 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dialogue Representations from Consecutive Utterances
May 26, 2022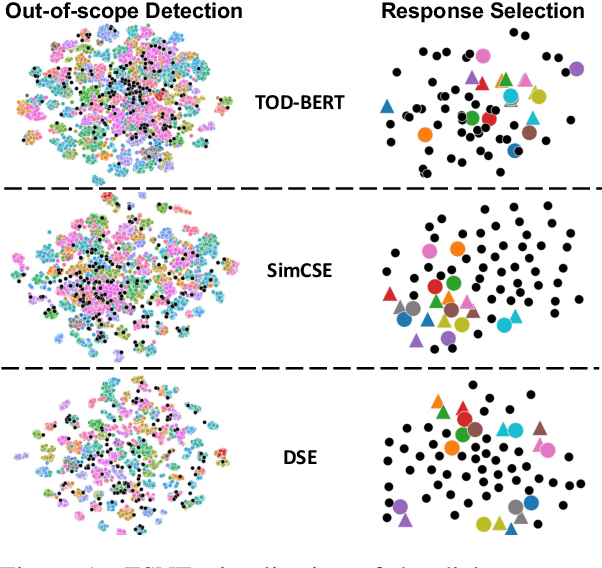

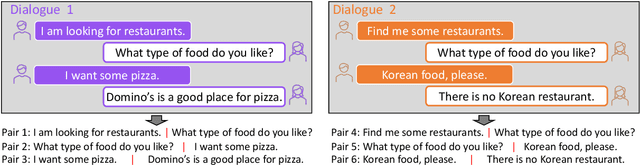
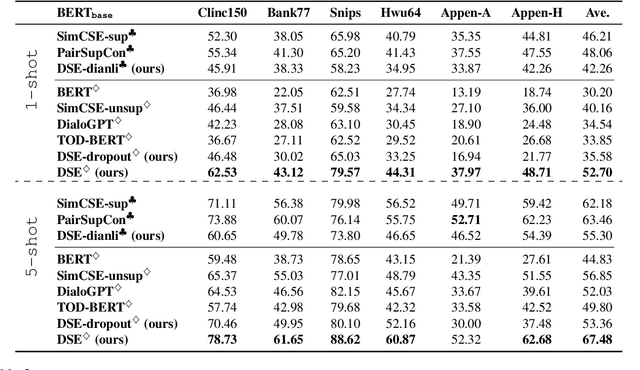
Learning high-quality dialogue representations is essential for solving a variety of dialogue-oriented tasks, especially considering that dialogue systems often suffer from data scarcity. In this paper, we introduce Dialogue Sentence Embedding (DSE), a self-supervised contrastive learning method that learns effective dialogue representations suitable for a wide range of dialogue tasks. DSE learns from dialogues by taking consecutive utterances of the same dialogue as positive pairs for contrastive learning. Despite its simplicity, DSE achieves significantly better representation capability than other dialogue representation and universal sentence representation models. We evaluate DSE on five downstream dialogue tasks that examine dialogue representation at different semantic granularities. Experiments in few-shot and zero-shot settings show that DSE outperforms baselines by a large margin. For example, it achieves 13 average performance improvement over the strongest unsupervised baseline in 1-shot intent classification on 6 datasets. We also provide analyses on the benefits and limitations of our model.
Self-Supervised Speaker Verification with Simple Siamese Network and Self-Supervised Regularization
Dec 08, 2021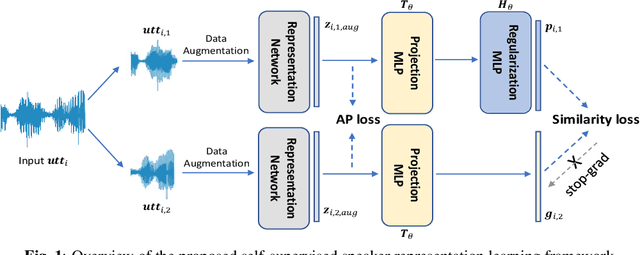

