 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponentially Convergent Algorithms for Supervised Matrix Factorization
Nov 18, 2023


Supervised matrix factorization (SMF) is a classical machine learning method that simultaneously seeks feature extraction and classification tasks, which are not necessarily a priori aligned objectives. Our goal is to use SMF to learn low-rank latent factors that offer interpretable, data-reconstructive, and class-discriminative features, addressing challenges posed by high-dimensional data. Training SMF model involves solving a nonconvex and possibly constrained optimization with at least three blocks of parameters. Known algorithms are either heuristic or provide weak convergence guarantees for special cases. In this paper, we provide a novel framework that 'lifts' SMF as a low-rank matrix estimation problem in a combined factor space and propose an efficient algorithm that provably converges exponentially fast to a global minimizer of the objective with arbitrary initialization under mild assumptions. Our framework applies to a wide range of SMF-type problems for multi-class classification with auxiliary features. To showcase an application, we demonstrate that our algorithm successfully identified well-known cancer-associated gene groups for various cancers.
* 33 pages, 3 figures. arXiv admin note: substantial text overlap with arXiv:2206.06774
Supervised Dictionary Learning with Auxiliary Covariates
Jun 14, 2022


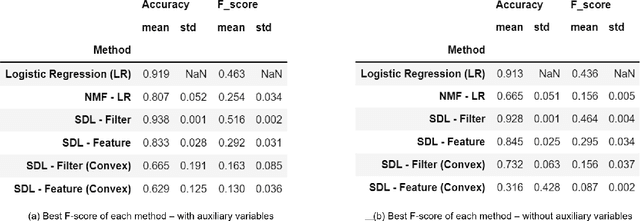
Supervised dictionary learning (SDL) is a classical machine learning method that simultaneously seeks feature extraction and classification tasks, which are not necessarily a priori aligned objectives. The goal of SDL is to learn a class-discriminative dictionary, which is a set of latent feature vectors that can well-explain both the features as well as labels of observed data. In this paper, we provide a systematic study of SDL, including the theory, algorithm, and applications of SDL. First, we provide a novel framework that `lifts' SDL as a convex problem in a combined factor space and propose a low-rank projected gradient descent algorithm that converges exponentially to the global minimizer of the objective. We also formulate generative models of SDL and provide global estimation guarantees of the true parameters depending on the hyperparameter regime. Second, viewed as a nonconvex constrained optimization problem, we provided an efficient block coordinate descent algorithm for SDL that is guaranteed to find an $\varepsilon$-stationary point of the objective in $O(\varepsilon^{-1}(\log \varepsilon^{-1})^{2})$ iterations. For the corresponding generative model, we establish a novel non-asymptotic local consistency result for constrained and regularized maximum likelihood estimation problems, which may be of independent interest. Third, we apply SDL for imbalanced document classification by supervised topic modeling and also for pneumonia detection from chest X-ray images. We also provide simulation studies to demonstrate that SDL becomes more effective when there is a discrepancy between the best reconstructive and the best discriminative dictionaries.
Pursuing Sources of Heterogeneity in Modeling Clustered Population
Mar 10, 2020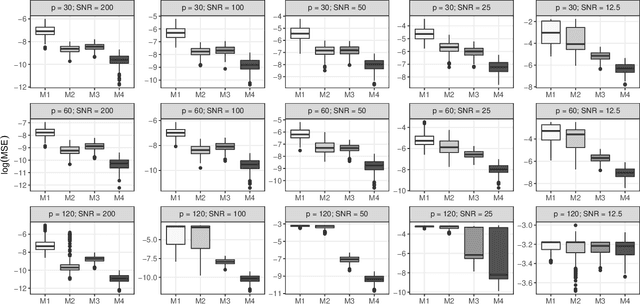
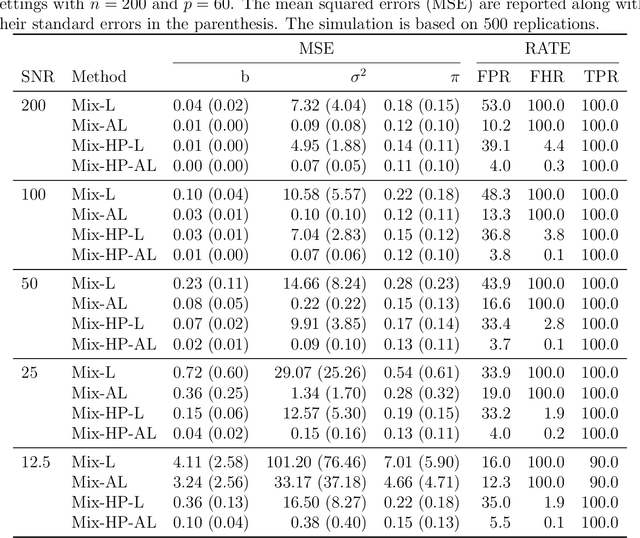
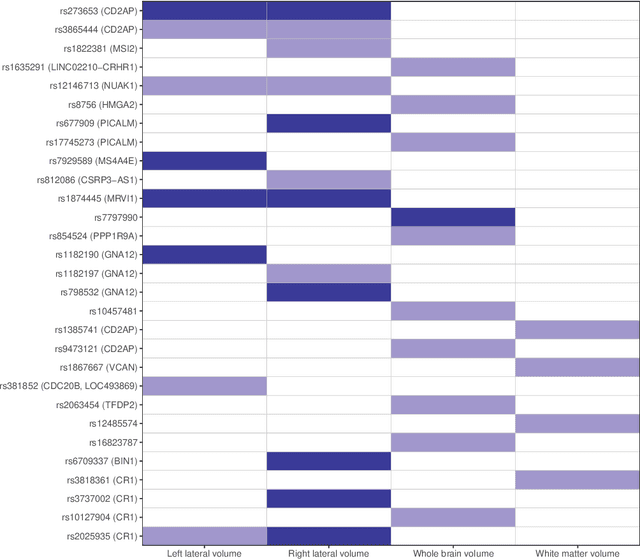

