 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Are Tools Anyway? A Survey from the Language Model Perspective
Mar 18, 2024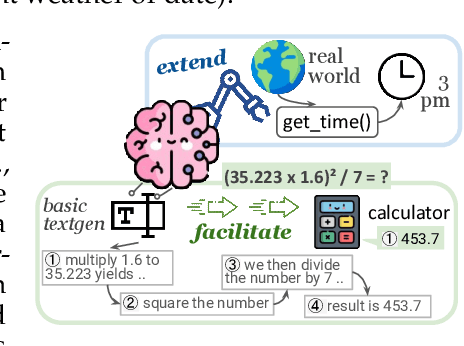
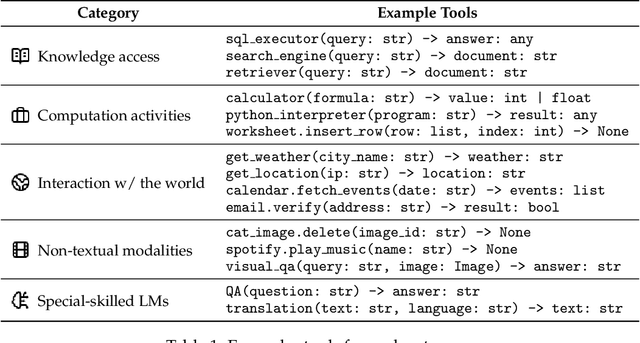
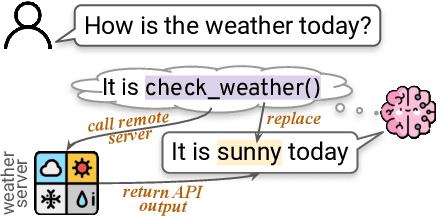
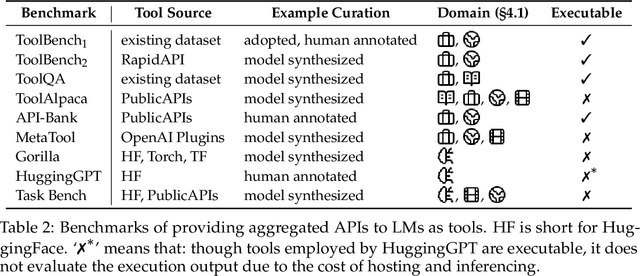
Language models (LMs) are powerful yet mostly for text generation tasks. Tools have substantially enhanced their performance for tasks that require complex skills. However, many works adopt the term "tool" in different ways, raising the question: What is a tool anyway? Subsequently, where and how do tools help LMs? In this survey, we provide a unified definition of tools as external programs used by LMs, and perform a systematic review of LM tooling scenarios and approaches. Grounded on this review, we empirically study the efficiency of various tooling methods by measuring their required compute and performance gains on various benchmarks, and highlight some challenges and potential future research in the field.
RAGGED: Towards Informed Design of Retrieval Augmented Generation Systems
Mar 14, 2024Retrieval-augmented generation (RAG) greatly benefits language models (LMs) by providing additional context for tasks such as document-based question answering (DBQA). Despite its potential, the power of RAG is highly dependent on its configuration, raising the question: What is the optimal RAG configuration? To answer this, we introduce the RAGGED framework to analyze and optimize RAG systems. On a set of representative DBQA tasks, we study two classic sparse and dense retrievers, and four top-performing LMs in encoder-decoder and decoder-only architectures. Through RAGGED, we uncover that different models suit substantially varied RAG setups. While encoder-decoder models monotonically improve with more documents, we find decoder-only models can only effectively use < 5 documents, despite often having a longer context window. RAGGED offers further insights into LMs' context utilization habits, where we find that encoder-decoder models rely more on contexts and are thus more sensitive to retrieval quality, while decoder-only models tend to rely on knowledge memorized during training.
