 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Endorsement for Multi-Document Abstractive Summarization
Oct 15, 2021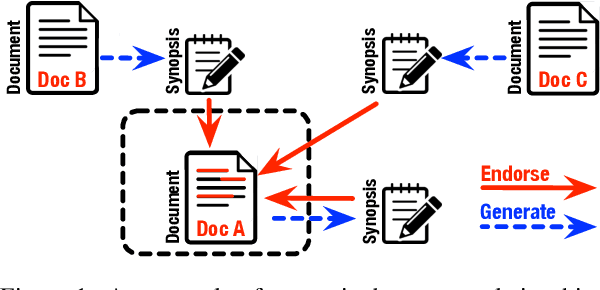
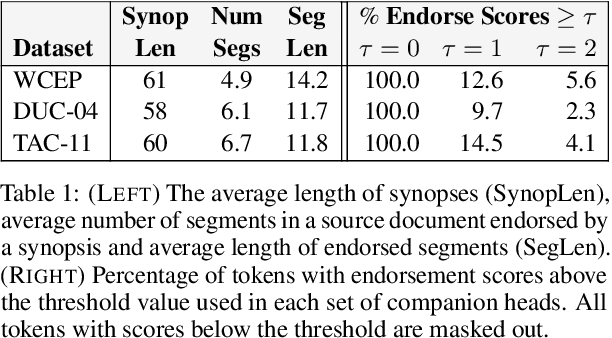
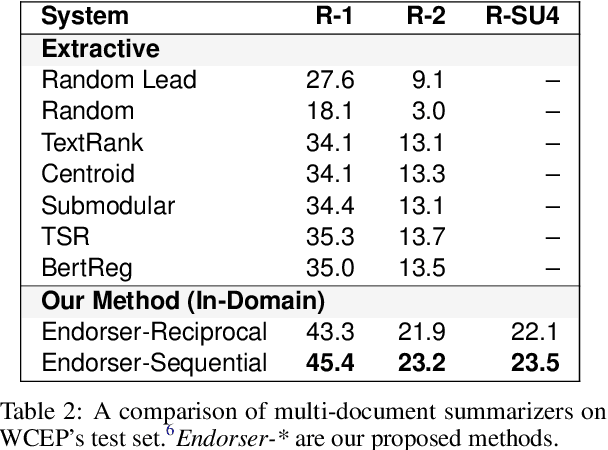
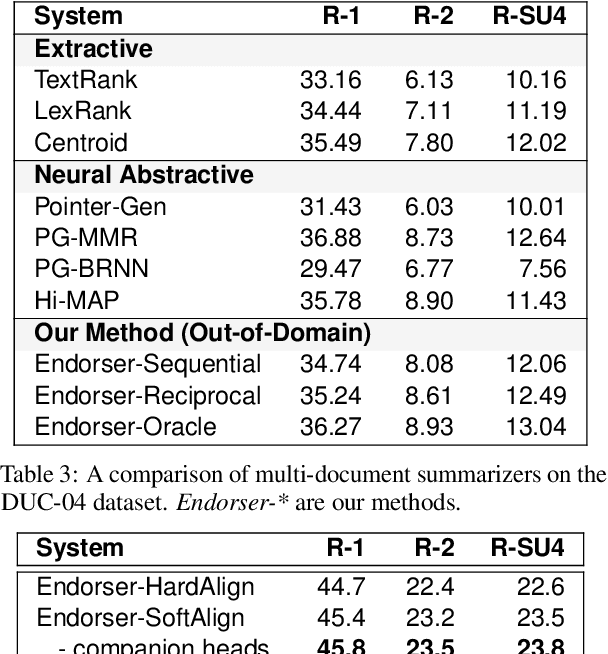
A crucial difference between single- and multi-document summarization is how salient content manifests itself in the document(s). While such content may appear at the beginning of a single document, essential information is frequently reiterated in a set of documents related to a particular topic, resulting in an endorsement effect that increases information salience. In this paper, we model the cross-document endorsement effect and its utilization in multiple document summarization. Our method generates a synopsis from each document, which serves as an endorser to identify salient content from other documents. Strongly endorsed text segments are used to enrich a neural encoder-decoder model to consolidate them into an abstractive summary. The method has a great potential to learn from fewer examples to identify salient content, which alleviates the need for costly retraining when the set of documents is dynamically adjusted. Through extensive experiments on benchmark multi-document summarization datasets, we demonstrate the effectiveness of our proposed method over strong published baselines. Finally, we shed light on future research directions and discuss broader challenges of this task using a case study.