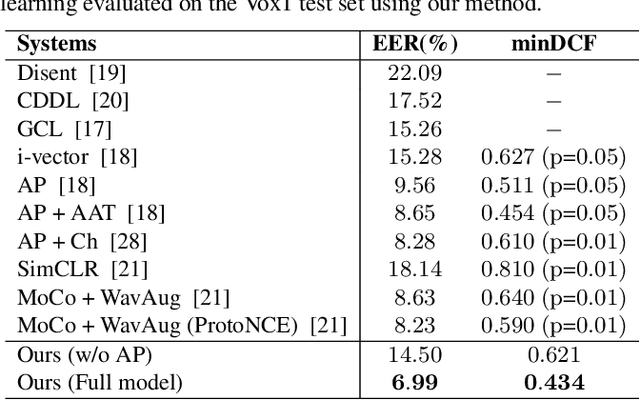

Training speaker-discriminative and robust speaker verification systems without speaker labels is still challenging and worthwhile to explore. In this study, we propose an effective self-supervised learning framework and a novel regularization strategy to facilitate self-supervised speaker representation learning. Different from contrastive learning-based self-supervised learning methods, the proposed self-supervised regularization (SSReg) focuses exclusively on the similarity between the latent representations of positive data pairs. We also explore the effectiveness of alternative online data augmentation strategies on both the time domain and frequency domain. With our strong online data augmentation strategy, the proposed SSReg shows the potential of self-supervised learning without using negative pairs and it can significantly improve the performance of self-supervised speaker representation learning with a simple Siamese network architecture. Comprehensive experiments on the VoxCeleb datasets demonstrate that our proposed self-supervised approach obtains a 23.4% relative improvement by adding the effective self-supervised regularization and outperforms other previous works.
Virtual Augmentation Supported Contrastive Learning of Sentence Representations
Oct 16, 2021


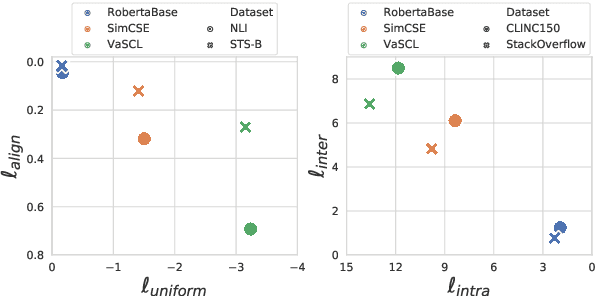
Despite profound successes, contrastive representation learning relies on carefully designed data augmentations using domain specific knowledge. This challenge is magnified in natural language processing where no general rules exist for data augmentation due to the discrete nature of natural language. We tackle this challenge by presenting a Virtual augmentation Supported Contrastive Learning of sentence representations (VaSCL). Originating from the interpretation that data augmentation essentially constructs the neighborhoods of each training instance, we in turn utilize the neighborhood to generate effective data augmentations. Leveraging the large training batch size of contrastive learning, we approximate the neighborhood of an instance via its K-nearest in-batch neighbors in the representation space. We then define an instance discrimination task within this neighborhood, and generate the virtual augmentation in an adversarial training manner. We access the performance of VaSCL on a wide range of downstream tasks, and set a new state-of-the-art for unsupervised sentence representation learning.
Pairwise Supervised Contrastive Learning of Sentence Representations
Sep 12, 2021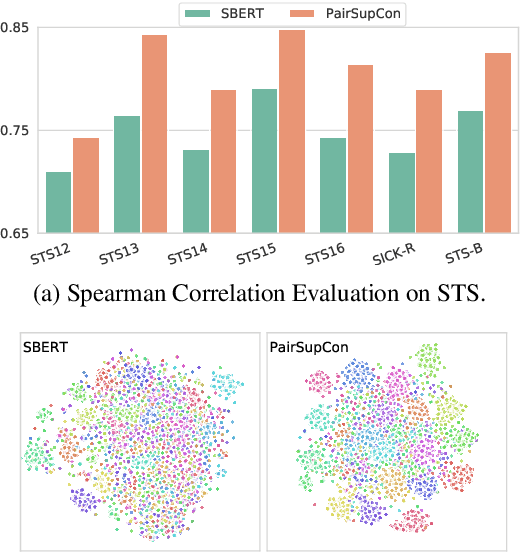
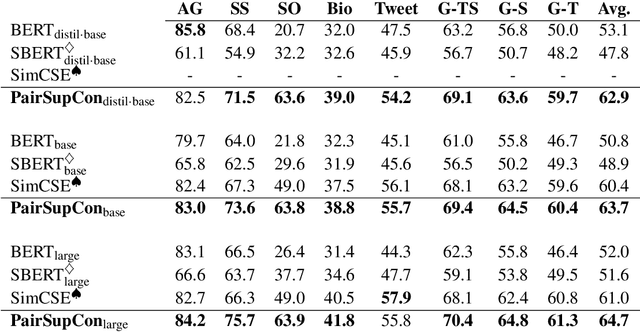


