 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Memory Augmented Language Models through Mixture of Word Experts
Nov 15, 2023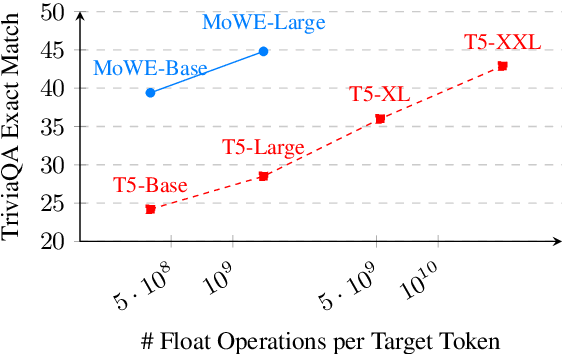
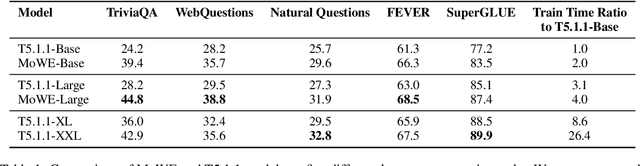
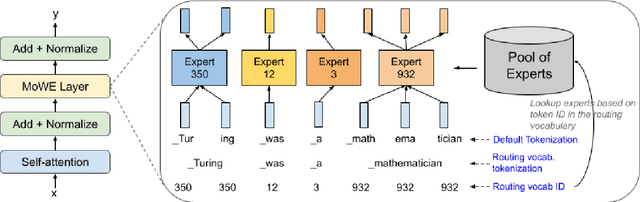
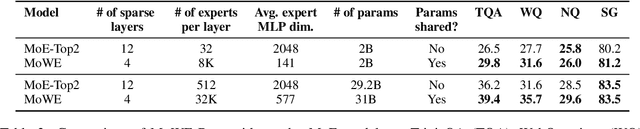
Scaling up the number of parameters of language models has proven to be an effective approach to improve performance. For dense models, increasing model size proportionally increases the model's computation footprint. In this work, we seek to aggressively decouple learning capacity and FLOPs through Mixture-of-Experts (MoE) style models with large knowledge-rich vocabulary based routing functions and experts. Our proposed approach, dubbed Mixture of Word Experts (MoWE), can be seen as a memory augmented model, where a large set of word-specific experts play the role of a sparse memory. We demonstrate that MoWE performs significantly better than the T5 family of models with similar number of FLOPs in a variety of NLP tasks. Additionally, MoWE outperforms regular MoE models on knowledge intensive tasks and has similar performance to more complex memory augmented approaches that often require to invoke custom mechanisms to search the sparse memory.
Triggering Multi-Hop Reasoning for Question Answering in Language Models using Soft Prompts and Random Walks
Jun 06, 2023



Despite readily memorizing world knowledge about entities, pre-trained language models (LMs) struggle to compose together two or more facts to perform multi-hop reasoning in question-answering tasks. In this work, we propose techniques that improve upon this limitation by relying on random walks over structured knowledge graphs. Specifically, we use soft prompts to guide LMs to chain together their encoded knowledge by learning to map multi-hop questions to random walk paths that lead to the answer. Applying our methods on two T5 LMs shows substantial improvements over standard tuning approaches in answering questions that require 2-hop reasoning.
Knowledge Prompts: Injecting World Knowledge into Language Models through Soft Prompts
Oct 10, 2022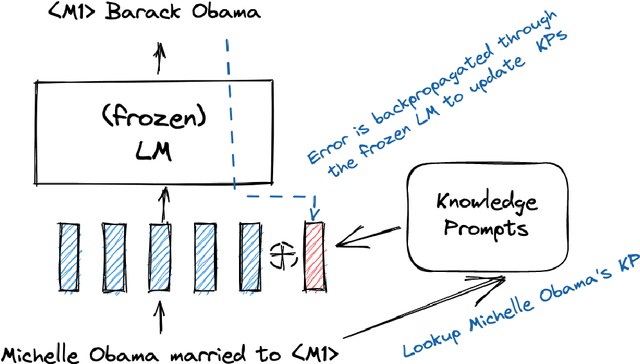