Learning to Fuse Sentences with Transformers for Summarization
Oct 08, 2020
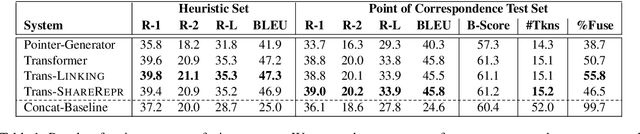
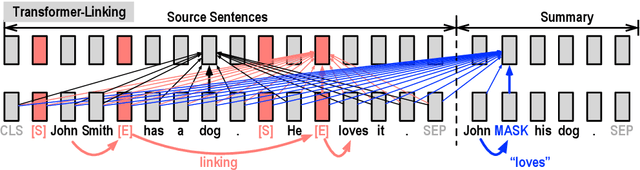

The ability to fuse sentences is highly attractive for summarization systems because it is an essential step to produce succinct abstracts. However, to date, summarizers can fail on fusing sentences. They tend to produce few summary sentences by fusion or generate incorrect fusions that lead the summary to fail to retain the original meaning. In this paper, we explore the ability of Transformers to fuse sentences and propose novel algorithms to enhance their ability to perform sentence fusion by leveraging the knowledge of points of correspondence between sentences. Through extensive experiments, we investigate the effects of different design choices on Transformer's performance. Our findings highlight the importance of modeling points of correspondence between sentences for effective sentence fusion.
A Cascade Approach to Neural Abstractive Summarization with Content Selection and Fusion
Oct 08, 2020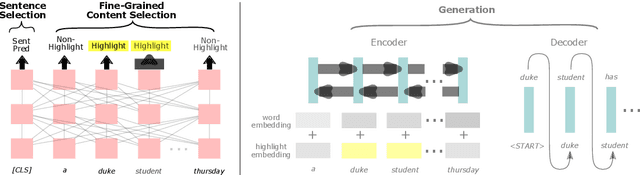

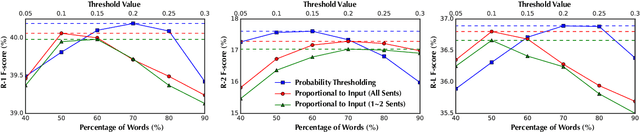
We present an empirical study in favor of a cascade architecture to neural text summarization. Summarization practices vary widely but few other than news summarization can provide a sufficient amount of training data enough to meet the requirement of end-to-end neural abstractive systems which perform content selection and surface realization jointly to generate abstracts. Such systems also pose a challenge to summarization evaluation, as they force content selection to be evaluated along with text generation, yet evaluation of the latter remains an unsolved problem. In this paper, we present empirical results showing that the performance of a cascaded pipeline that separately identifies important content pieces and stitches them together into a coherent text is comparable to or outranks that of end-to-end systems, whereas a pipeline architecture allows for flexible content selection. We finally discuss how we can take advantage of a cascaded pipeline in neural text summarization and shed light on important directions for future research.
