 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fourier Prior and Event Collaboration for Low-Light Image Enhancement
Aug 01, 2025The event camera, benefiting from its high dynamic range and low latency, provides performance gain for low-light image enhancement. Unlike frame-based cameras, it records intensity changes with extremely high temporal resolution, capturing sufficient structure information. Currently, existing event-based methods feed a frame and events directly into a single model without fully exploiting modality-specific advantages, which limits their performance. Therefore, by analyzing the role of each sensing modality, the enhancement pipeline is decoupled into two stages: visibility restoration and structure refinement. In the first stage, we design a visibility restoration network with amplitude-phase entanglement by rethinking the relationship between amplitude and phase components in Fourier space. In the second stage, a fusion strategy with dynamic alignment is proposed to mitigate the spatial mismatch caused by the temporal resolution discrepancy between two sensing modalities, aiming to refine the structure information of the image enhanced by the visibility restoration network. In addition, we utilize spatial-frequency interpolation to simulate negative samples with diverse illumination, noise and artifact degradations, thereby developing a contrastive loss that encourages the model to learn discriminative representations. Experiments demonstrate that the proposed method outperforms state-of-the-art models.
Learning to Fuse Sentences with Transformers for Summarization
Oct 08, 2020
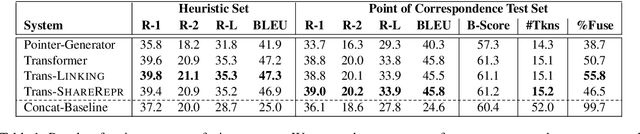
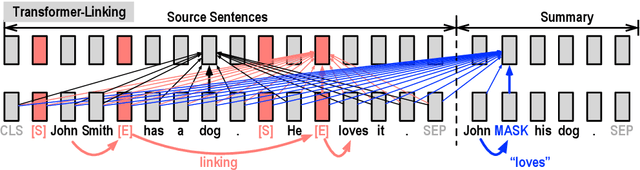

The ability to fuse sentences is highly attractive for summarization systems because it is an essential step to produce succinct abstracts. However, to date, summarizers can fail on fusing sentences. They tend to produce few summary sentences by fusion or generate incorrect fusions that lead the summary to fail to retain the original meaning. In this paper, we explore the ability of Transformers to fuse sentences and propose novel algorithms to enhance their ability to perform sentence fusion by leveraging the knowledge of points of correspondence between sentences. Through extensive experiments, we investigate the effects of different design choices on Transformer's performance. Our findings highlight the importance of modeling points of correspondence between sentences for effective sentence fusion.
Bayesian Optimization for Selecting Efficient Machine Learning Models
Aug 02, 2020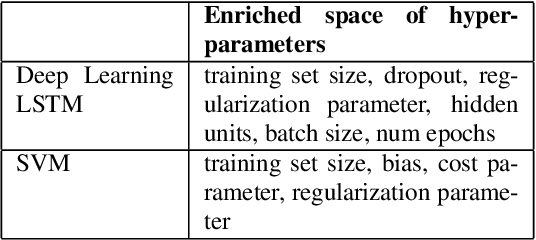
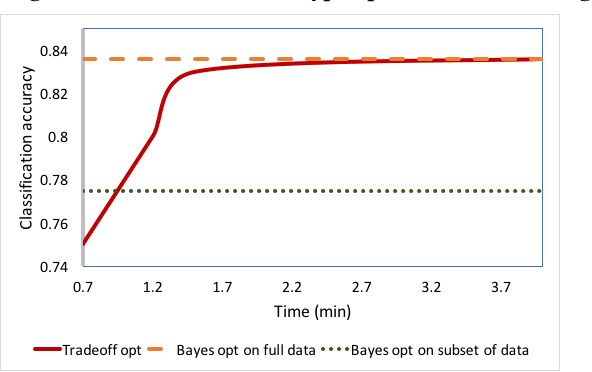
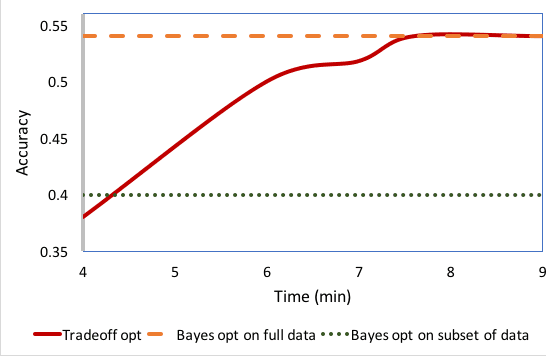