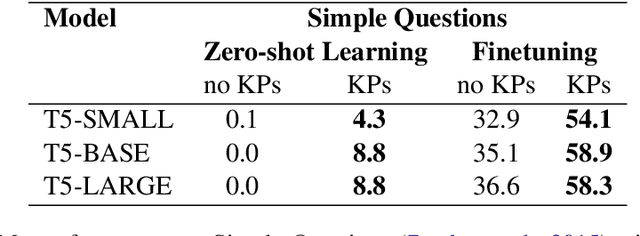
Soft prompts have been recently proposed as a tool for adapting large frozen language models (LMs) to new tasks. In this work, we repurpose soft prompts to the task of injecting world knowledge into LMs. We introduce a method to train soft prompts via self-supervised learning on data from knowledge bases. The resulting soft knowledge prompts (KPs) are task independent and work as an external memory of the LMs. We perform qualitative and quantitative experiments and demonstrate that: (1) KPs can effectively model the structure of the training data; (2) KPs can be used to improve the performance of LMs in different knowledge intensive tasks.
Counterfactual Data Augmentation improves Factuality of Abstractive Summarization
May 25, 2022
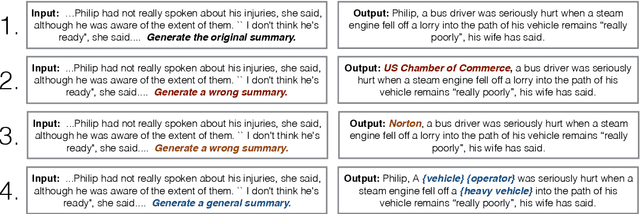
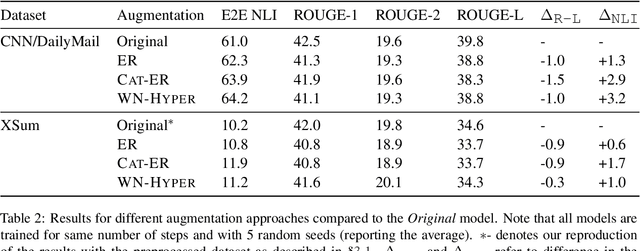

Abstractive summarization systems based on pretrained language models often generate coherent but factually inconsistent sentences. In this paper, we present a counterfactual data augmentation approach where we augment data with perturbed summaries that increase the training data diversity. Specifically, we present three augmentation approaches based on replacing (i) entities from other and the same category and (ii) nouns with their corresponding WordNet hypernyms. We show that augmenting the training data with our approach improves the factual correctness of summaries without significantly affecting the ROUGE score. We show that in two commonly used summarization datasets (CNN/Dailymail and XSum), we improve the factual correctness by about 2.5 points on average
ED2LM: Encoder-Decoder to Language Model for Faster Document Re-ranking Inference
Apr 25, 2022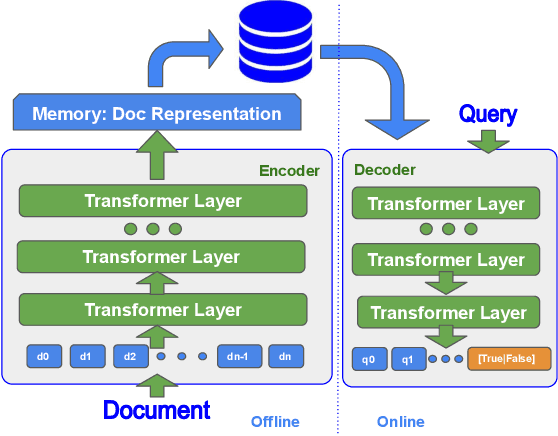
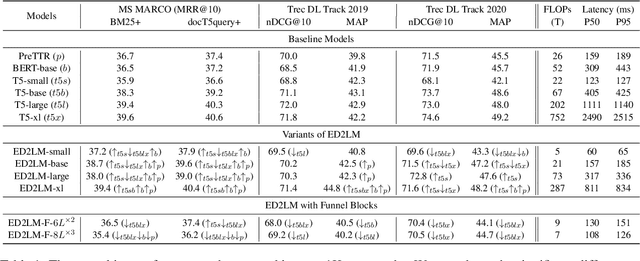
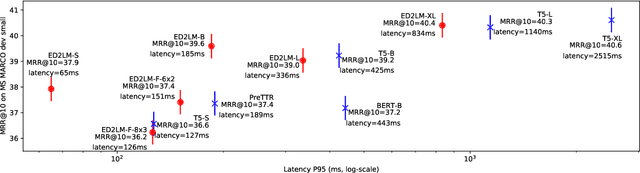
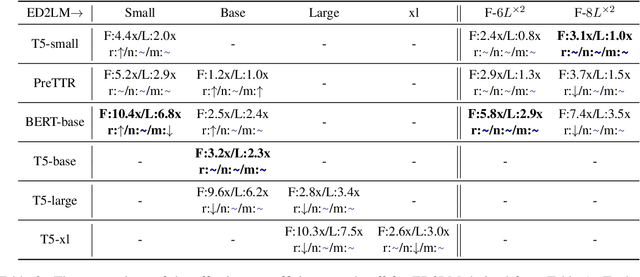
State-of-the-art neural models typically encode document-query pairs using cross-attention for re-ranking. To this end, models generally utilize an encoder-only (like BERT) paradigm or an encoder-decoder (like T5) approach. These paradigms, however, are not without flaws, i.e., running the model on all query-document pairs at inference-time incurs a significant computational cost. This paper proposes a new training and inference paradigm for re-ranking. We propose to finetune a pretrained encoder-decoder model using in the form of document to query generation. Subsequently, we show that this encoder-decoder architecture can be decomposed into a decoder-only language model during inference. This results in significant inference time speedups since the decoder-only architecture only needs to learn to interpret static encoder embeddings during inference. Our experiments show that this new paradigm achieves results that are comparable to the more expensive cross-attention ranking approaches while being up to 6.8X faster. We believe this work paves the way for more efficient neural rankers that leverage large pretrained models.
Contrastive Fine-tuning Improves Robustness for Neural Rankers
May 27, 2021
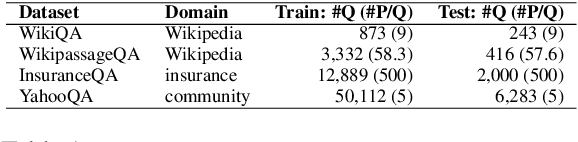

