 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGGED: Towards Informed Design of Retrieval Augmented Generation Systems
Mar 14, 2024Retrieval-augmented generation (RAG) greatly benefits language models (LMs) by providing additional context for tasks such as document-based question answering (DBQA). Despite its potential, the power of RAG is highly dependent on its configuration, raising the question: What is the optimal RAG configuration? To answer this, we introduce the RAGGED framework to analyze and optimize RAG systems. On a set of representative DBQA tasks, we study two classic sparse and dense retrievers, and four top-performing LMs in encoder-decoder and decoder-only architectures. Through RAGGED, we uncover that different models suit substantially varied RAG setups. While encoder-decoder models monotonically improve with more documents, we find decoder-only models can only effectively use < 5 documents, despite often having a longer context window. RAGGED offers further insights into LMs' context utilization habits, where we find that encoder-decoder models rely more on contexts and are thus more sensitive to retrieval quality, while decoder-only models tend to rely on knowledge memorized during training.
Otsu based Differential Evolution Method for Image Segmentation
Oct 18, 2022



This paper proposes an OTSU based differential evolution method for satellite image segmentation and compares it with four other methods such as Modified Artificial Bee Colony Optimizer (MABC), Artificial Bee Colony (ABC), Genetic Algorithm (GA), and Particle Swarm Optimization (PSO) using the objective function proposed by Otsu for optimal multilevel thresholding. The experiments conducted and their results illustrate that our proposed DE and OTSU algorithm segmentation can effectively and precisely segment the input image, close to results obtained by the other methods. In the proposed