Understanding Points of Correspondence between Sentences for Abstractive Summarization
Jun 10, 2020
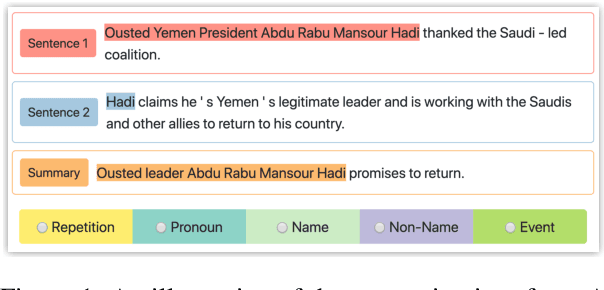
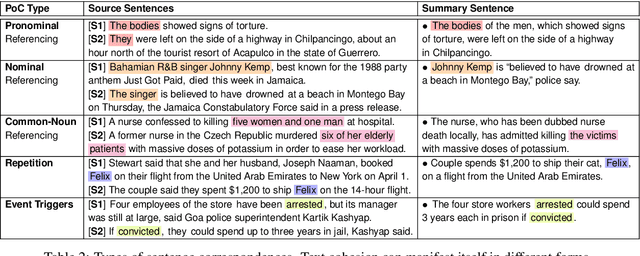

Fusing sentences containing disparate content is a remarkable human ability that helps create informative and succinct summaries. Such a simple task for humans has remained challenging for modern abstractive summarizers, substantially restricting their applicability in real-world scenarios. In this paper, we present an investigation into fusing sentences drawn from a document by introducing the notion of points of correspondence, which are cohesive devices that tie any two sentences together into a coherent text. The types of points of correspondence are delineated by text cohesion theory, covering pronominal and nominal referencing, repetition and beyond. We create a dataset containing the documents, source and fusion sentences, and human annotations of points of correspondence between sentences. Our dataset bridges the gap between coreference resolution and summarization. It is publicly shared to serve as a basis for future work to measure the success of sentence fusion systems. (https://github.com/ucfnlp/points-of-correspondence)
Joint Parsing and Generation for Abstractive Summarization
Nov 23, 2019
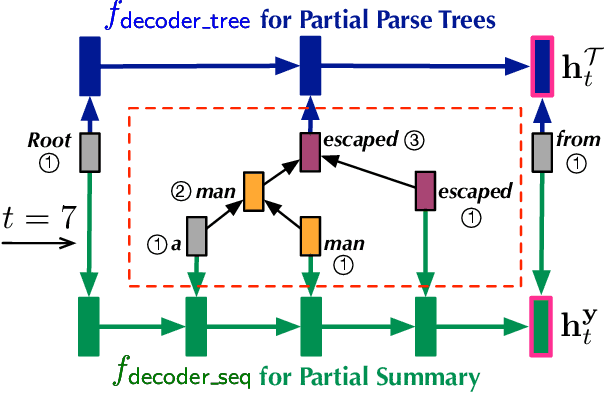
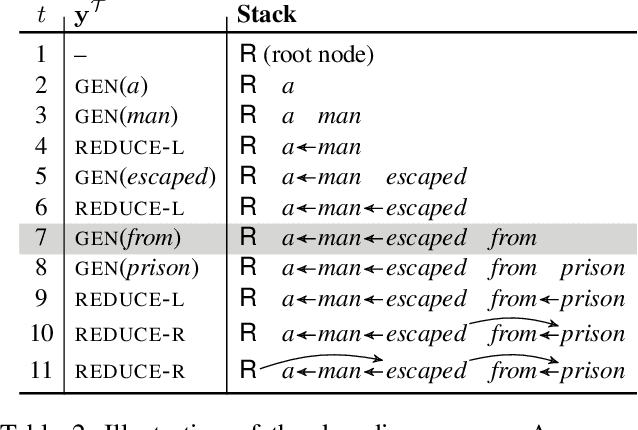
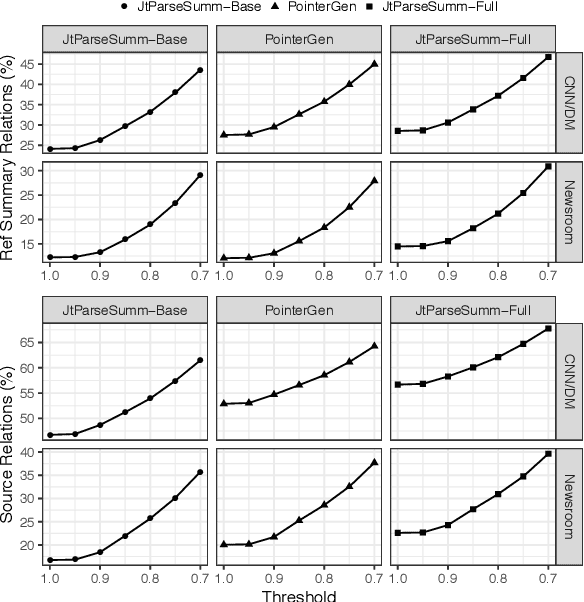
