 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgenticTagger: Structured Item Representation for Recommendation with LLM Agents
Feb 05, 2026High-quality representations are a core requirement for effective recommendation. In this work, we study the problem of LLM-based descriptor generation, i.e., keyphrase-like natural language item representation generation frameworks with minimal constraints on downstream applications. We propose AgenticTagger, a framework that queries LLMs for representing items with sequences of text descriptors. However, open-ended generation provides little control over the generation space, leading to high cardinality, low-performance descriptors that renders downstream modeling challenging. To this end, AgenticTagger features two core stages: (1) a vocabulary building stage where a set of hierarchical, low-cardinality, and high-quality descriptors is identified, and (2) a vocabulary assignment stage where LLMs assign in-vocabulary descriptors to items. To effectively and efficiently ground vocabulary in the item corpus of interest, we design a multi-agent reflection mechanism where an architect LLM iteratively refines the vocabulary guided by parallelized feedback from annotator LLMs that validates the vocabulary against item data. Experiments on public and private data show AgenticTagger brings consistent improvements across diverse recommendation scenarios, including generative and term-based retrieval, ranking, and controllability-oriented, critique-based recommendation.
Lightweight Super Resolution-enabled Coding Model for the JPEG Pleno Learning-based Point Cloud Coding Standard
Jan 31, 2026While point cloud-based applications are gaining traction due to their ability to provide rich and immersive experiences, they critically need efficient coding solutions due to the large volume of data involved, often many millions of points per object. The JPEG Pleno Learning-based Point Cloud Coding standard, as the first learning-based coding standard for static point clouds, has set a foundational framework with very competitive compression performance regarding the relevant conventional and learning-based alternative point cloud coding solutions. This paper proposes a novel lightweight point cloud geometry coding model that significantly reduces the complexity of the standard, which is essential for the broad adoption of this coding standard, particularly in resource-constrained environments, while simultaneously achieving small average compression efficiency benefits. The novel coding model is based on the pioneering adoption of a compressed domain approach for the super-resolution model, in addition to a major reduction of the number of latent channels. A reduction of approximately 70% in the total number of model parameters is achieved while simultaneously offering slight average compression performance gains for the JPEG Pleno Point Cloud coding dataset.
The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
Dec 11, 2025We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .
Point Cloud Geometry Scalable Coding Using a Resolution and Quality-conditioned Latents Probability Estimator
Feb 19, 2025In the current age, users consume multimedia content in very heterogeneous scenarios in terms of network, hardware, and display capabilities. A naive solution to this problem is to encode multiple independent streams, each covering a different possible requirement for the clients, with an obvious negative impact in both storage and computational requirements. These drawbacks can be avoided by using codecs that enable scalability, i.e., the ability to generate a progressive bitstream, containing a base layer followed by multiple enhancement layers, that allow decoding the same bitstream serving multiple reconstructions and visualization specifications. While scalable coding is a well-known and addressed feature in conventional image and video codecs, this paper focuses on a new and very different problem, notably the development of scalable coding solutions for deep learning-based Point Cloud (PC) coding. The peculiarities of this 3D representation make it hard to implement flexible solutions that do not compromise the other functionalities of the codec. This paper proposes a joint quality and resolution scalability scheme, named Scalable Resolution and Quality Hyperprior (SRQH), that, contrary to previous solutions, can model the relationship between latents obtained with models trained for different RD tradeoffs and/or at different resolutions. Experimental results obtained by integrating SRQH in the emerging JPEG Pleno learning-based PC coding standard show that SRQH allows decoding the PC at different qualities and resolutions with a single bitstream while incurring only in a limited RD penalty and increment in complexity w.r.t. non-scalable JPEG PCC that would require one bitstream per coding configuration.