Many recent successes in sentence representation learning have been achieved by simply fine-tuning on the Natural Language Inference (NLI) datasets with triplet loss or siamese loss. Nevertheless, they share a common weakness: sentences in a contradiction pair are not necessarily from different semantic categories. Therefore, optimizing the semantic entailment and contradiction reasoning objective alone is inadequate to capture the high-level semantic structure. The drawback is compounded by the fact that the vanilla siamese or triplet losses only learn from individual sentence pairs or triplets, which often suffer from bad local optima. In this paper, we propose PairSupCon, an instance discrimination based approach aiming to bridge semantic entailment and contradiction understanding with high-level categorical concept encoding. We evaluate PairSupCon on various downstream tasks that involve understanding sentence semantics at different granularities. We outperform the previous state-of-the-art method with $10\%$--$13\%$ averaged improvement on eight clustering tasks, and $5\%$--$6\%$ averaged improvement on seven semantic textual similarity (STS) tasks.
Contrastive Fine-tuning Improves Robustness for Neural Rankers
May 27, 2021
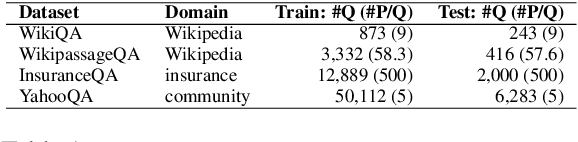

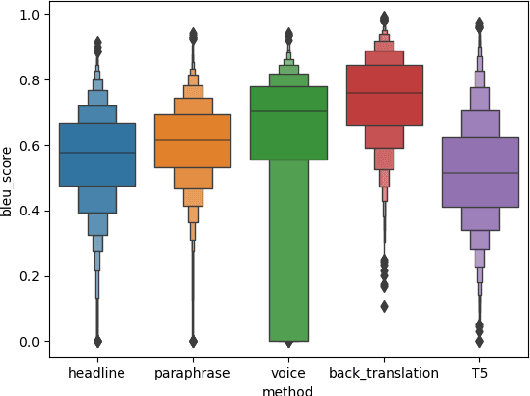
The performance of state-of-the-art neural rankers can deteriorate substantially when exposed to noisy inputs or applied to a new domain. In this paper, we present a novel method for fine-tuning neural rankers that can significantly improve their robustness to out-of-domain data and query perturbations. Specifically, a contrastive loss that compares data points in the representation space is combined with the standard ranking loss during fine-tuning. We use relevance labels to denote similar/dissimilar pairs, which allows the model to learn the underlying matching semantics across different query-document pairs and leads to improved robustness. In experiments with four passage ranking datasets, the proposed contrastive fine-tuning method obtains improvements on robustness to query reformulations, noise perturbations, and zero-shot transfer for both BERT and BART based rankers. Additionally, our experiments show that contrastive fine-tuning outperforms data augmentation for robustifying neural rankers.
Improving Factual Consistency of Abstractive Summarization via Question Answering
May 10, 2021

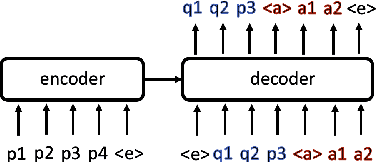

A commonly observed problem with the state-of-the art abstractive summarization models is that the generated summaries can be factually inconsistent with the input documents. The fact that automatic summarization may produce plausible-sounding yet inaccurate summaries is a major concern that limits its wide application. In this paper we present an approach to address factual consistency in summarization. We first propose an efficient automatic evaluation metric to measure factual consistency; next, we propose a novel learning algorithm that maximizes the proposed metric during model training. Through extensive experiments, we confirm that our method is effective in improving factual consistency and even overall quality of the summaries, as judged by both automatic metrics and human evaluation.
Answering Ambiguous Questions through Generative Evidence Fusion and Round-Trip Prediction
Nov 26, 2020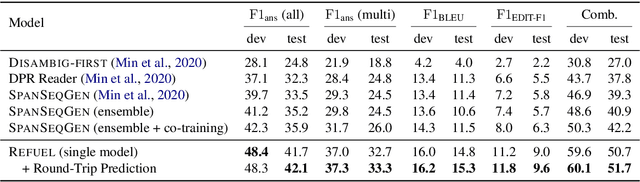