Researchers often have to deal with heterogeneous population with mixed regression relationships, increasingly so in the era of data explosion. In such problems, when there are many candidate predictors, it is not only of interest to identify the predictors that are associated with the outcome, but also to distinguish the true sources of heterogeneity, i.e., to identify the predictors that have different effects among the clusters and thus are the true contributors to the formation of the clusters. We clarify the concepts of the source of heterogeneity that account for potential scale differences of the clusters and propose a regularized finite mixture effects regression to achieve heterogeneity pursuit and feature selection simultaneously. As the name suggests, the problem is formulated under an effects-model parameterization, in which the cluster labels are missing and the effect of each predictor on the outcome is decomposed to a common effect term and a set of cluster-specific terms. A constrained sparse estimation of these effects leads to the identification of both the variables with common effects and those with heterogeneous effects. We propose an efficient algorithm and show that our approach can achieve both estimation and selection consistency. Simulation studies further demonstrate the effectiveness of our method under various practical scenarios. Three applications are presented, namely, an imaging genetics study for linking genetic factors and brain neuroimaging traits in Alzheimer's disease, a public health study for exploring the association between suicide risk among adolescents and their school district characteristics, and a sport analytics study for understanding how the salary levels of baseball players are associated with their performance and contractual status.
Fully Bayesian Logistic Regression with Hyper-Lasso Priors for High-dimensional Feature Selection
May 12, 2018
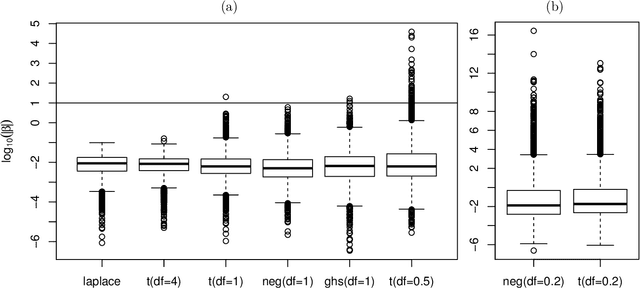
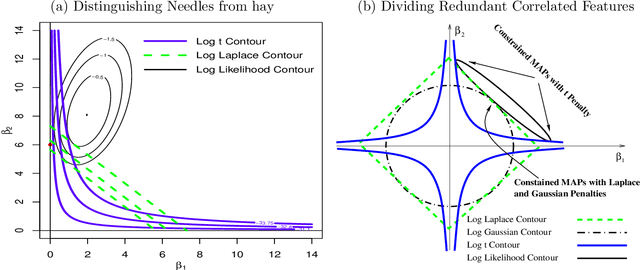
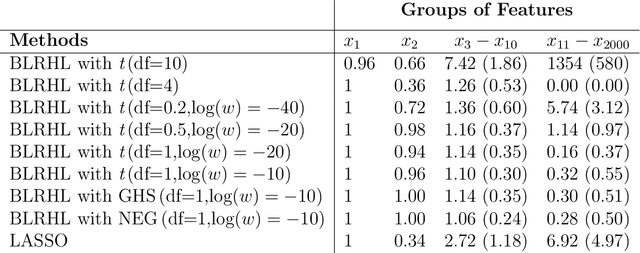
High-dimensional feature selection arises in many areas of modern science. For example, in genomic research we want to find the genes that can be used to separate tissues of different classes (e.g. cancer and normal) from tens of thousands of genes that are active (expressed) in certain tissue cells. To this end, we wish to fit regression and classification models with a large number of features (also called variables, predictors). In the past decade, penalized likelihood methods for fitting regression models based on hyper-LASSO penalization have received increasing attention in the literature. However, fully Bayesian methods that use Markov chain Monte Carlo (MCMC) are still in lack of development in the literature. In this paper we introduce an MCMC (fully Bayesian) method for learning severely multi-modal posteriors of logistic regression models based on hyper-LASSO priors (non-convex penalties). Our MCMC algorithm uses Hamiltonian Monte Carlo in a restricted Gibbs sampling framework; we call our method Bayesian logistic regression with hyper-LASSO (BLRHL) priors. We have used simulation studies and real data analysis to demonstrate the superior performance of hyper-LASSO priors, and to investigate the issues of choosing heaviness and scale of hyper-LASSO priors.
* 33 pages. arXiv admin note: substantial text overlap with arXiv:1308.4690