Deep Learning-based Event Data Coding: A Joint Spatiotemporal and Polarity Solution
Feb 05, 2025



Neuromorphic vision sensors, commonly referred to as event cameras, have recently gained relevance for applications requiring high-speed, high dynamic range and low-latency data acquisition. Unlike traditional frame-based cameras that capture 2D images, event cameras generate a massive number of pixel-level events, composed by spatiotemporal and polarity information, with very high temporal resolution, thus demanding highly efficient coding solutions. Existing solutions focus on lossless coding of event data, assuming that no distortion is acceptable for the target use cases, mostly including computer vision tasks. One promising coding approach exploits the similarity between event data and point clouds, thus allowing to use current point cloud coding solutions to code event data, typically adopting a two-point clouds representation, one for each event polarity. This paper proposes a novel lossy Deep Learning-based Joint Event data Coding (DL-JEC) solution adopting a single-point cloud representation, thus enabling to exploit the correlation between the spatiotemporal and polarity event information. DL-JEC can achieve significant compression performance gains when compared with relevant conventional and DL-based state-of-the-art event data coding solutions. Moreover, it is shown that it is possible to use lossy event data coding with its reduced rate regarding lossless coding without compromising the target computer vision task performance, notably for event classification. The use of novel adaptive voxel binarization strategies, adapted to the target task, further enables DL-JEC to reach a superior performance.
The JPEG Pleno Learning-based Point Cloud Coding Standard: Serving Man and Machine
Sep 12, 2024Efficient point cloud coding has become increasingly critical for multiple applications such as virtual reality, autonomous driving, and digital twin systems, where rich and interactive 3D data representations may functionally make the difference. Deep learning has emerged as a powerful tool in this domain, offering advanced techniques for compressing point clouds more efficiently than conventional coding methods while also allowing effective computer vision tasks performed in the compressed domain thus, for the first time, making available a common compressed visual representation effective for both man and machine. Taking advantage of this potential, JPEG has recently finalized the JPEG Pleno Learning-based Point Cloud Coding (PCC) standard offering efficient lossy coding of static point clouds, targeting both human visualization and machine processing by leveraging deep learning models for geometry and color coding. The geometry is processed directly in its original 3D form using sparse convolutional neural networks, while the color data is projected onto 2D images and encoded using the also learning-based JPEG AI standard. The goal of this paper is to provide a complete technical description of the JPEG PCC standard, along with a thorough benchmarking of its performance against the state-of-the-art, while highlighting its main strengths and weaknesses. In terms of compression performance, JPEG PCC outperforms the conventional MPEG PCC standards, especially in geometry coding, achieving significant rate reductions. Color compression performance is less competitive but this is overcome by the power of a full learning-based coding framework for both geometry and color and the associated effective compressed domain processing.
Double Deep Learning-based Event Data Coding and Classification
Jul 22, 2024Event cameras have the ability to capture asynchronous per-pixel brightness changes, called "events", offering advantages over traditional frame-based cameras for computer vision applications. Efficiently coding event data is critical for transmission and storage, given the significant volume of events. This paper proposes a novel double deep learning-based architecture for both event data coding and classification, using a point cloud-based representation for events. In this context, the conversions from events to point clouds and back to events are key steps in the proposed solution, and therefore its impact is evaluated in terms of compression and classification performance. Experimental results show that it is possible to achieve a classification performance of compressed events which is similar to one of the original events, even after applying a lossy point cloud codec, notably the recent learning-based JPEG Pleno Point Cloud Coding standard, with a clear rate reduction. Experimental results also demonstrate that events coded using JPEG PCC achieve better classification performance than those coded using the conventional lossy MPEG Geometry-based Point Cloud Coding standard. Furthermore, the adoption of learning-based coding offers high potential for performing computer vision tasks in the compressed domain, which allows skipping the decoding stage while mitigating the impact of coding artifacts.