The performance of many machine learning models depends on their hyper-parameter settings. Bayesian Optimization has become a successful tool for hyper-parameter optimization of machine learning algorithms, which aims to identify optimal hyper-parameters during an iterative sequential process. However, most of the Bayesian Optimization algorithms are designed to select models for effectiveness only and ignore the important issue of model training efficiency. Given that both model effectiveness and training time are important for real-world applications, models selected for effectiveness may not meet the strict training time requirements necessary to deploy in a production environment. In this work, we present a unified Bayesian Optimization framework for jointly optimizing models for both prediction effectiveness and training efficiency. We propose an objective that captures the tradeoff between these two metrics and demonstrate how we can jointly optimize them in a principled Bayesian Optimization framework. Experiments on model selection for recommendation tasks indicate models selected this way significantly improves model training efficiency while maintaining strong effectiveness as compared to state-of-the-art Bayesian Optimization algorithms.
Understanding Points of Correspondence between Sentences for Abstractive Summarization
Jun 10, 2020
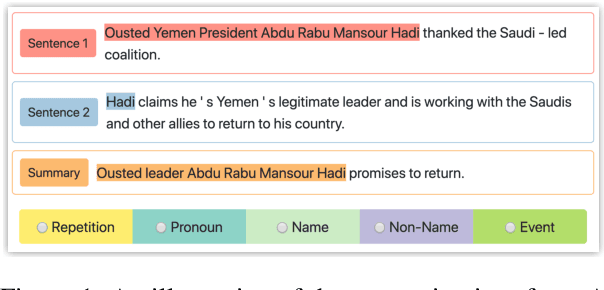
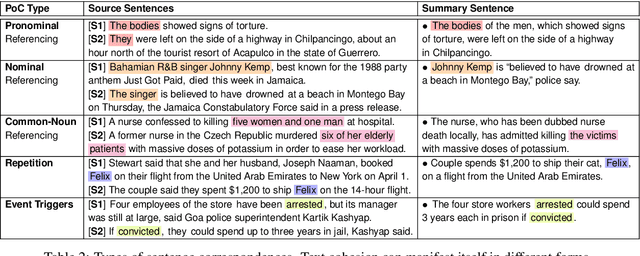

Fusing sentences containing disparate content is a remarkable human ability that helps create informative and succinct summaries. Such a simple task for humans has remained challenging for modern abstractive summarizers, substantially restricting their applicability in real-world scenarios. In this paper, we present an investigation into fusing sentences drawn from a document by introducing the notion of points of correspondence, which are cohesive devices that tie any two sentences together into a coherent text. The types of points of correspondence are delineated by text cohesion theory, covering pronominal and nominal referencing, repetition and beyond. We create a dataset containing the documents, source and fusion sentences, and human annotations of points of correspondence between sentences. Our dataset bridges the gap between coreference resolution and summarization. It is publicly shared to serve as a basis for future work to measure the success of sentence fusion systems. (https://github.com/ucfnlp/points-of-correspondence)
Open-Domain Question Answering with Pre-Constructed Question Spaces
Jun 02, 2020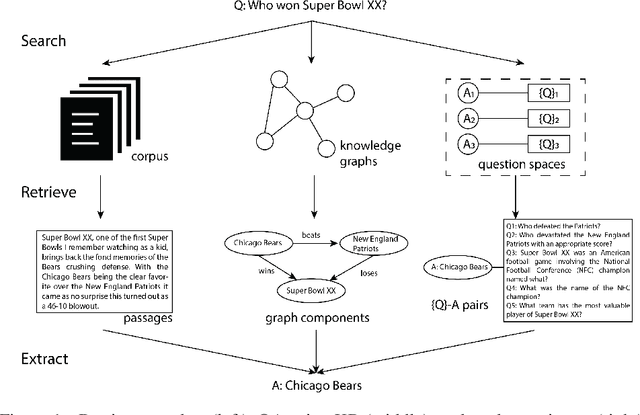