Sentences produced by abstractive summarization systems can be ungrammatical and fail to preserve the original meanings, despite being locally fluent. In this paper we propose to remedy this problem by jointly generating a sentence and its syntactic dependency parse while performing abstraction. If generating a word can introduce an erroneous relation to the summary, the behavior must be discouraged. The proposed method thus holds promise for producing grammatical sentences and encouraging the summary to stay true-to-original. Our contributions of this work are twofold. First, we present a novel neural architecture for abstractive summarization that combines a sequential decoder with a tree-based decoder in a synchronized manner to generate a summary sentence and its syntactic parse. Secondly, we describe a novel human evaluation protocol to assess if, and to what extent, a summary remains true to its original meanings. We evaluate our method on a number of summarization datasets and demonstrate competitive results against strong baselines.
Analyzing Sentence Fusion in Abstractive Summarization
Oct 01, 2019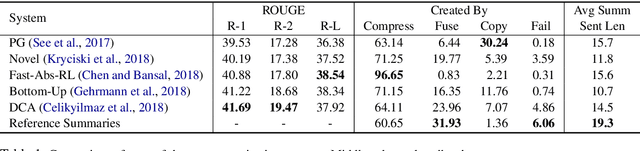
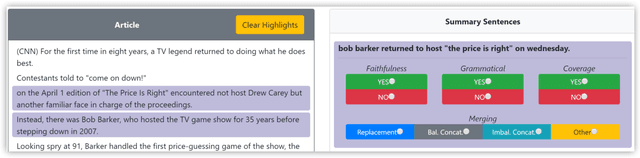
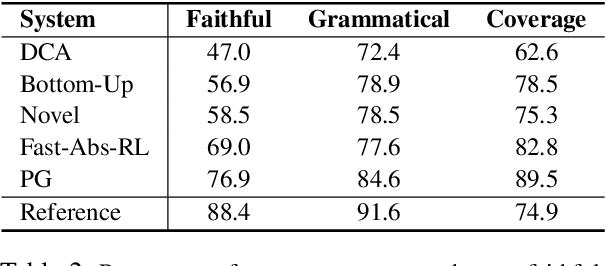
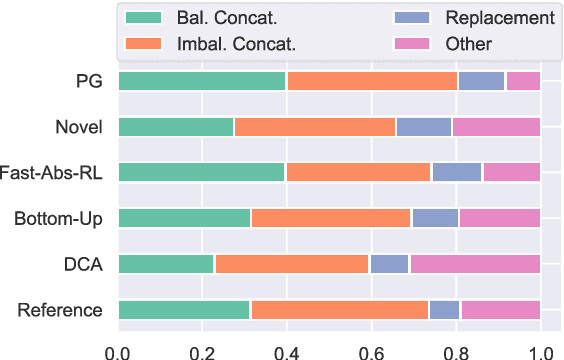
While recent work in abstractive summarization has resulted in higher scores in automatic metrics, there is little understanding on how these systems combine information taken from multiple document sentences. In this paper, we analyze the outputs of five state-of-the-art abstractive summarizers, focusing on summary sentences that are formed by sentence fusion. We ask assessors to judge the grammaticality, faithfulness, and method of fusion for summary sentences. Our analysis reveals that system sentences are mostly grammatical, but often fail to remain faithful to the original article.