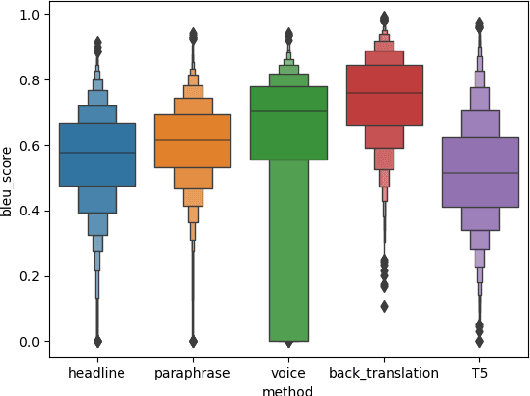
The performance of state-of-the-art neural rankers can deteriorate substantially when exposed to noisy inputs or applied to a new domain. In this paper, we present a novel method for fine-tuning neural rankers that can significantly improve their robustness to out-of-domain data and query perturbations. Specifically, a contrastive loss that compares data points in the representation space is combined with the standard ranking loss during fine-tuning. We use relevance labels to denote similar/dissimilar pairs, which allows the model to learn the underlying matching semantics across different query-document pairs and leads to improved robustness. In experiments with four passage ranking datasets, the proposed contrastive fine-tuning method obtains improvements on robustness to query reformulations, noise perturbations, and zero-shot transfer for both BERT and BART based rankers. Additionally, our experiments show that contrastive fine-tuning outperforms data augmentation for robustifying neural rankers.
Joint Text and Label Generation for Spoken Language Understanding
May 11, 2021



Generalization is a central problem in machine learning, especially when data is limited. Using prior information to enforce constraints is the principled way of encouraging generalization. In this work, we propose to leverage the prior information embedded in pretrained language models (LM) to improve generalization for intent classification and slot labeling tasks with limited training data. Specifically, we extract prior knowledge from pretrained LM in the form of synthetic data, which encode the prior implicitly. We fine-tune the LM to generate an augmented language, which contains not only text but also encodes both intent labels and slot labels. The generated synthetic data can be used to train a classifier later. Since the generated data may contain noise, we rephrase the learning from generated data as learning with noisy labels. We then utilize the mixout regularization for the classifier and prove its effectiveness to resist label noise in generated data. Empirically, our method demonstrates superior performance and outperforms the baseline by a large margin.
Improving Factual Consistency of Abstractive Summarization via Question Answering
May 10, 2021

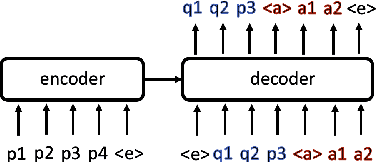

A commonly observed problem with the state-of-the art abstractive summarization models is that the generated summaries can be factually inconsistent with the input documents. The fact that automatic summarization may produce plausible-sounding yet inaccurate summaries is a major concern that limits its wide application. In this paper we present an approach to address factual consistency in summarization. We first propose an efficient automatic evaluation metric to measure factual consistency; next, we propose a novel learning algorithm that maximizes the proposed metric during model training. Through extensive experiments, we confirm that our method is effective in improving factual consistency and even overall quality of the summaries, as judged by both automatic metrics and human evaluation.
Generative Context Pair Selection for Multi-hop Question Answering
Apr 18, 2021



Compositional reasoning tasks like multi-hop question answering, require making latent decisions to get the final answer, given a question. However, crowdsourced datasets often capture only a slice of the underlying task distribution, which can induce unanticipated biases in models performing compositional reasoning. Furthermore, discriminatively trained models exploit such biases to get a better held-out performance, without learning the right way to reason, as they do not necessitate paying attention to the question representation (conditioning variable) in its entirety, to estimate the answer likelihood. In this work, we propose a generative context selection model for multi-hop question answering that reasons about how the given question could have been generated given a context pair. While being comparable to the state-of-the-art answering performance, our proposed generative passage selection model has a better performance (4.9% higher than baseline) on adversarial held-out set which tests robustness of model's multi-hop reasoning capabilities.