 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing and Utilizing In-group Favoritism for Graph-based Collaborative Filtering
Apr 23, 2024



When it comes to a personalized item recommendation system, It is essential to extract users' preferences and purchasing patterns. Assuming that users in the real world form a cluster and there is common favoritism in each cluster, in this work, we introduce Co-Clustering Wrapper (CCW). We compute co-clusters of users and items with co-clustering algorithms and add CF subnetworks for each cluster to extract the in-group favoritism. Combining the features from the networks, we obtain rich and unified information about users. We experimented real world datasets considering two aspects: Finding the number of groups divided according to in-group preference, and measuring the quantity of improvement of the performance.
Exponentially Convergent Algorithms for Supervised Matrix Factorization
Nov 18, 2023


Supervised matrix factorization (SMF) is a classical machine learning method that simultaneously seeks feature extraction and classification tasks, which are not necessarily a priori aligned objectives. Our goal is to use SMF to learn low-rank latent factors that offer interpretable, data-reconstructive, and class-discriminative features, addressing challenges posed by high-dimensional data. Training SMF model involves solving a nonconvex and possibly constrained optimization with at least three blocks of parameters. Known algorithms are either heuristic or provide weak convergence guarantees for special cases. In this paper, we provide a novel framework that 'lifts' SMF as a low-rank matrix estimation problem in a combined factor space and propose an efficient algorithm that provably converges exponentially fast to a global minimizer of the objective with arbitrary initialization under mild assumptions. Our framework applies to a wide range of SMF-type problems for multi-class classification with auxiliary features. To showcase an application, we demonstrate that our algorithm successfully identified well-known cancer-associated gene groups for various cancers.
* 33 pages, 3 figures. arXiv admin note: substantial text overlap with arXiv:2206.06774
Supervised Dictionary Learning with Auxiliary Covariates
Jun 14, 2022


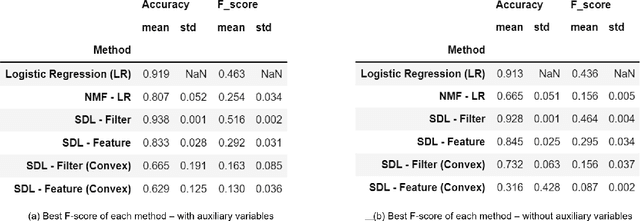
Supervised dictionary learning (SDL) is a classical machine learning method that simultaneously seeks feature extraction and classification tasks, which are not necessarily a priori aligned objectives. The goal of SDL is to learn a class-discriminative dictionary, which is a set of latent feature vectors that can well-explain both the features as well as labels of observed data. In this paper, we provide a systematic study of SDL, including the theory, algorithm, and applications of SDL. First, we provide a novel framework that `lifts' SDL as a convex problem in a combined factor space and propose a low-rank projected gradient descent algorithm that converges exponentially to the global minimizer of the objective. We also formulate generative models of SDL and provide global estimation guarantees of the true parameters depending on the hyperparameter regime. Second, viewed as a nonconvex constrained optimization problem, we provided an efficient block coordinate descent algorithm for SDL that is guaranteed to find an $\varepsilon$-stationary point of the objective in $O(\varepsilon^{-1}(\log \varepsilon^{-1})^{2})$ iterations. For the corresponding generative model, we establish a novel non-asymptotic local consistency result for constrained and regularized maximum likelihood estimation problems, which may be of independent interest. Third, we apply SDL for imbalanced document classification by supervised topic modeling and also for pneumonia detection from chest X-ray images. We also provide simulation studies to demonstrate that SDL becomes more effective when there is a discrepancy between the best reconstructive and the best discriminative dictionaries.