Scoring Sentence Singletons and Pairs for Abstractive Summarization
May 31, 2019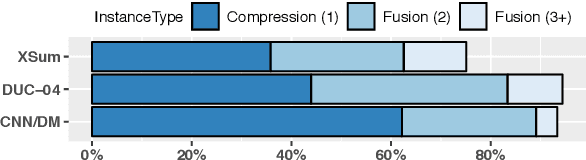


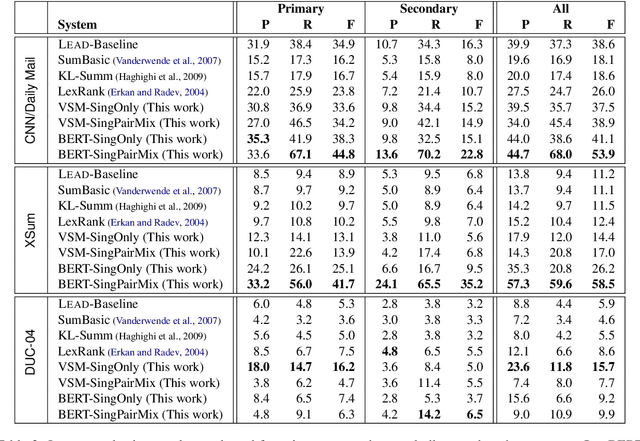
When writing a summary, humans tend to choose content from one or two sentences and merge them into a single summary sentence. However, the mechanisms behind the selection of one or multiple source sentences remain poorly understood. Sentence fusion assumes multi-sentence input; yet sentence selection methods only work with single sentences and not combinations of them. There is thus a crucial gap between sentence selection and fusion to support summarizing by both compressing single sentences and fusing pairs. This paper attempts to bridge the gap by ranking sentence singletons and pairs together in a unified space. Our proposed framework attempts to model human methodology by selecting either a single sentence or a pair of sentences, then compressing or fusing the sentence(s) to produce a summary sentence. We conduct extensive experiments on both single- and multi-document summarization datasets and report findings on sentence selection and abstraction.
Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization
May 31, 2019
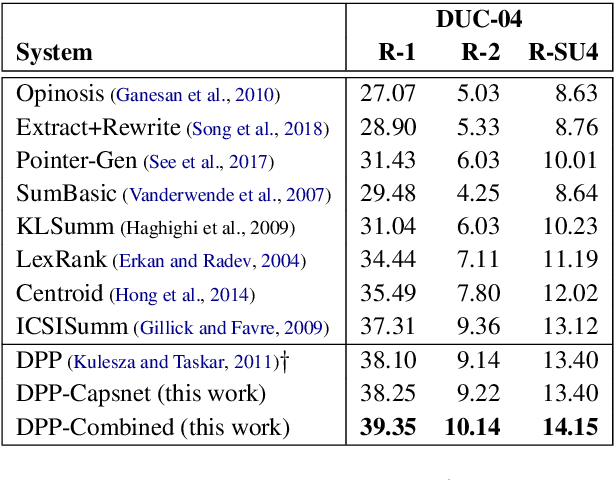
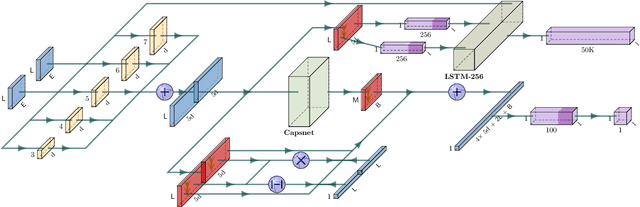
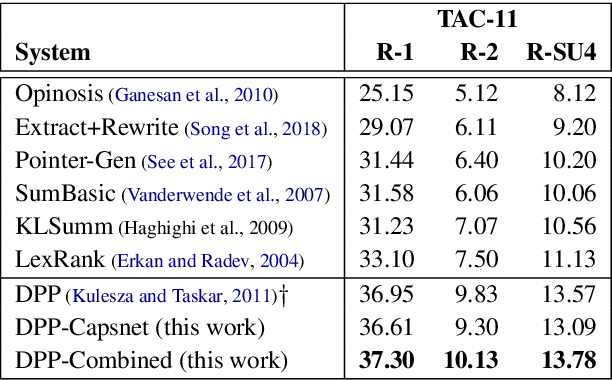
The most important obstacles facing multi-document summarization include excessive redundancy in source descriptions and the looming shortage of training data. These obstacles prevent encoder-decoder models from being used directly, but optimization-based methods such as determinantal point processes (DPPs) are known to handle them well. In this