 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single Items: Exploring User Preferences in Item Sets with the Conversational Playlist Curation Dataset
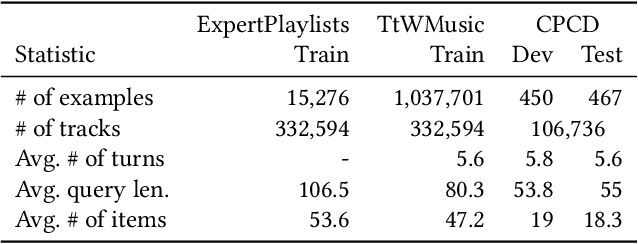
Mar 13, 2023Users in consumption domains, like music, are often able to more efficiently provide preferences over a set of items (e.g. a playlist or radio) than over single items (e.g. songs). Unfortunately, this is an underexplored area of research, with most existing recommendation systems limited to understanding preferences over single items. Curating an item set exponentiates the search space that recommender systems must consider (all subsets of items!): this motivates conversational approaches-where users explicitly state or refine their preferences and systems elicit preferences in natural language-as an efficient way to understand user needs. We call this task conversational item set curation and present a novel data collection methodology that efficiently collects realistic preferences about item sets in a conversational setting by observing both item-level and set-level feedback. We apply this methodology to music recommendation to build the Conversational Playlist Curation Dataset (CPCD), where we show that it leads raters to express preferences that would not be otherwise expressed. Finally, we propose a wide range of conversational retrieval models as baselines for this task and evaluate them on the dataset.
Generating Synthetic Data for Conversational Music Recommendation Using Random Walks and Language Models
Jan 27, 2023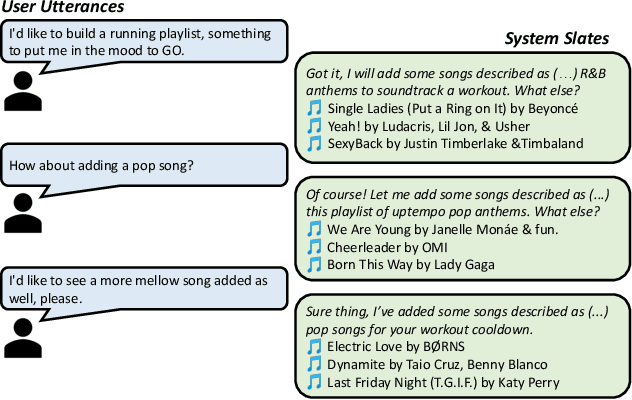
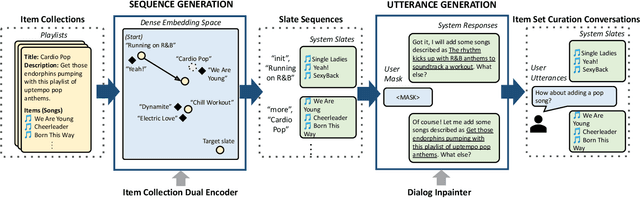

Conversational recommendation systems (CRSs) enable users to use natural language feedback to control their recommendations, overcoming many of the challenges of traditional recommendation systems. However, the practical adoption of CRSs remains limited due to a lack of rich and diverse conversational training data that pairs user utterances with recommendations. To address this problem, we introduce a new method to generate synthetic training data by transforming curated item collections, such as playlists or movie watch lists, into item-seeking conversations. First, we use a biased random walk to generate a sequence of slates, or sets of item recommendations; then, we use a language model to generate corresponding user utterances. We demonstrate our approach by generating a conversational music recommendation dataset with over one million conversations, which were found to be consistent with relevant recommendations by a crowdsourced evaluation. Using the synthetic data to train a CRS, we significantly outperform standard retrieval baselines in offline and online evaluations.