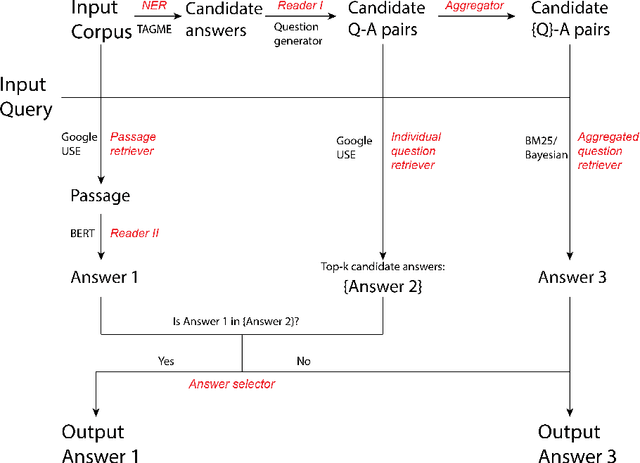
Open-domain question answering aims at solving the task of locating the answers to user-generated questions in large collections of documents. There are two families of solutions to this challenge. One family of algorithms, namely retriever-readers, first retrieves some pieces of text that are probably relevant to the question, and then feeds the retrieved text to a neural network to get the answer. Another line of work first constructs some knowledge graphs from the corpus, and queries the graph for the answer. We propose a novel algorithm with a reader-retriever structure that differs from both families. Our algorithm first reads off-line the corpus to generate collections of all answerable questions associated with their answers, and then queries the pre-constructed question spaces online to find answers that are most likely to be asked in the given way. The final answer returned to the user is decided with an accept-or-reject mechanism that combines multiple candidate answers by comparing the level of agreement between the retriever-reader and reader-retriever results. We claim that our algorithm solves some bottlenecks in existing work, and demonstrate that it achieves superior accuracy on a public dataset.
High-Quality Facial Photo-Sketch Synthesis Using Multi-Adversarial Networks
Mar 03, 2018
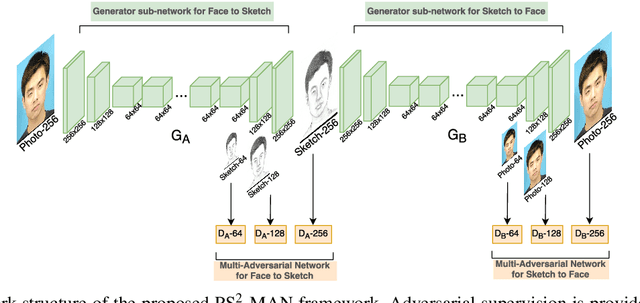


Synthesizing face sketches from real photos and its inverse have many applications. However, photo/sketch synthesis remains a challenging problem due to the fact that photo and sketch have different characteristics. In this work, we consider this task as an image-to-image translation problem and explore the recently popular generative models (GANs) to generate high-quality realistic photos from sketches and sketches from photos. Recent GAN-based methods have shown promising results on image-to-image translation problems and photo-to-sketch synthesis in particular, however, they are known to have limited abilities in generating high-resolution realistic images. To this end, we propose a novel synthesis framework called Photo-Sketch Synthesis using Multi-Adversarial Networks, (PS2-MAN) that iteratively generates low resolution to high resolution images in an adversarial way. The hidden layers of the generator are supervised to first generate lower resolution images followed by implicit refinement in the network to generate higher resolution images. Furthermore, since photo-sketch synthesis is a coupled/paired translation problem, we leverage the pair information using CycleGAN framework. Both Image Quality Assessment (IQA) and Photo-Sketch Matching experiments are conducted to demonstrate the superior performance of our framework in comparison to existing state-of-the-art solutions. Code available at: https://github.com/lidan1/PhotoSketchMAN.
Applying Deep Learning to Answer Selection: A Study and An Open Task
Oct 02, 2015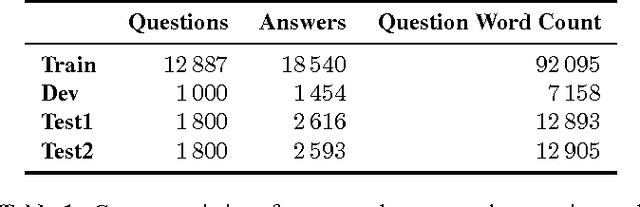
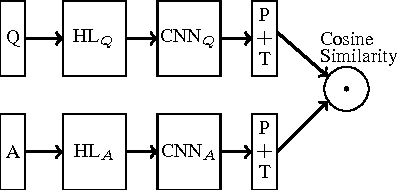
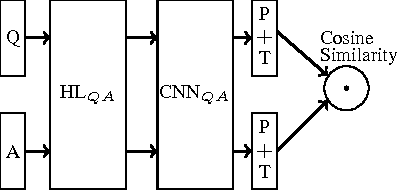
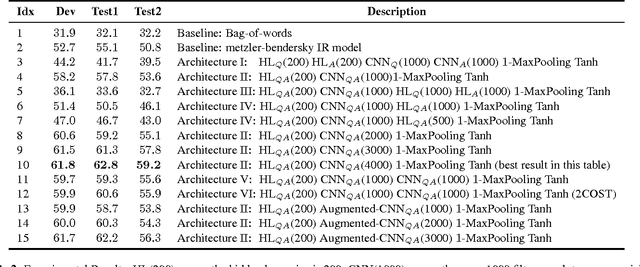
We apply a general deep learning framework to address the non-factoid question answering task. Our approach does not rely on any linguistic tools and can be applied to different languages or domains. Various architectures are presented and compared. We create and release a QA corpus and setup a new QA task in the insurance domain. Experimental results demonstrate superior performance compared to the baseline methods and various technologies give further improvements. For this highly challenging task, the top-1 accuracy can reach up to 65.3% on a test set, which indicates a great potential for practical use.