 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Data for Conversational Music Recommendation Using Random Walks and Language Models
Paper and Code
Jan 27, 2023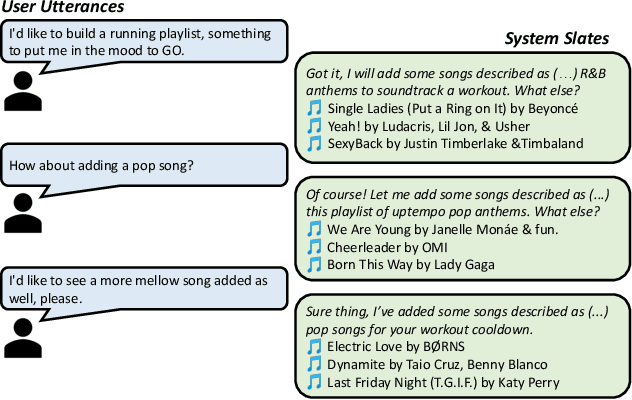
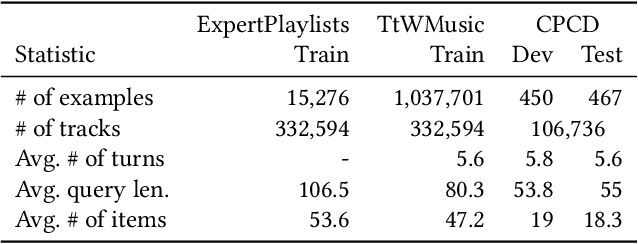
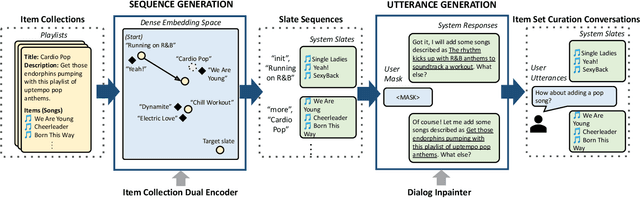

Conversational recommendation systems (CRSs) enable users to use natural language feedback to control their recommendations, overcoming many of the challenges of traditional recommendation systems. However, the practical adoption of CRSs remains limited due to a lack of rich and diverse conversational training data that pairs user utterances with recommendations. To address this problem, we introduce a new method to generate synthetic training data by transforming curated item collections, such as playlists or movie watch lists, into item-seeking conversations. First, we use a biased random walk to generate a sequence of slates, or sets of item recommendations; then, we use a language model to generate corresponding user utterances. We demonstrate our approach by generating a conversational music recommendation dataset with over one million conversations, which were found to be consistent with relevant recommendations by a crowdsourced evaluation. Using the synthetic data to train a CRS, we significantly outperform standard retrieval baselines in offline and online evaluations.