 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelucionQA: Detecting Hallucinations in Domain-specific Question Answering
Dec 08, 2023



Hallucination is a well-known phenomenon in text generated by large language models (LLMs). The existence of hallucinatory responses is found in almost all application scenarios e.g., summarization, question-answering (QA) etc. For applications requiring high reliability (e.g., customer-facing assistants), the potential existence of hallucination in LLM-generated text is a critical problem. The amount of hallucination can be reduced by leveraging information retrieval to provide relevant background information to the LLM. However, LLMs can still generate hallucinatory content for various reasons (e.g., prioritizing its parametric knowledge over the context, failure to capture the relevant information from the context, etc.). Detecting hallucinations through automated methods is thus paramount. To facilitate research in this direction, we introduce a sophisticated dataset, DelucionQA, that captures hallucinations made by retrieval-augmented LLMs for a domain-specific QA task. Furthermore, we propose a set of hallucination detection methods to serve as baselines for future works from the research community. Analysis and case study are also provided to share valuable insights on hallucination phenomena in the target scenario.
Learning to Filter Context for Retrieval-Augmented Generation
Nov 14, 2023On-the-fly retrieval of relevant knowledge has proven an essential element of reliable systems for tasks such as open-domain question answering and fact verification. However, because retrieval systems are not perfect, generation models are required to generate outputs given partially or entirely irrelevant passages. This can cause over- or under-reliance on context, and result in problems in the generated output such as hallucinations. To alleviate these problems, we propose FILCO, a method that improves the quality of the context provided to the generator by (1) identifying useful context based on lexical and information-theoretic approaches, and (2) training context filtering models that can filter retrieved contexts at test time. We experiment on six knowledge-intensive tasks with FLAN-T5 and LLaMa2, and demonstrate that our method outperforms existing approaches on extractive question answering (QA), complex multi-hop and long-form QA, fact verification, and dialog generation tasks. FILCO effectively improves the quality of context, whether or not it supports the canonical output.
Knowledge-grounded Natural Language Recommendation Explanation
Aug 30, 2023



Explanations accompanied by a recommendation can assist users in understanding the decision made by recommendation systems, which in turn increases a user's confidence and trust in the system. Recently, research has focused on generating natural language explanations in a human-readable format. Thus far, the proposed approaches leverage item reviews written by users, which are often subjective, sparse in language, and unable to account for new items that have not been purchased or reviewed before. Instead, we aim to generate fact-grounded recommendation explanations that are objectively described with item features while implicitly considering a user's preferences, based on the user's purchase history. To achieve this, we propose a knowledge graph (KG) approach to natural language explainable recommendation. Our approach draws on user-item features through a novel collaborative filtering-based KG representation to produce fact-grounded, personalized explanations, while jointly learning user-item representations for recommendation scoring. Experimental results show that our approach consistently outperforms previous state-of-the-art models on natural language explainable recommendation.
SwitchPrompt: Learning Domain-Specific Gated Soft Prompts for Classification in Low-Resource Domains
Feb 14, 2023Prompting pre-trained language models leads to promising results across natural language processing tasks but is less effective when applied in low-resource domains, due to the domain gap between the pre-training data and the downstream task. In this work, we bridge this gap with a novel and lightweight prompting methodology called SwitchPrompt for the adaptation of language models trained on datasets from the general domain to diverse low-resource domains. Using domain-specific keywords with a trainable gated prompt, SwitchPrompt offers domain-oriented prompting, that is, effective guidance on the target domains for general-domain language models. Our few-shot experiments on three text classification benchmarks demonstrate the efficacy of the general-domain pre-trained language models when used with SwitchPrompt. They often even outperform their domain-specific counterparts trained with baseline state-of-the-art prompting methods by up to 10.7% performance increase in accuracy. This result indicates that SwitchPrompt effectively reduces the need for domain-specific language model pre-training.
Retrieval as Attention: End-to-end Learning of Retrieval and Reading within a Single Transformer
Dec 05, 2022



Systems for knowledge-intensive tasks such as open-domain question answering (QA) usually consist of two stages: efficient retrieval of relevant documents from a large corpus and detailed reading of the selected documents to generate answers. Retrievers and readers are usually modeled separately, which necessitates a cumbersome implementation and is hard to train and adapt in an end-to-end fashion. In this paper, we revisit this design and eschew the separate architecture and training in favor of a single Transformer that performs Retrieval as Attention (ReAtt), and end-to-end training solely based on supervision from the end QA task. We demonstrate for the first time that a single model trained end-to-end can achieve both competitive retrieval and QA performance, matching or slightly outperforming state-of-the-art separately trained retrievers and readers. Moreover, end-to-end adaptation significantly boosts its performance on out-of-domain datasets in both supervised and unsupervised settings, making our model a simple and adaptable solution for knowledge-intensive tasks. Code and models are available at https://github.com/jzbjyb/ReAtt.
