of the OF geometry.
On the Implicit Geometry of Cross-Entropy Parameterizations for Label-Imbalanced Data
Mar 14, 2023Various logit-adjusted parameterizations of the cross-entropy (CE) loss have been proposed as alternatives to weighted CE for training large models on label-imbalanced data far beyond the zero train error regime. The driving force behind those designs has been the theory of implicit bias, which for linear(ized) models, explains why they successfully induce bias on the optimization path towards solutions that favor minorities. Aiming to extend this theory to non-linear models, we investigate the implicit geometry of classifiers and embeddings that are learned by different CE parameterizations. Our main result characterizes the global minimizers of a non-convex cost-sensitive SVM classifier for the unconstrained features model, which serves as an abstraction of deep nets. We derive closed-form formulas for the angles and norms of classifiers and embeddings as a function of the number of classes, the imbalance and the minority ratios, and the loss hyperparameters. Using these, we show that logit-adjusted parameterizations can be appropriately tuned to learn symmetric geometries irrespective of the imbalance ratio. We complement our analysis with experiments and an empirical study of convergence accuracy in deep-nets.
Imbalance Trouble: Revisiting Neural-Collapse Geometry
Aug 10, 2022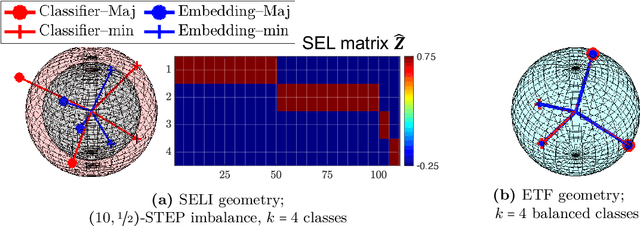

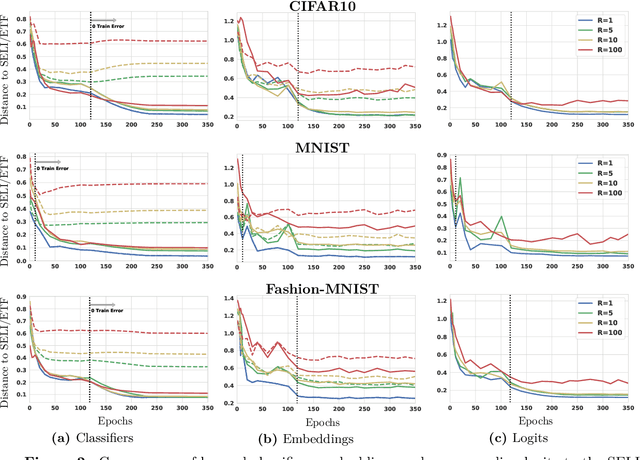
Neural Collapse refers to the remarkable structural properties characterizing the geometry of class embeddings and classifier weights, found by deep nets when trained beyond zero training error. However, this characterization only holds for balanced data. Here we thus ask whether it can be made invariant to class imbalances. Towards this end, we adopt the unconstrained-features model (UFM), a recent theoretical model for studying neural collapse, and introduce Simplex-Encoded-Labels Interpolation (SELI) as an invariant characterization of the neural collapse phenomenon. Specifically, we prove for the UFM with cross-entropy loss and vanishing regularization that, irrespective of class imbalances, the embeddings and classifiers always interpolate a simplex-encoded label matrix and that their individual geometries are determined by the SVD factors of this same label matrix. We then present extensive experiments on synthetic and real datasets that confirm convergence to the SELI geometry. However, we caution that convergence worsens with increasing imbalances. We theoretically support this finding by showing that unlike the balanced case, when minorities are present, ridge-regularization plays a critical role in tweaking the geometry. This defines new questions and motivates further investigations into the impact of class imbalances on the rates at which first-order methods converge to their asymptotically preferred solutions.
On how to avoid exacerbating spurious correlations when models are overparameterized
Jun 25, 2022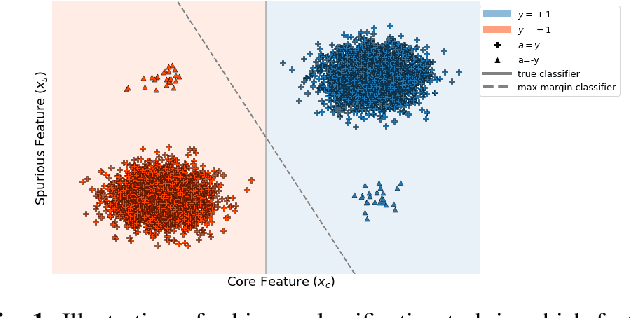
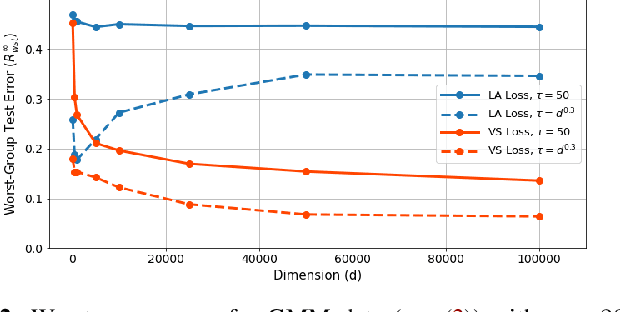
Overparameterized models fail to generalize well in the presence of data imbalance even when combined with traditional techniques for mitigating imbalances. This paper focuses on imbalanced classification datasets, in which a small subset of the population -- a minority -- may contain features that correlate spuriously with the class label. For a parametric family of cross-entropy loss modifications and a representative Gaussian mixture model, we derive non-asymptotic generalization bounds on the worst-group error that shed light on the role of different hyper-parameters. Specifically, we prove that, when appropriately tuned, the recently proposed VS-loss learns a model that is fair towards minorities even when spurious features are strong. On the other hand, alternative heuristics, such as the weighted CE and the LA-loss, can fail dramatically. Compared to previous works, our bounds hold for more general models, they are non-asymptotic, and, they apply even at scenarios of extreme imbalance.