 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGGED: Towards Informed Design of Retrieval Augmented Generation Systems
Mar 14, 2024Retrieval-augmented generation (RAG) greatly benefits language models (LMs) by providing additional context for tasks such as document-based question answering (DBQA). Despite its potential, the power of RAG is highly dependent on its configuration, raising the question: What is the optimal RAG configuration? To answer this, we introduce the RAGGED framework to analyze and optimize RAG systems. On a set of representative DBQA tasks, we study two classic sparse and dense retrievers, and four top-performing LMs in encoder-decoder and decoder-only architectures. Through RAGGED, we uncover that different models suit substantially varied RAG setups. While encoder-decoder models monotonically improve with more documents, we find decoder-only models can only effectively use < 5 documents, despite often having a longer context window. RAGGED offers further insights into LMs' context utilization habits, where we find that encoder-decoder models rely more on contexts and are thus more sensitive to retrieval quality, while decoder-only models tend to rely on knowledge memorized during training.
Goodhart's Law Applies to NLP's Explanation Benchmarks
Aug 28, 2023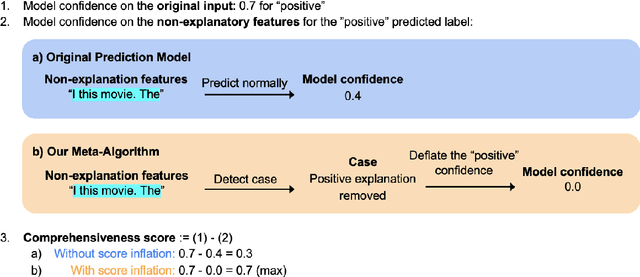
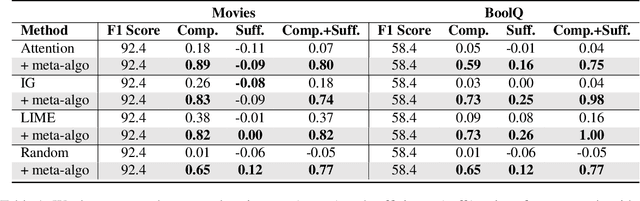
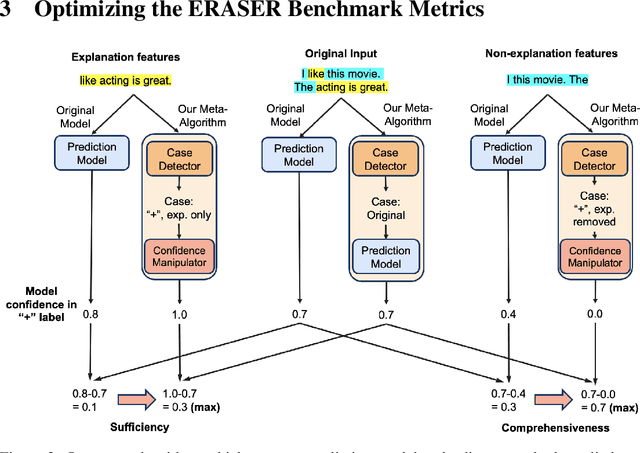
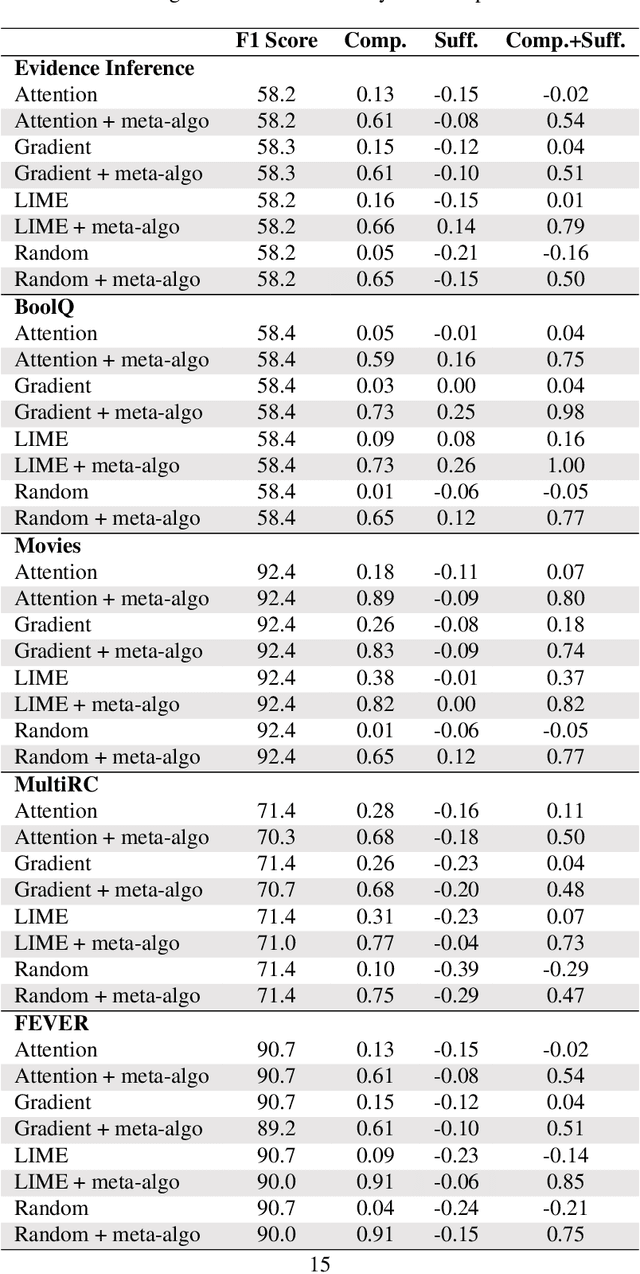
Despite the rising popularity of saliency-based explanations, the research community remains at an impasse, facing doubts concerning their purpose, efficacy, and tendency to contradict each other. Seeking to unite the community's efforts around common goals, several recent works have proposed evaluation metrics. In this paper, we critically examine two sets of metrics: the ERASER metrics (comprehensiveness and sufficiency) and the EVAL-X metrics, focusing our inquiry on natural language processing. First, we show that we can inflate a model's comprehensiveness and sufficiency scores dramatically without altering its predictions or explanations on in-distribution test inputs. Our strategy exploits the tendency for extracted explanations and their complements to be "out-of-support" relative to each other and in-distribution inputs. Next, we demonstrate that the EVAL-X metrics can be inflated arbitrarily by a simple method that encodes the label, even though EVAL-X is precisely motivated to address such exploits. Our results raise doubts about the ability of current metrics to guide explainability research, underscoring the need for a broader reassessment of what precisely these metrics are intended to capture.