Understanding and Improving Zero-shot Multi-hop Reasoning in Generative Question Answering
Oct 09, 2022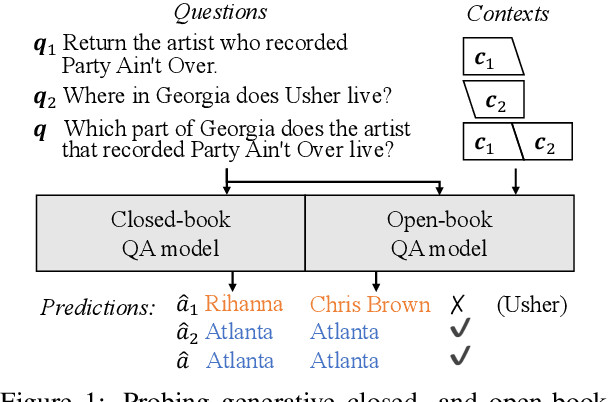

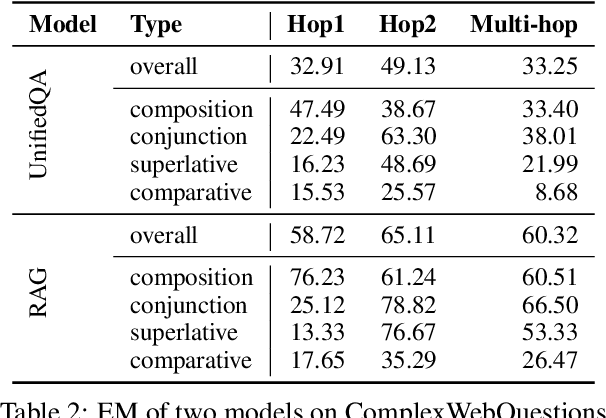
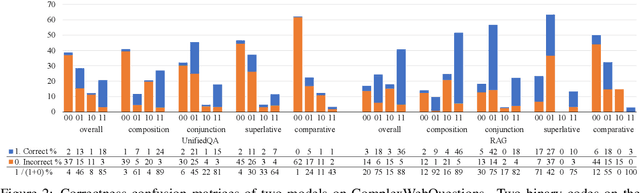
Generative question answering (QA) models generate answers to questions either solely based on the parameters of the model (the closed-book setting) or additionally retrieving relevant evidence (the open-book setting). Generative QA models can answer some relatively complex questions, but the mechanism through which they do so is still poorly understood. We perform several studies aimed at better understanding the multi-hop reasoning capabilities of generative QA models. First, we decompose multi-hop questions into multiple corresponding single-hop questions, and find marked inconsistency in QA models' answers on these pairs of ostensibly identical question chains. Second, we find that models lack zero-shot multi-hop reasoning ability: when trained only on single-hop questions, models generalize poorly to multi-hop questions. Finally, we demonstrate that it is possible to improve models' zero-shot multi-hop reasoning capacity through two methods that approximate real multi-hop natural language (NL) questions by training on either concatenation of single-hop questions or logical forms (SPARQL). In sum, these results demonstrate that multi-hop reasoning does not emerge naturally in generative QA models, but can be encouraged by advances in training or modeling techniques.
How Can We Know When Language Models Know?
Dec 02, 2020Recent works have shown that language models (LM) capture different types of knowledge regarding facts or common sense. However, because no model is perfect, they still fail to provide appropriate answers in many cases. In this paper, we ask the question "how can we know when language models know, with confidence, the answer to a particular query?" We examine this question from the point of view of calibration, the property of a probabilistic model's predicted probabilities actually being well correlated with the probability of correctness. We first examine a state-of-the-art generative QA model, T5, and examine whether its probabilities are well calibrated, finding the answer is a relatively emphatic no. We then examine methods to calibrate such models to make their confidence scores correlate better with the likelihood of correctness through fine-tuning, post-hoc probability modification, or adjustment of the predicted outputs or inputs. Experiments on a diverse range of datasets demonstrate the effectiveness of our methods. We also perform analysis to study the strengths and limitations of these methods, shedding light on further improvements that may be made in methods for calibrating LMs.
