 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-Imbalanced and Group-Sensitive Classification under Overparameterization
Paper and Code
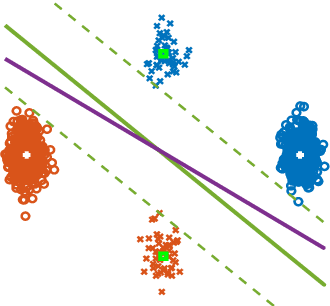


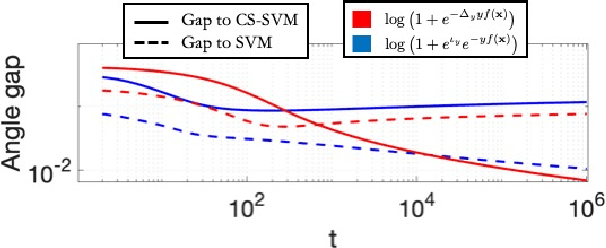
Label-imbalanced and group-sensitive classification seeks to appropriately modify standard training algorithms to optimize relevant metrics such as balanced error and/or equal opportunity. For label imbalances, recent works have proposed a logit-adjusted loss modification to standard empirical risk minimization. We show that this might be ineffective in general and, in particular so, in the overparameterized regime where training continues in the zero training-error regime. Specifically for binary linear classification of a separable dataset, we show that the modified loss converges to the max-margin SVM classifier despite the logit adjustment. Instead, we propose a more general vector-scaling loss that directly relates to the cost-sensitive SVM (CS-SVM), thus favoring larger margin to the minority class. Through an insightful sharp asymptotic analysis for a Gaussian-mixtures data model, we demonstrate the efficacy of CS-SVM in balancing the errors of the minority/majority classes. Our analysis also leads to a simple strategy for optimally tuning the involved margin-ratio parameter. Then, we show how our results extend naturally to binary classification with sensitive groups, thus treating the two common types of imbalances (label/group) in a unifying way. We corroborate our theoretical findings with numerical experiments on both synthetic and real-world datasets.