TroVE: Inducing Verifiable and Efficient Toolboxes for Solving Programmatic Tasks
Jan 23, 2024Language models (LMs) can solve tasks such as answering questions about tables or images by writing programs. However, using primitive functions often leads to verbose and error-prone programs, and higher-level functions require expert design. To enable better solutions without human labor, we ask code LMs to curate reusable high-level functions, and use them to write solutions. We present TROVE, a training-free method of inducing a verifiable and efficient toolbox of functions, by generating via using, growing, and periodically trimming the toolbox. On 11 datasets from math, table question answering, and image reasoning tasks, TROVE consistently yields simpler solutions with higher accuracy than baselines using CODELLAMA and previous methods using GPT, while using 79-98% smaller toolboxes. TROVE further enables 31% faster and 13% more accurate human verification than baselines. With the same pipeline, it creates diverse functions for varied tasks and datasets, providing insights into their individual characteristics.
Learning to Filter Context for Retrieval-Augmented Generation
Nov 14, 2023On-the-fly retrieval of relevant knowledge has proven an essential element of reliable systems for tasks such as open-domain question answering and fact verification. However, because retrieval systems are not perfect, generation models are required to generate outputs given partially or entirely irrelevant passages. This can cause over- or under-reliance on context, and result in problems in the generated output such as hallucinations. To alleviate these problems, we propose FILCO, a method that improves the quality of the context provided to the generator by (1) identifying useful context based on lexical and information-theoretic approaches, and (2) training context filtering models that can filter retrieved contexts at test time. We experiment on six knowledge-intensive tasks with FLAN-T5 and LLaMa2, and demonstrate that our method outperforms existing approaches on extractive question answering (QA), complex multi-hop and long-form QA, fact verification, and dialog generation tasks. FILCO effectively improves the quality of context, whether or not it supports the canonical output.
API-Assisted Code Generation for Question Answering on Varied Table Structures
Oct 23, 2023



A persistent challenge to table question answering (TableQA) by generating executable programs has been adapting to varied table structures, typically requiring domain-specific logical forms. In response, this paper introduces a unified TableQA framework that: (1) provides a unified representation for structured tables as multi-index Pandas data frames, (2) uses Python as a powerful querying language, and (3) uses few-shot prompting to translate NL questions into Python programs, which are executable on Pandas data frames. Furthermore, to answer complex relational questions with extended program functionality and external knowledge, our framework allows customized APIs that Python programs can call. We experiment with four TableQA datasets that involve tables of different structures -- relational, multi-table, and hierarchical matrix shapes -- and achieve prominent improvements over past state-of-the-art systems. In ablation studies, we (1) show benefits from our multi-index representation and APIs over baselines that use only an LLM, and (2) demonstrate that our approach is modular and can incorporate additional APIs.
Improving Factuality of Abstractive Summarization via Contrastive Reward Learning
Jul 10, 2023Modern abstractive summarization models often generate summaries that contain hallucinated or contradictory information. In this paper, we propose a simple but effective contrastive learning framework that incorporates recent developments in reward learning and factuality metrics. Empirical studies demonstrate that the proposed framework enables summarization models to learn from feedback of factuality metrics using contrastive reward learning, leading to more factual summaries by human evaluations. This suggests that further advances in learning and evaluation algorithms can feed directly into providing more factual summaries.
SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Jul 03, 2023



In this work, we introduce Semantic Pyramid AutoEncoder (SPAE) for enabling frozen LLMs to perform both understanding and generation tasks involving non-linguistic modalities such as images or videos. SPAE converts between raw pixels and interpretable lexical tokens (or words) extracted from the LLM's vocabulary. The resulting tokens capture both the semantic meaning and the fine-grained details needed for visual reconstruction, effectively translating the visual content into a language comprehensible to the LLM, and empowering it to perform a wide array of multimodal tasks. Our approach is validated through in-context learning experiments with frozen PaLM 2 and GPT 3.5 on a diverse set of image understanding and generation tasks. Our method marks the first successful attempt to enable a frozen LLM to generate image content while surpassing state-of-the-art performance in image understanding tasks, under the same setting, by over 25%.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Execution-Based Evaluation for Open-Domain Code Generation
Dec 20, 2022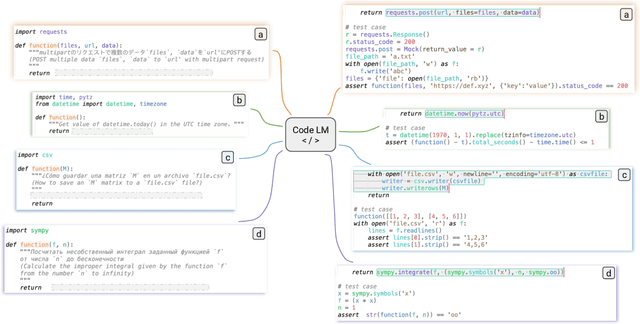
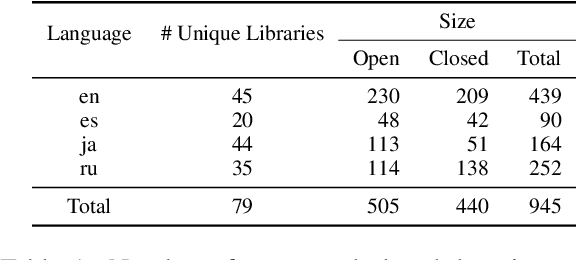

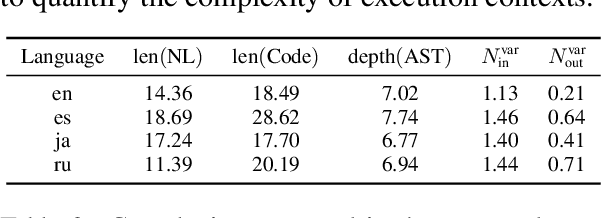
To extend the scope of coding queries to more realistic settings, we propose ODEX, the first open-domain execution-based natural language (NL) to code generation dataset. ODEX has 945 NL-Code pairs spanning 79 diverse libraries, along with 1,707 human-written test cases for execution. Our NL-Code pairs are harvested from StackOverflow forums to encourage natural and practical coding queries, which are then carefully rephrased to ensure intent clarity and prevent potential data memorization. Moreover, ODEX supports four natural languages as intents, in English, Spanish, Japanese, and Russian. ODEX unveils intriguing behavioral differences between top-performing Code LMs: Codex performs better on open-domain queries, yet CodeGen captures a better balance between open- and closed-domain. ODEX corroborates the merits of execution-based evaluation over metrics without execution but also unveils their complementary effects. Powerful models such as CodeGen-6B only achieve an 11.96 pass rate at top-1 prediction, suggesting plenty of headroom for improvement. We release ODEX to facilitate research into open-domain problems for the code generation community.
Retrieval as Attention: End-to-end Learning of Retrieval and Reading within a Single Transformer
Dec 05, 2022



Systems for knowledge-intensive tasks such as open-domain question answering (QA) usually consist of two stages: efficient retrieval of relevant documents from a large corpus and detailed reading of the selected documents to generate answers. Retrievers and readers are usually modeled separately, which necessitates a cumbersome implementation and is hard to train and adapt in an end-to-end fashion. In this paper, we revisit this design and eschew the separate architecture and training in favor of a single Transformer that performs Retrieval as Attention (ReAtt), and end-to-end training solely based on supervision from the end QA task. We demonstrate for the first time that a single model trained end-to-end can achieve both competitive retrieval and QA performance, matching or slightly outperforming state-of-the-art separately trained retrievers and readers. Moreover, end-to-end adaptation significantly boosts its performance on out-of-domain datasets in both supervised and unsupervised settings, making our model a simple and adaptable solution for knowledge-intensive tasks. Code and models are available at https://github.com/jzbjyb/ReAtt.