X-FACTR: Multilingual Factual Knowledge Retrieval from Pretrained Language Models
Oct 27, 2020


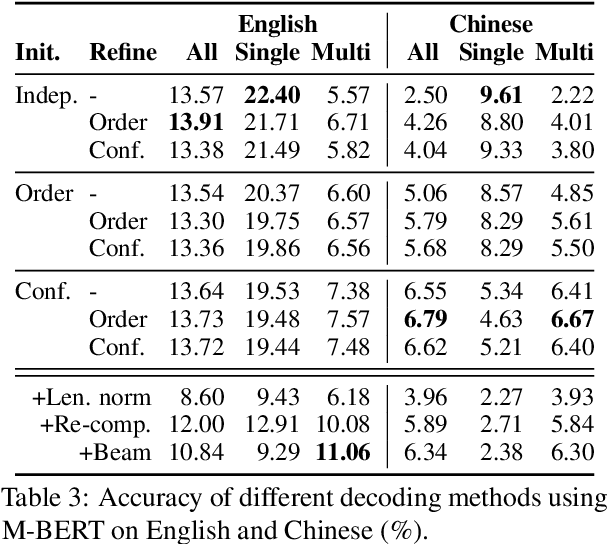
Language models (LMs) have proven surprisingly successful at capturing factual knowledge by completing cloze-style fill-in-the-blank questions such as "Punta Cana is located in _." However, while knowledge is both written and queried in many languages, studies on LMs' factual representation ability have almost invariably been performed on English. To assess factual knowledge retrieval in LMs in different languages, we create a multilingual benchmark of cloze-style probes for 23 typologically diverse languages. To properly handle language variations, we expand probing methods from single- to multi-word entities, and develop several decoding algorithms to generate multi-token predictions. Extensive experimental results provide insights about how well (or poorly) current state-of-the-art LMs perform at this task in languages with more or fewer available resources. We further propose a code-switching-based method to improve the ability of multilingual LMs to access knowledge, and verify its effectiveness on several benchmark languages. Benchmark data and code have been released at https://x-factr.github.io.
How Can We Know What Language Models Know?
Nov 28, 2019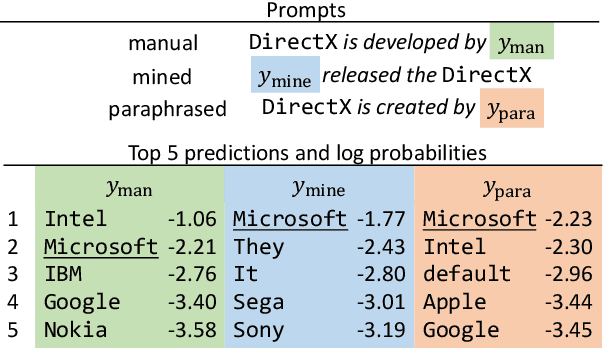
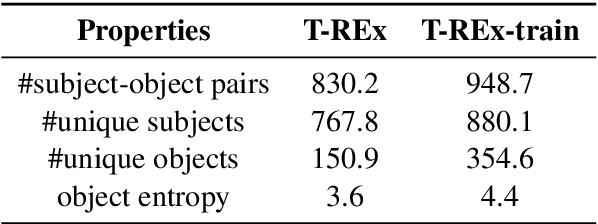
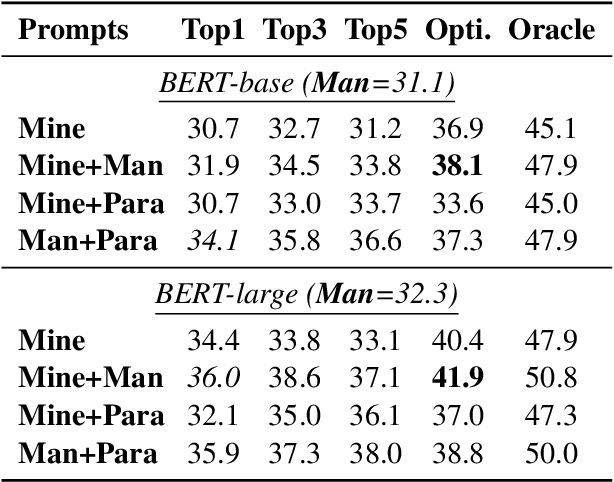
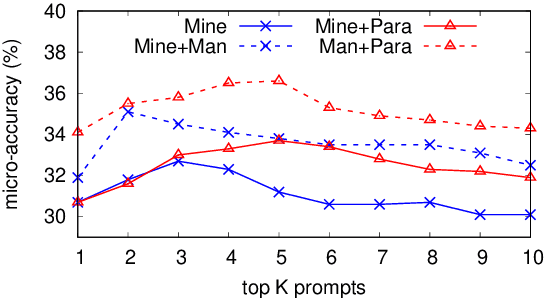
Recent work has presented intriguing results examining the knowledge contained in language models (LM) by having the LM fill in the blanks of prompts such as "Obama is a _ by profession". These prompts are usually manually created, and quite possibly sub-optimal; another prompt such as "Obama worked as a _" may result in more accurately predicting the correct profession. Because of this, given an inappropriate prompt, we might fail to retrieve facts that the LM does know, and thus any given prompt only provides