Point Cloud Geometry Scalable Coding with a Quality-Conditioned Latents Probability Estimator
Apr 11, 2024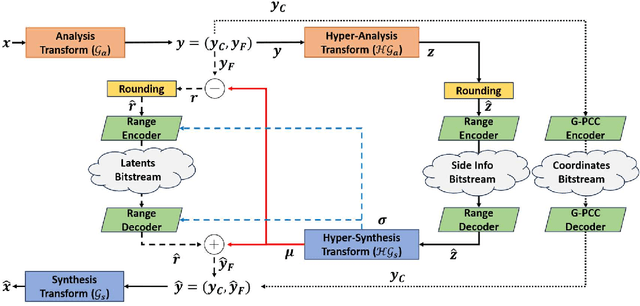
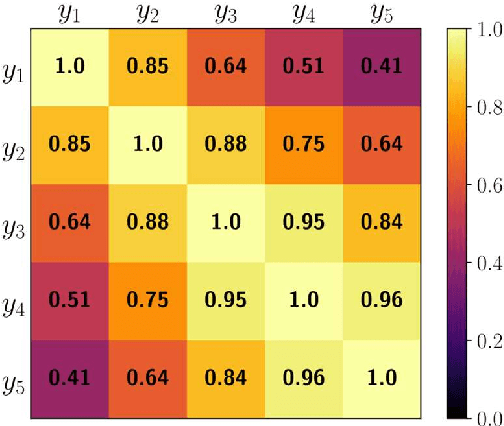

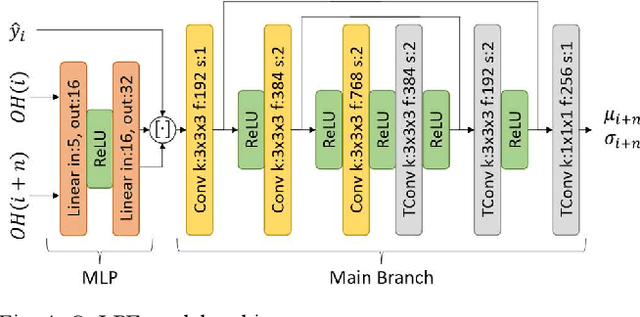
The widespread usage of point clouds (PC) for immersive visual applications has resulted in the use of very heterogeneous receiving conditions and devices, notably in terms of network, hardware, and display capabilities. In this scenario, quality scalability, i.e., the ability to reconstruct a signal at different qualities by progressively decoding a single bitstream, is a major requirement that has yet to be conveniently addressed, notably in most learning-based PC coding solutions. This paper proposes a quality scalability scheme, named Scalable Quality Hyperprior (SQH), adaptable to learning-based static point cloud geometry codecs, which uses a Quality-conditioned Latents Probability Estimator (QuLPE) to decode a high-quality version of a PC learning-based representation, based on an available lower quality base layer. SQH is integrated in the future JPEG PC coding standard, allowing to create a layered bitstream that can be used to progressively decode the PC geometry with increasing quality and fidelity. Experimental results show that SQH offers the quality scalability feature with very limited or no compression performance penalty at all when compared with the corresponding non-scalable solution, thus preserving the significant compression gains over other state-of-the-art PC codecs.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Deep Learning-based Compressed Domain Multimedia for Man and Machine: A Taxonomy and Application to Point Cloud Classification
Oct 28, 2023



In the current golden age of multimedia, human visualization is no longer the single main target, with the final consumer often being a machine which performs some processing or computer vision tasks. In both cases, deep learning plays a undamental role in extracting features from the multimedia representation data, usually producing a compressed representation referred to as latent representation. The increasing development and adoption of deep learning-based solutions in a wide area of multimedia applications have opened an exciting new vision where a common compressed multimedia representation is used for both man and machine. The main benefits of this vision are two-fold: i) improved performance for the computer vision tasks, since the effects of coding artifacts are mitigated; and ii) reduced computational complexity, since prior decoding is not required. This paper proposes the first taxonomy for designing compressed domain computer vision solutions driven by the architecture and weights compatibility with an available spatio-temporal computer vision processor. The potential of the proposed taxonomy is demonstrated for the specific case of point cloud classification by designing novel compressed domain processors using the JPEG Pleno Point Cloud Coding standard under development and adaptations of the PointGrid classifier. Experimental results show that the designed compressed domain point cloud classification solutions can significantly outperform the spatial-temporal domain classification benchmarks when applied to the decompressed data, containing coding artifacts, and even surpass their performance when applied to the original uncompressed data.