 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC Blank Triggered Dynamic Layer-Skipping for Efficient CTC-based Speech Recognition
Jan 04, 2024Deploying end-to-end speech recognition models with limited computing resources remains challenging, despite their impressive performance. Given the gradual increase in model size and the wide range of model applications, selectively executing model components for different inputs to improve the inference efficiency is of great interest. In this paper, we propose a dynamic layer-skipping method that leverages the CTC blank output from intermediate layers to trigger the skipping of the last few encoder layers for frames with high blank probabilities. Furthermore, we factorize the CTC output distribution and perform knowledge distillation on intermediate layers to reduce computation and improve recognition accuracy. Experimental results show that by utilizing the CTC blank, the encoder layer depth can be adjusted dynamically, resulting in 29% acceleration of the CTC model inference with minor performance degradation.
Fourier Transformer: Fast Long Range Modeling by Removing Sequence Redundancy with FFT Operator
May 24, 2023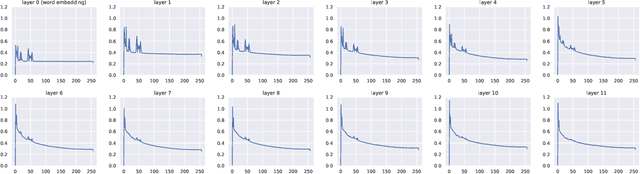
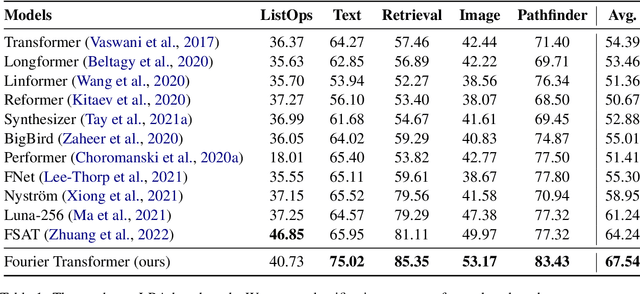
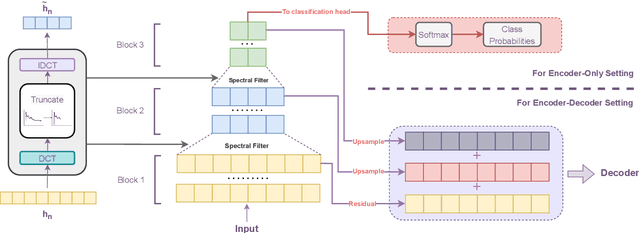
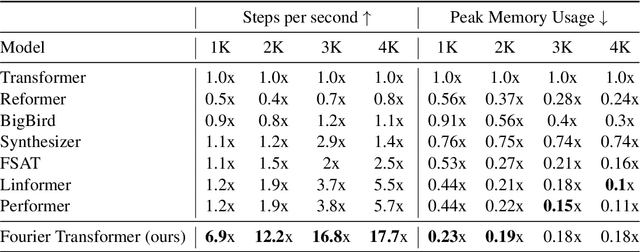
The transformer model is known to be computationally demanding, and prohibitively costly for long sequences, as the self-attention module uses a quadratic time and space complexity with respect to sequence length. Many researchers have focused on designing new forms of self-attention or introducing new parameters to overcome this limitation, however a large portion of them prohibits the model to inherit weights from large pretrained models. In this work, the transformer's inefficiency has been taken care of from another perspective. We propose Fourier Transformer, a simple yet effective approach by progressively removing redundancies in hidden sequence using the ready-made Fast Fourier Transform (FFT) operator to perform Discrete Cosine Transformation (DCT). Fourier Transformer is able to significantly reduce computational costs while retain the ability to inherit from various large pretrained models. Experiments show that our model achieves state-of-the-art performances among all transformer-based models on the long-range modeling benchmark LRA with significant improvement in both speed and space. For generative seq-to-seq tasks including CNN/DailyMail and ELI5, by inheriting the BART weights our model outperforms the standard BART and other efficient models. \footnote{Our code is publicly available at \url{https://github.com/LUMIA-Group/FourierTransformer}}
GaDei: On Scale-up Training As A Service For Deep Learning
Oct 03, 2017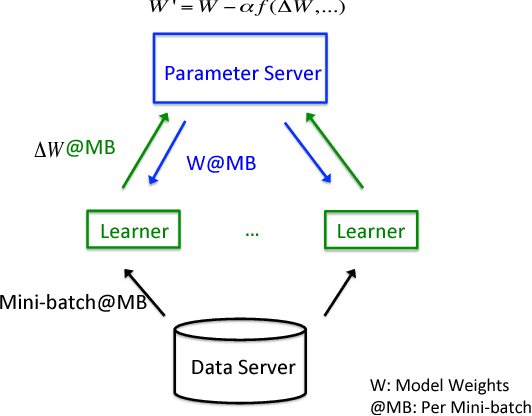