a lower bound estimate of the knowledge contained in an LM. In this paper, we attempt to more accurately estimate the knowledge contained in LMs by automatically discovering better prompts to use in this querying process. Specifically, we propose mining-based and paraphrasing-based methods to automatically generate high-quality and diverse prompts and ensemble methods to combine answers from different prompts. Extensive experiments on the LAMA benchmark for extracting relational knowledge from LMs demonstrate that our methods can improve accuracy from 31.1% to 38.1%, providing a tighter lower bound on what LMs know. We have released the code and the resulting LM Prompt And Query Archive (LPAQA) at https://github.com/jzbjyb/LPAQA.
Generalizing Natural Language Analysis through Span-relation Representations
Nov 10, 2019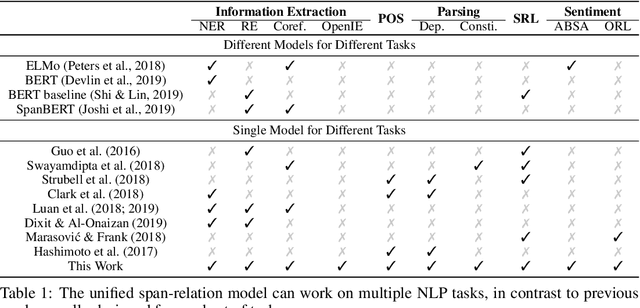

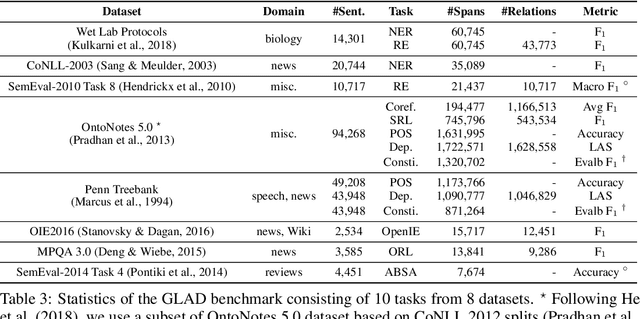
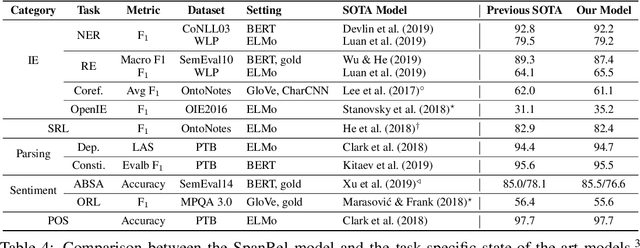
A large number of natural language processing tasks exist to analyze syntax, semantics, and information content of human language. These seemingly very different tasks are usually solved by specially designed architectures. In this paper, we provide the simple insight that a great variety of tasks can be represented in a single unified format consisting of labeling spans and relations between spans, thus a single task-independent model can be used across different tasks. We perform extensive experiments to test this insight on 10 disparate tasks as broad as dependency parsing (syntax), semantic role labeling (semantics), relation extraction (information content), aspect based sentiment analysis (sentiment), and many others, achieving comparable performance as state-of-the-art specialized models. We further demonstrate benefits in multi-task learning. We convert these datasets into a unified format to build a benchmark, which provides a holistic testbed for evaluating future models for generalized natural language analysis.