 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelucionQA: Detecting Hallucinations in Domain-specific Question Answering
Dec 08, 2023



Hallucination is a well-known phenomenon in text generated by large language models (LLMs). The existence of hallucinatory responses is found in almost all application scenarios e.g., summarization, question-answering (QA) etc. For applications requiring high reliability (e.g., customer-facing assistants), the potential existence of hallucination in LLM-generated text is a critical problem. The amount of hallucination can be reduced by leveraging information retrieval to provide relevant background information to the LLM. However, LLMs can still generate hallucinatory content for various reasons (e.g., prioritizing its parametric knowledge over the context, failure to capture the relevant information from the context, etc.). Detecting hallucinations through automated methods is thus paramount. To facilitate research in this direction, we introduce a sophisticated dataset, DelucionQA, that captures hallucinations made by retrieval-augmented LLMs for a domain-specific QA task. Furthermore, we propose a set of hallucination detection methods to serve as baselines for future works from the research community. Analysis and case study are also provided to share valuable insights on hallucination phenomena in the target scenario.
Knowledge-grounded Natural Language Recommendation Explanation
Aug 30, 2023



Explanations accompanied by a recommendation can assist users in understanding the decision made by recommendation systems, which in turn increases a user's confidence and trust in the system. Recently, research has focused on generating natural language explanations in a human-readable format. Thus far, the proposed approaches leverage item reviews written by users, which are often subjective, sparse in language, and unable to account for new items that have not been purchased or reviewed before. Instead, we aim to generate fact-grounded recommendation explanations that are objectively described with item features while implicitly considering a user's preferences, based on the user's purchase history. To achieve this, we propose a knowledge graph (KG) approach to natural language explainable recommendation. Our approach draws on user-item features through a novel collaborative filtering-based KG representation to produce fact-grounded, personalized explanations, while jointly learning user-item representations for recommendation scoring. Experimental results show that our approach consistently outperforms previous state-of-the-art models on natural language explainable recommendation.
Modeling Endorsement for Multi-Document Abstractive Summarization
Oct 15, 2021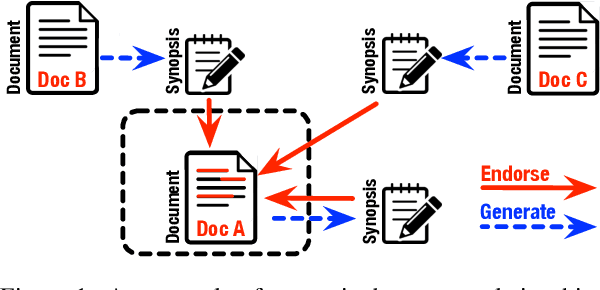
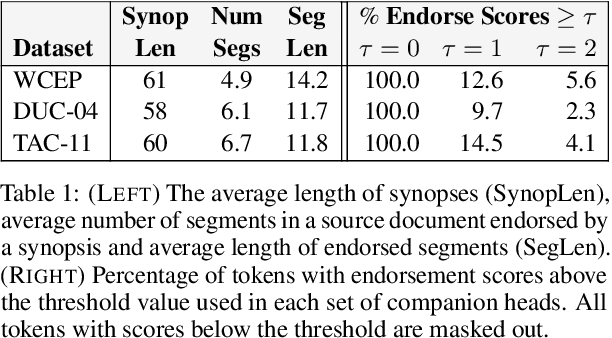
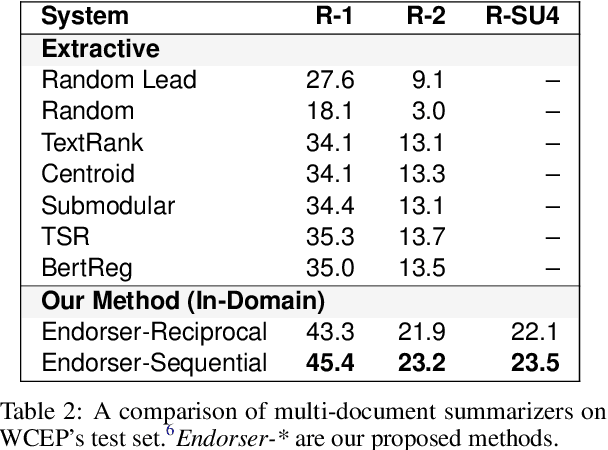
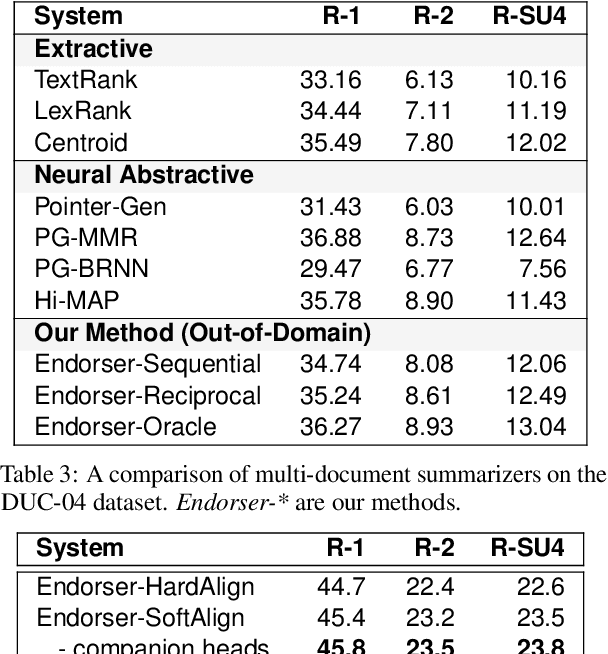
A crucial difference between single- and multi-document summarization is how salient content manifests itself in the document(s). While such content may appear at the beginning of a single document, essential information is frequently reiterated in a set of documents related to a particular topic, resulting in an endorsement effect that increases information salience. In this paper, we model the cross-document endorsement effect and its utilization in multiple document summarization. Our method generates a synopsis from each document, which serves as an endorser to identify salient content from other documents. Strongly endorsed text segments are used to enrich a neural encoder-decoder model to consolidate them into an abstractive summary. The method has a great potential to learn from fewer examples to identify salient content, which alleviates the need for costly retraining when the set of documents is dynamically adjusted. Through extensive experiments on benchmark multi-document summarization datasets, we demonstrate the effectiveness of our proposed method over strong published baselines. Finally, we shed light on future research directions and discuss broader challenges of this task using a case study.
A New Approach to Overgenerating and Scoring Abstractive Summaries
Apr 05, 2021