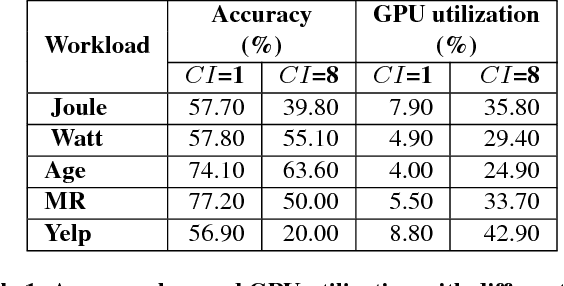
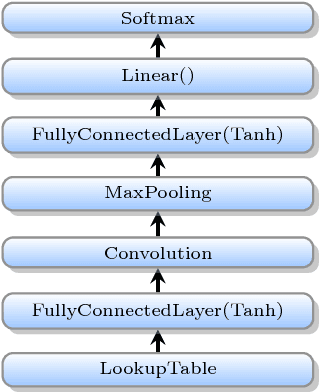
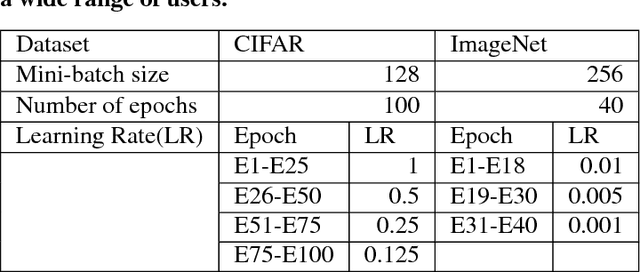
Deep learning (DL) training-as-a-service (TaaS) is an important emerging industrial workload. The unique challenge of TaaS is that it must satisfy a wide range of customers who have no experience and resources to tune DL hyper-parameters, and meticulous tuning for each user's dataset is prohibitively expensive. Therefore, TaaS hyper-parameters must be fixed with values that are applicable to all users. IBM Watson Natural Language Classifier (NLC) service, the most popular IBM cognitive service used by thousands of enterprise-level clients around the globe, is a typical TaaS service. By evaluating the NLC workloads, we show that only the conservative hyper-parameter setup (e.g., small mini-batch size and small learning rate) can guarantee acceptable model accuracy for a wide range of customers. We further justify theoretically why such a setup guarantees better model convergence in general. Unfortunately, the small mini-batch size causes a high volume of communication traffic in a parameter-server based system. We characterize the high communication bandwidth requirement of TaaS using representative industrial deep learning workloads and demonstrate that none of the state-of-the-art scale-up or scale-out solutions can satisfy such a requirement. We then present GaDei, an optimized shared-memory based scale-up parameter server design. We prove that the designed protocol is deadlock-free and it processes each gradient exactly once. Our implementation is evaluated on both commercial benchmarks and public benchmarks to demonstrate that it significantly outperforms the state-of-the-art parameter-server based implementation while maintaining the required accuracy and our implementation reaches near the best possible runtime performance, constrained only by the hardware limitation. Furthermore, to the best of our knowledge, GaDei is the only scale-up DL system that provides fault-tolerance.
A Structured Self-attentive Sentence Embedding
Mar 09, 2017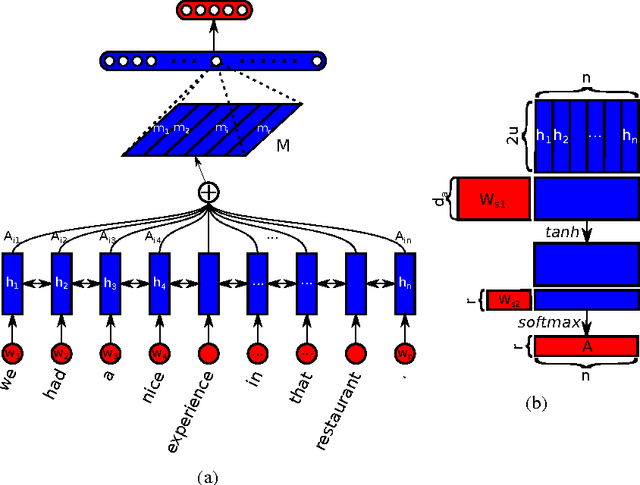


This paper proposes a new model for extracting an interpretable sentence embedding by introducing self-attention. Instead of using a vector, we use a 2-D matrix to represent the embedding, with each row of the matrix attending on a different part of the sentence. We also propose a self-attention mechanism and a special regularization term for the model. As a side effect, the embedding comes with an easy way of visualizing what specific parts of the sentence are encoded into the embedding. We evaluate our model on 3 different tasks: author profiling, sentiment classification, and textual entailment. Results show that our model yields a significant performance gain compared to other sentence embedding methods in all of the 3 tasks.
