Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Deep Learning for Question Answering
Paper and Code
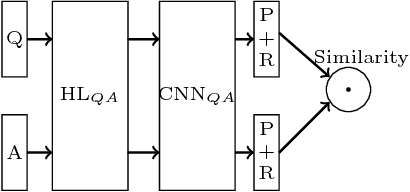
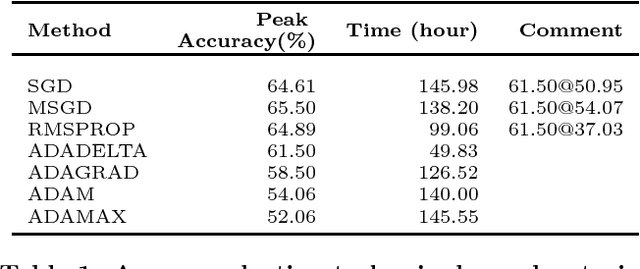
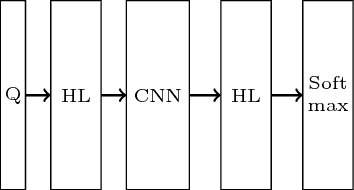
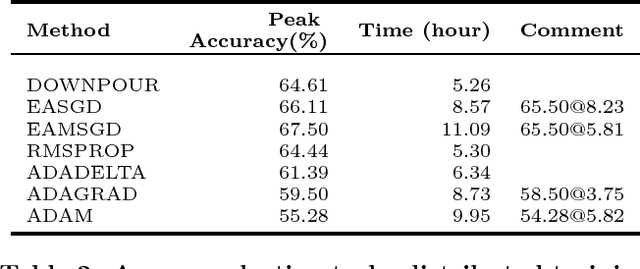
This paper is an empirical study of the distributed deep learning for question answering subtasks: answer selection and question classification. Comparison studies of SGD, MSGD, ADADELTA, ADAGRAD, ADAM/ADAMAX, RMSPROP, DOWNPOUR and EASGD/EAMSGD algorithms have been presented. Experimental results show that the distributed framework based on the message passing interface can accelerate the convergence speed at a sublinear scale. This paper demonstrates the importance of distributed training. For example, with 48 workers, a 24x speedup is achievable for the answer selection task and running time is decreased from 138.2 hours to 5.81 hours, which will increase the productivity significantly.
* This paper will appear in the Proceeding of The 25th ACM
International Conference on Information and Knowledge Management (CIKM 2016),
Indianapolis, USA
View paper on