paper we seek to strengthen a DPP-based method for extractive multi-document summarization by presenting a novel similarity measure inspired by capsule networks. The approach measures redundancy between a pair of sentences based on surface form and semantic information. We show that our DPP system with improved similarity measure performs competitively, outperforming strong summarization baselines on benchmark datasets. Our findings are particularly meaningful for summarizing documents created by multiple authors containing redundant yet lexically diverse expressions.
Automatic Detection of Vague Words and Sentences in Privacy Policies
Aug 28, 2018
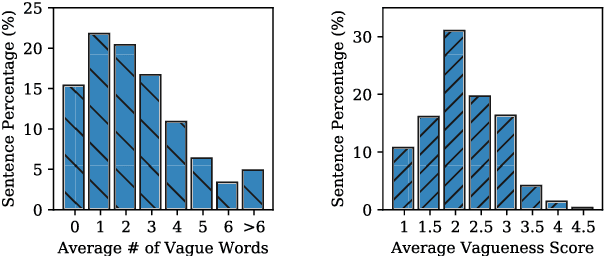
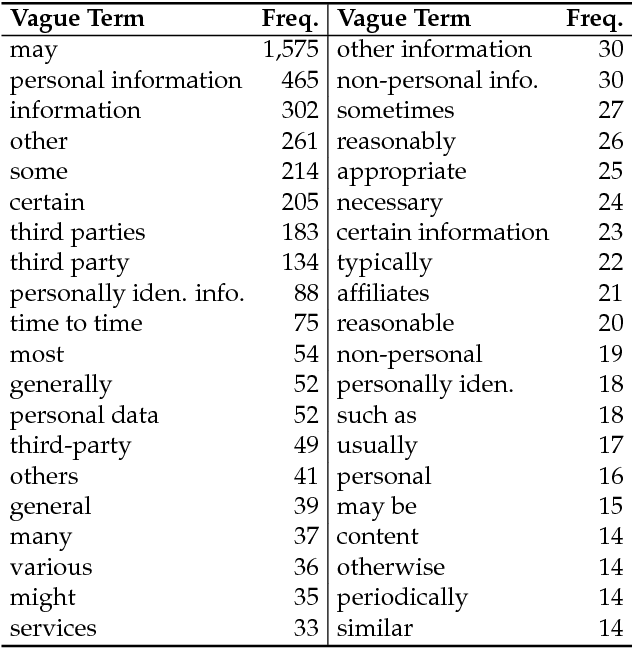
Website privacy policies represent the single most important source of information for users to gauge how their personal data are collected, used and shared by companies. However, privacy policies are often vague and people struggle to understand the content. Their opaqueness poses a significant challenge to both users and policy regulators. In this paper, we seek to identify vague content in privacy policies. We construct the first corpus of human-annotated vague words and sentences and present empirical studies on automatic vagueness detection. In particular, we investigate context-aware and context-agnostic models for predicting vague words, and explore auxiliary-classifier generative adversarial networks for characterizing sentence vagueness. Our experimental results demonstrate the effectiveness of proposed approaches. Finally, we provide suggestions for resolving vagueness and improving the usability of privacy policies.