Distributed Deep Learning for Question Answering
Aug 04, 2016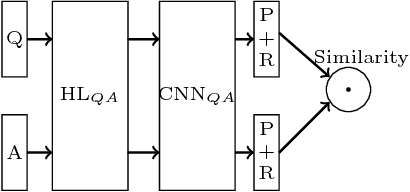
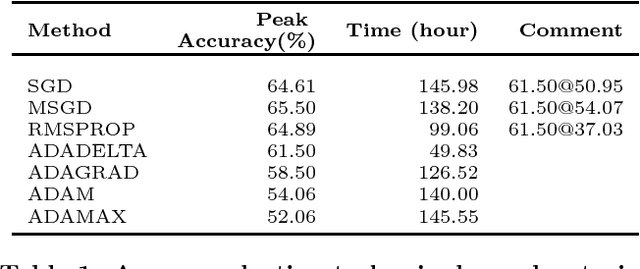
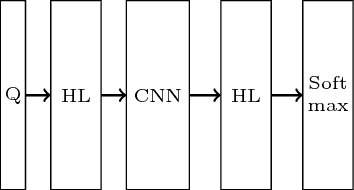
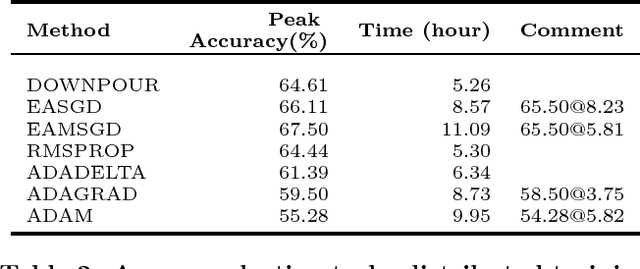
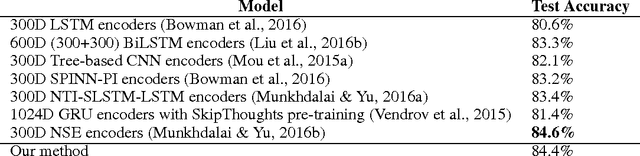
This paper is an empirical study of the distributed deep learning for question answering subtasks: answer selection and question classification. Comparison studies of SGD, MSGD, ADADELTA, ADAGRAD, ADAM/ADAMAX, RMSPROP, DOWNPOUR and EASGD/EAMSGD algorithms have been presented. Experimental results show that the distributed framework based on the message passing interface can accelerate the convergence speed at a sublinear scale. This paper demonstrates the importance of distributed training. For example, with 48 workers, a 24x speedup is achievable for the answer selection task and running time is decreased from 138.2 hours to 5.81 hours, which will increase the productivity significantly.
Applying Deep Learning to Answer Selection: A Study and An Open Task
Oct 02, 2015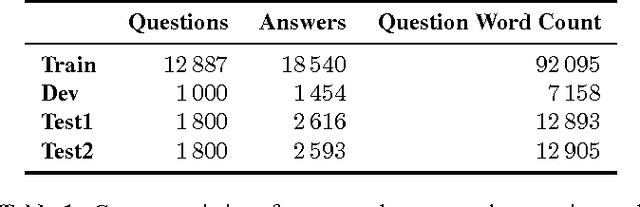
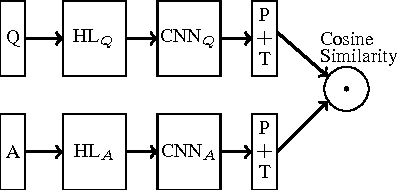
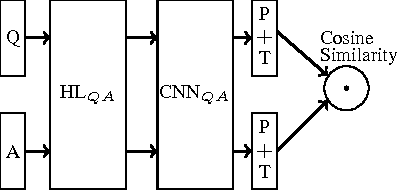
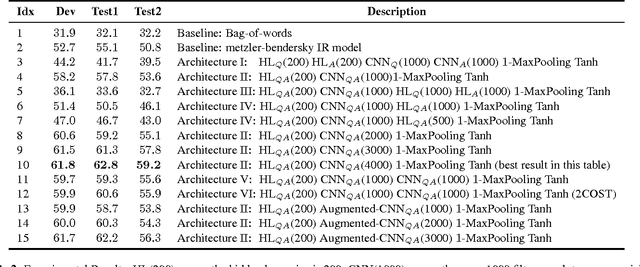
We apply a general deep learning framework to address the non-factoid question answering task. Our approach does not rely on any linguistic tools and can be applied to different languages or domains. Various architectures are presented and compared. We create and release a QA corpus and setup a new QA task in the insurance domain. Experimental results demonstrate superior performance compared to the baseline methods and various technologies give further improvements. For this highly challenging task, the top-1 accuracy can reach up to 65.3% on a test set, which indicates a great potential for practical use.