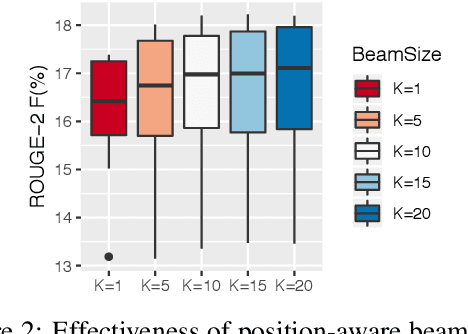
We propose a new approach to generate multiple variants of the target summary with diverse content and varying lengths, then score and select admissible ones according to users' needs. Abstractive summarizers trained on single reference summaries may struggle to produce outputs that achieve multiple desirable properties, i.e., capturing the most important information, being faithful to the original, grammatical and fluent. In this paper, we propose a two-staged strategy to generate a diverse set of candidate summaries from the source text in stage one, then score and select admissible ones in stage two. Importantly, our generator gives a precise control over the length of the summary, which is especially well-suited when space is limited. Our selectors are designed to predict the optimal summary length and put special emphasis on faithfulness to the original text. Both stages can be effectively trained, optimized and evaluated. Our experiments on benchmark summarization datasets suggest that this paradigm can achieve state-of-the-art performance.
Controlling the Amount of Verbatim Copying in Abstractive Summarization
Nov 23, 2019
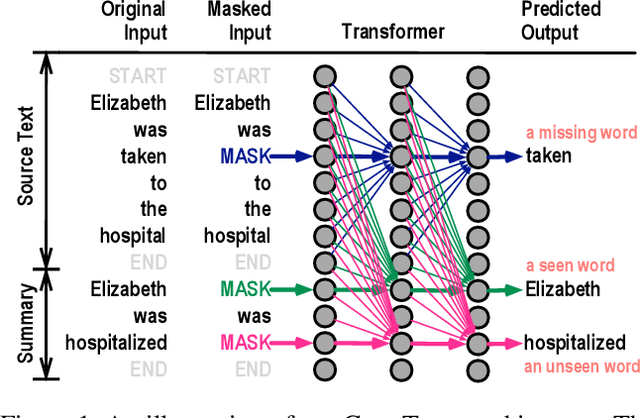

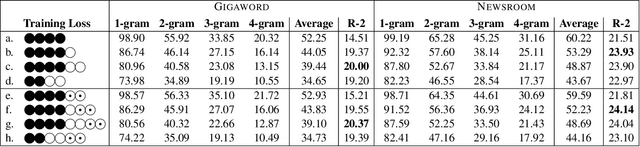
An abstract must not change the meaning of the original text. A single most effective way to achieve that is to increase the amount of copying while still allowing for text abstraction. Human editors can usually exercise control over copying, resulting in summaries that are more extractive than abstractive, or vice versa. However, it remains poorly understood whether modern neural abstractive summarizers can provide the same flexibility, i.e., learning from single reference summaries to generate multiple summary hypotheses with varying degrees of copying. In this paper, we present a neural summarization model that, by learning from single human abstracts, can produce a broad spectrum of summaries ranging from purely extractive to highly generative ones. We frame the task of summarization as language modeling and exploit alternative mechanisms to generate summary hypotheses. Our method allows for control over copying during both training and decoding stages of a neural summarization model. Through extensive experiments we illustrate the significance of our proposed method on controlling the amount of verbatim copying and achieve competitive results over strong baselines. Our analysis further reveals interesting and unobvious facts.