Adapting the Neural Encoder-Decoder Framework from Single to Multi-Document Summarization
Aug 28, 2018
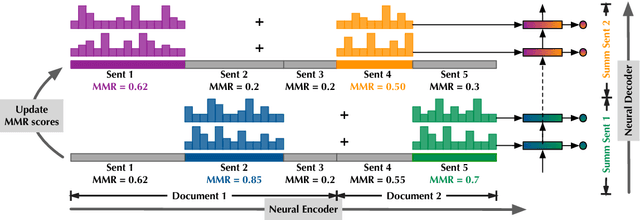
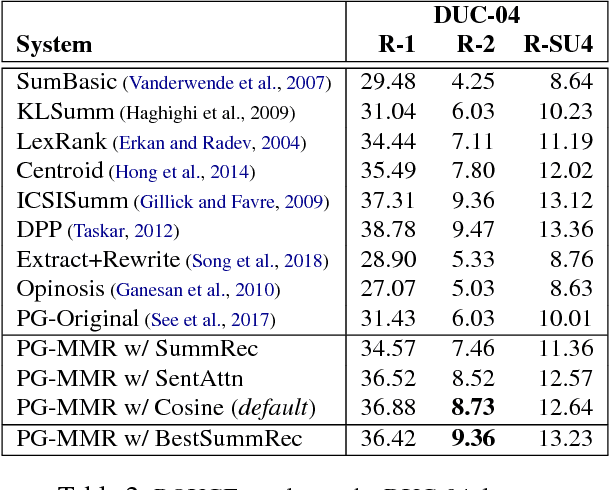
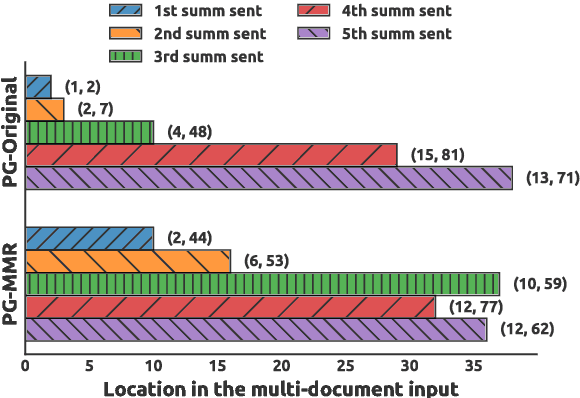
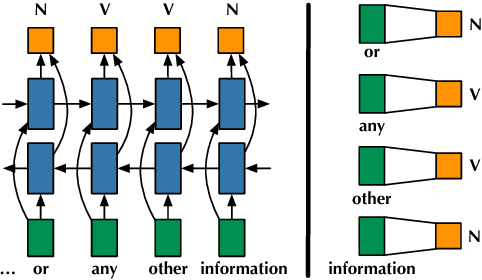
Generating a text abstract from a set of documents remains a challenging task. The neural encoder-decoder framework has recently been exploited to summarize single documents, but its success can in part be attributed to the availability of large parallel data automatically acquired from the Web. In contrast, parallel data for multi-document summarization are scarce and costly to obtain. There is a pressing need to adapt an encoder-decoder model trained on single-document summarization data to work with multiple-document input. In this paper, we present an initial investigation into a novel adaptation method. It exploits the maximal marginal relevance method to select representative sentences from multi-document input, and leverages an abstractive encoder-decoder model to fuse disparate sentences to an abstractive summary. The adaptation method is robust and itself requires no training data. Our system compares favorably to state-of-the-art extractive and abstractive approaches judged by automatic metrics and human assessors.