 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn how to avoid exacerbating spurious correlations when models are overparameterized
Paper and Code
Jun 25, 2022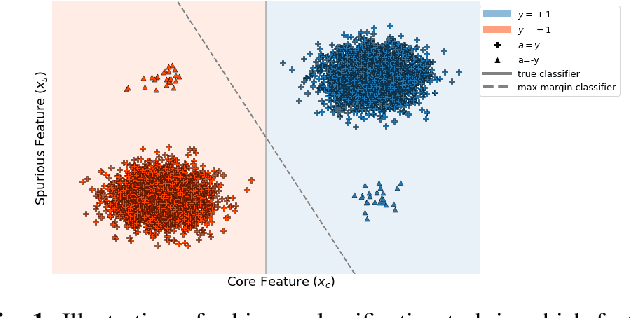
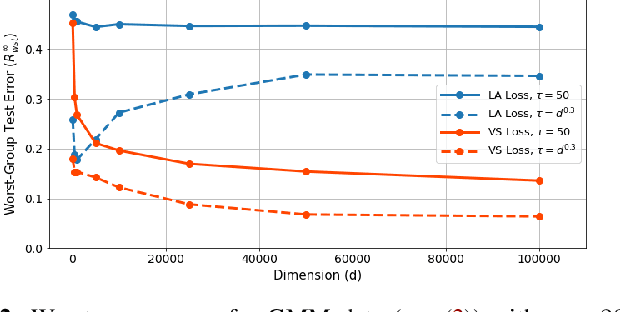
Overparameterized models fail to generalize well in the presence of data imbalance even when combined with traditional techniques for mitigating imbalances. This paper focuses on imbalanced classification datasets, in which a small subset of the population -- a minority -- may contain features that correlate spuriously with the class label. For a parametric family of cross-entropy loss modifications and a representative Gaussian mixture model, we derive non-asymptotic generalization bounds on the worst-group error that shed light on the role of different hyper-parameters. Specifically, we prove that, when appropriately tuned, the recently proposed VS-loss learns a model that is fair towards minorities even when spurious features are strong. On the other hand, alternative heuristics, such as the weighted CE and the LA-loss, can fail dramatically. Compared to previous works, our bounds hold for more general models, they are non-asymptotic, and, they apply even at scenarios of extreme imbalance.