 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised-Contrastive Loss Learns Orthogonal Frames and Batching Matters
Jun 13, 2023



Supervised contrastive loss (SCL) is a competitive and often superior alternative to the cross-entropy (CE) loss for classification. In this paper we ask: what differences in the learning process occur when the two different loss functions are being optimized? To answer this question, our main finding is that the geometry of embeddings learned by SCL forms an orthogonal frame (OF) regardless of the number of training examples per class. This is in contrast to the CE loss, for which previous work has shown that it learns embeddings geometries that are highly dependent on the class sizes. We arrive at our finding theoretically, by proving that the global minimizers of an unconstrained features model with SCL loss and entry-wise non-negativity constraints form an OF. We then validate the model's prediction by conducting experiments with standard deep-learning models on benchmark vision datasets. Finally, our analysis and experiments reveal that the batching scheme chosen during SCL training plays a critical role in determining the quality of convergence to the OF geometry. This finding motivates a simple algorithm wherein the addition of a few binding examples in each batch significantly speeds up the occurrence of the OF geometry.
On the Implicit Geometry of Cross-Entropy Parameterizations for Label-Imbalanced Data
Mar 14, 2023Various logit-adjusted parameterizations of the cross-entropy (CE) loss have been proposed as alternatives to weighted CE for training large models on label-imbalanced data far beyond the zero train error regime. The driving force behind those designs has been the theory of implicit bias, which for linear(ized) models, explains why they successfully induce bias on the optimization path towards solutions that favor minorities. Aiming to extend this theory to non-linear models, we investigate the implicit geometry of classifiers and embeddings that are learned by different CE parameterizations. Our main result characterizes the global minimizers of a non-convex cost-sensitive SVM classifier for the unconstrained features model, which serves as an abstraction of deep nets. We derive closed-form formulas for the angles and norms of classifiers and embeddings as a function of the number of classes, the imbalance and the minority ratios, and the loss hyperparameters. Using these, we show that logit-adjusted parameterizations can be appropriately tuned to learn symmetric geometries irrespective of the imbalance ratio. We complement our analysis with experiments and an empirical study of convergence accuracy in deep-nets.
Label-Imbalanced and Group-Sensitive Classification under Overparameterization
Mar 02, 2021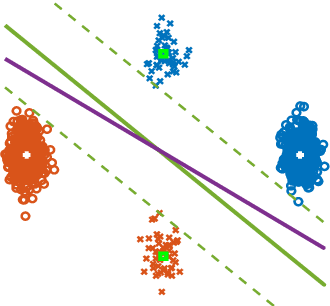


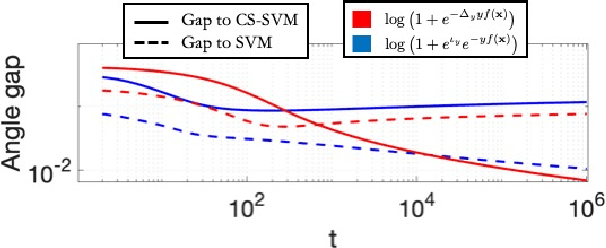
Label-imbalanced and group-sensitive classification seeks to appropriately modify standard training algorithms to optimize relevant metrics such as balanced error and/or equal opportunity. For label imbalances, recent works have proposed a logit-adjusted loss modification to standard empirical risk minimization. We show that this might be ineffective in general and, in particular so, in the overparameterized regime where training continues in the zero training-error regime. Specifically for binary linear classification of a separable dataset, we show that the modified loss converges to the max-margin SVM classifier despite the logit adjustment. Instead, we propose a more general vector-scaling loss that directly relates to the cost-sensitive SVM (CS-SVM), thus favoring larger margin to the minority class. Through an insightful sharp asymptotic analysis for a Gaussian-mixtures data model, we demonstrate the efficacy of CS-SVM in balancing the errors of the minority/majority classes. Our analysis also leads to a simple strategy for optimally tuning the involved margin-ratio parameter. Then, we show how our results extend naturally to binary classification with sensitive groups, thus treating the two common types of imbalances (label/group) in a unifying way. We corroborate our theoretical findings with numerical experiments on both synthetic and real-world datasets.