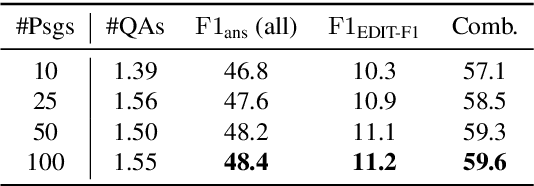

In open-domain question answering, questions are highly likely to be ambiguous because users may not know the scope of relevant topics when formulating them. Therefore, a system needs to find every possible interpretation of the question, and propose a set of disambiguated question-answer pairs. In this paper, we present a model that aggregates and combines evidence from multiple passages to generate question-answer pairs. Particularly, our model reads a large number of passages to find as many interpretations as possible. In addition, we propose a novel round-trip prediction approach to generate additional interpretations that our model fails to find in the first pass, and then verify and filter out the incorrect question-answer pairs to arrive at the final disambiguated output. On the recently introduced AmbigQA open-domain question answering dataset, our model, named Refuel, achieves a new state-of-the-art, outperforming the previous best model by a large margin. We also conduct comprehensive analyses to validate the effectiveness of our proposed round-trip prediction.
Guessing What's Plausible But Remembering What's True: Accurate Neural Reasoning for Question-Answering
Apr 07, 2020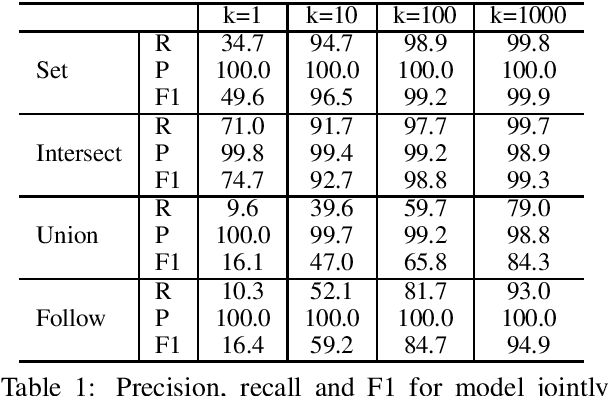
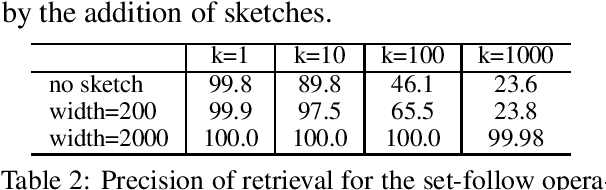

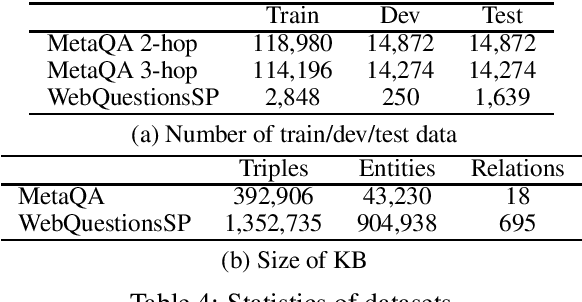
Neural approaches to natural language processing (NLP) often fail at the logical reasoning needed for deeper language understanding. In particular, neural approaches to reasoning that rely on embedded \emph{generalizations} of a knowledge base (KB) implicitly model which facts that are \emph{plausible}, but may not model which facts are \emph{true}, according to the KB. While generalizing the facts in a KB is useful for KB completion, the inability to distinguish between plausible inferences and logically entailed conclusions can be problematic in settings like as KB question answering (KBQA). We propose here a novel KB embedding scheme that supports generalization, but also allows accurate logical reasoning with a KB. Our approach introduces two new mechanisms for KB reasoning: neural retrieval over a set of embedded triples, and "memorization" of highly specific information with a compact sketch structure. Experimentally, this leads to substantial improvements over the state-of-the-art on two KBQA benchmarks.
Instance-based Transfer Learning for Multilingual Deep Retrieval
Nov 08, 2019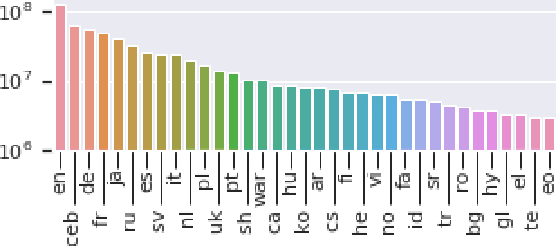
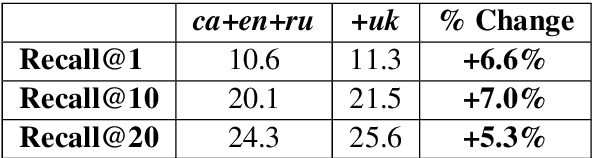


Perhaps the simplest type of multilingual transfer learning is instance-based transfer learning, in which data from the target language and the auxiliary languages are pooled, and a single model is learned from the pooled data. It is not immediately obvious when instance-based transfer learning will improve performance in this multilingual setting: for instance, a plausible conjecture is this kind of transfer learning would help only if the auxiliary languages were very similar to the target. Here we show that at large scale, this method is surprisingly effective, leading to positive transfer on all of 35 target languages we tested. We analyze this improvement and argue that the most natural explanation, namely direct vocabulary overlap between languages, only partially explains the performance gains: in fact, we demonstrate target-language improvement can occur after adding data from an auxiliary language with no vocabulary in common with the target. This surprising result is due to the effect of transitive vocabulary overlaps between pairs of auxiliary and target languages.