DE and OTSU algorithm, instead of passing the fitness function variables, the entire image is passed as an input to the DE algorithm after obtaining the threshold values for the input number of levels in the OTSU algorithm. The image segmentation results are obtained after learning about the image instead of learning about the fitness variables. In comparison to other segmentation methods examined, the proposed DE and OTSU algorithm yields promising results with minimized computational time compared to some algorithms.
Handling tree-structured text: parsing directory pages
Nov 24, 2021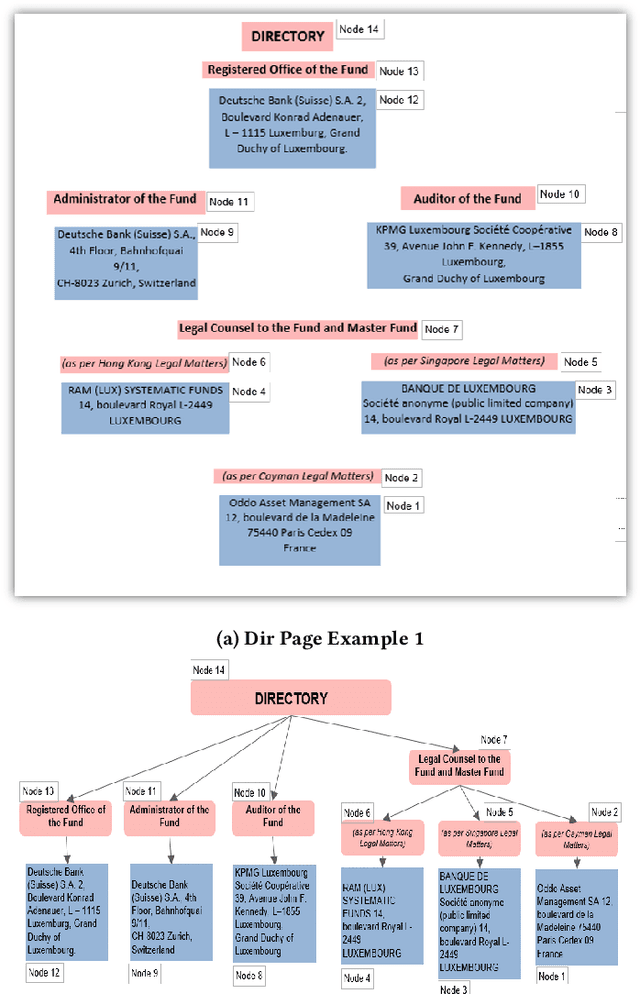
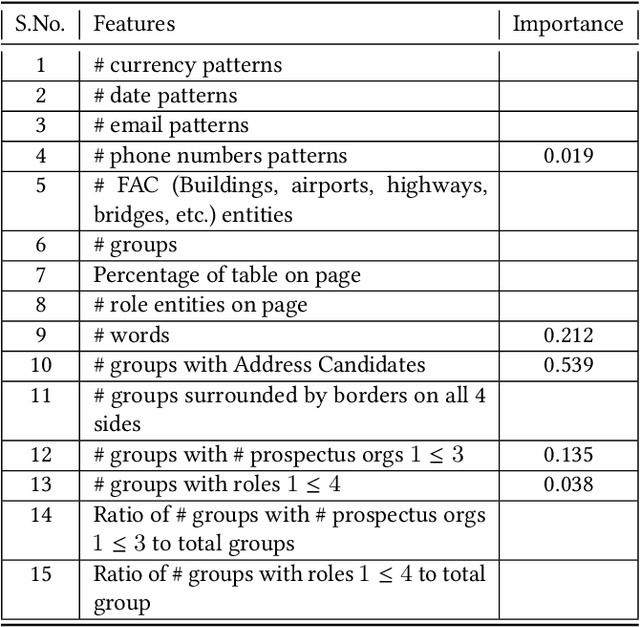

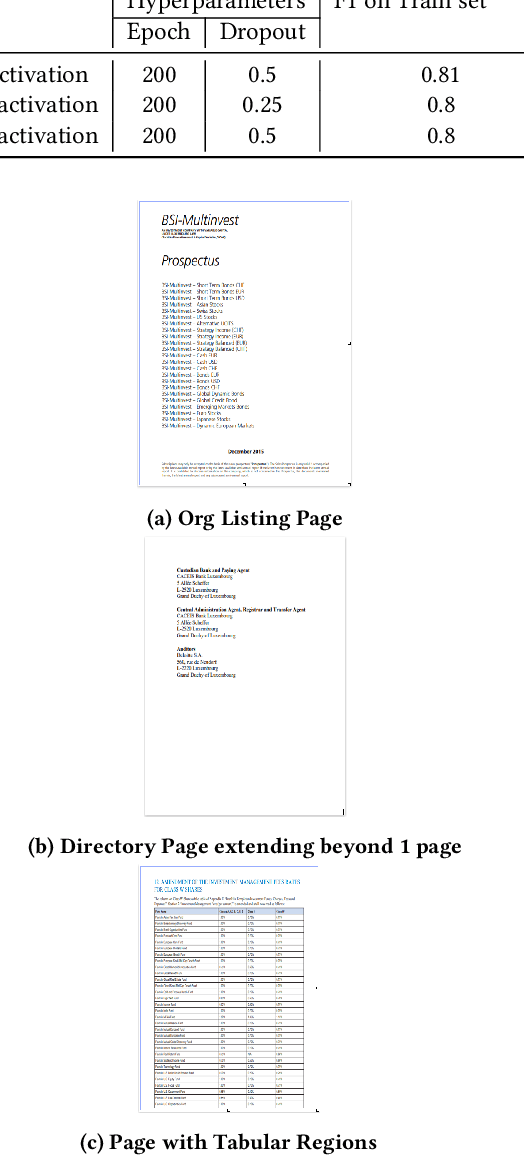
The determination of the reading sequence of text is fundamental to document understanding. This problem is easily solved in pages where the text is organized into a sequence of lines and vertical alignment runs the height of the page (producing multiple columns which can be read from left to right). We present a situation -- the directory page parsing problem -- where information is presented on the page in an irregular, visually-organized, two-dimensional format. Directory pages are fairly common in financial prospectuses and carry information about organizations, their addresses and relationships that is key to business tasks in client onboarding. Interestingly, directory pages sometimes have hierarchical structure, motivating the need to generalize the reading sequence to a reading tree. We present solutions to the problem of identifying directory pages and constructing the reading tree, using (learnt) classifiers for text segments and a bottom-up (right to left, bottom-to-top) traversal of segments. The solution is a key part of a production service supporting automatic extraction of organization, address and relationship information from client onboarding documents.