Attributed Text Generation via Post-hoc Research and Revision
Oct 17, 2022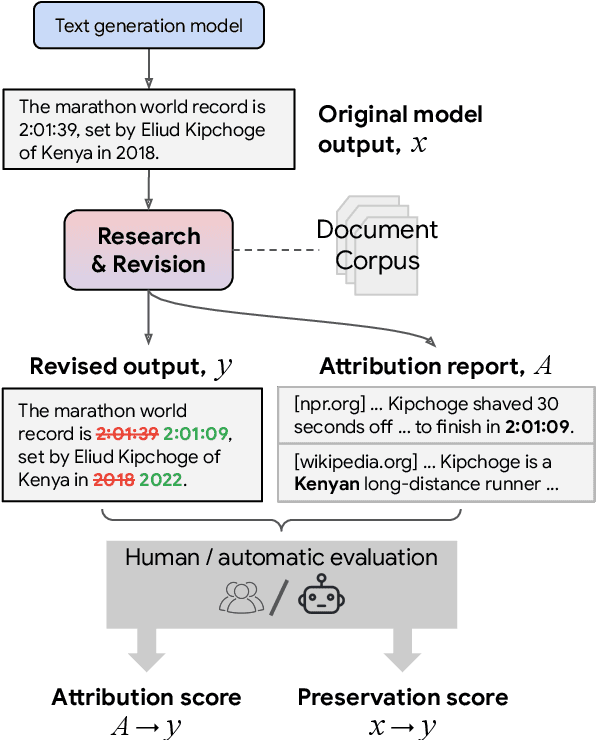
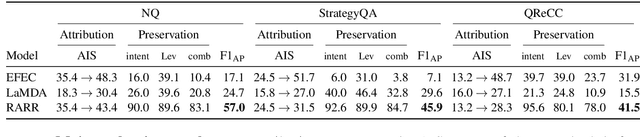
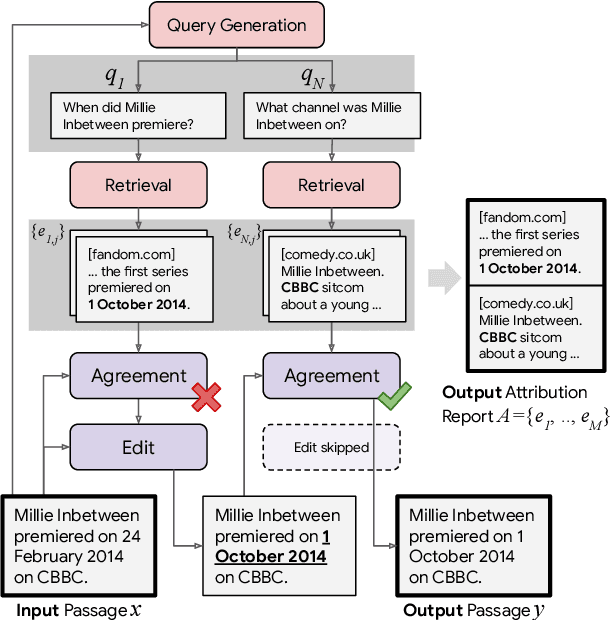
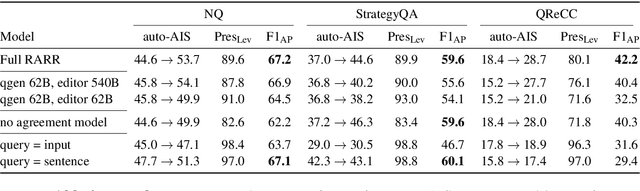
Language models (LMs) now excel at many tasks such as few-shot learning, question answering, reasoning, and dialog. However, they sometimes generate unsupported or misleading content. A user cannot easily determine whether their outputs are trustworthy or not, because most LMs do not have any built-in mechanism for attribution to external evidence. To enable attribution while still preserving all the powerful advantages of recent generation models, we propose RARR (Retrofit Attribution using Research and Revision), a system that 1) automatically finds attribution for the output of any text generation model and 2) post-edits the output to fix unsupported content while preserving the original output as much as possible. When applied to the output of several state-of-the-art LMs on a diverse set of generation tasks, we find that RARR significantly improves attribution while otherwise preserving the original input to a much greater degree than previously explored edit models. Furthermore, the implementation of RARR requires only a handful of training examples, a large language model, and standard web search.
Dialog Inpainting: Turning Documents into Dialogs
May 31, 2022
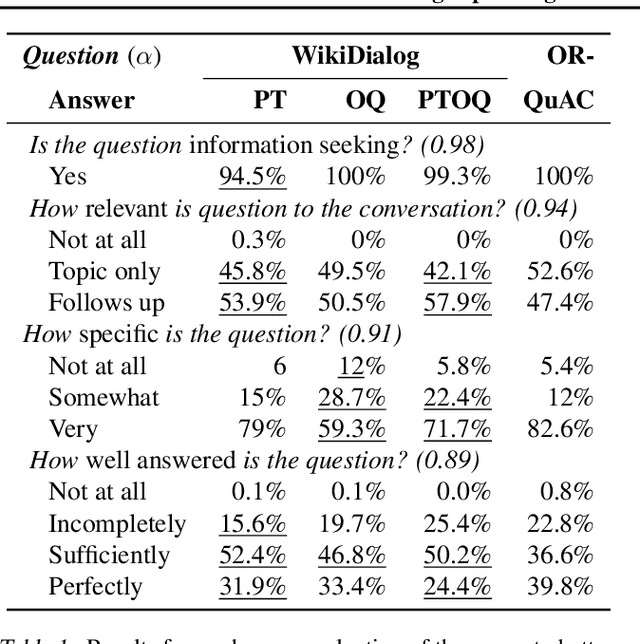
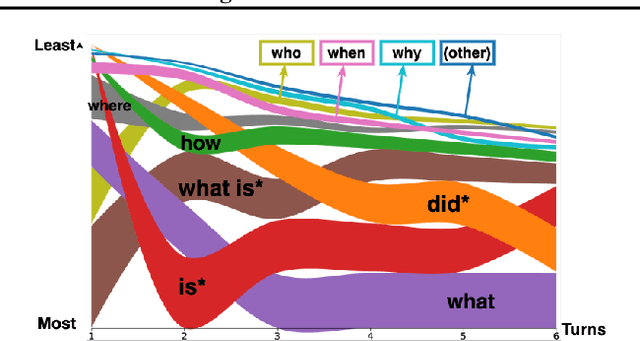
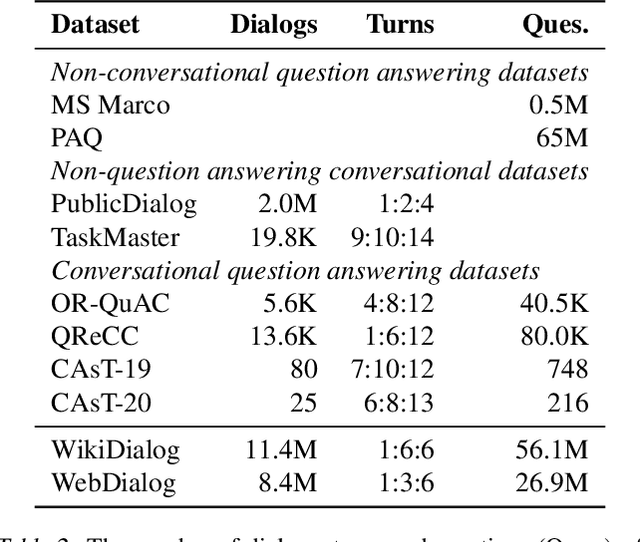
Many important questions (e.g. "How to eat healthier?") require conversation to establish context and explore in depth. However, conversational question answering (ConvQA) systems have long been stymied by scarce training data that is expensive to collect. To address this problem, we propose a new technique for synthetically generating diverse and high-quality dialog data: dialog inpainting. Our approach takes the text of any document and transforms it into a two-person dialog between the writer and an imagined reader: we treat sentences from the article as utterances spoken by the writer, and then use a dialog inpainter to predict what the imagined reader asked or said in between each of the writer's utterances. By applying this approach to passages from Wikipedia and the web, we produce WikiDialog and WebDialog, two datasets totalling 19 million diverse information-seeking dialogs -- 1,000x larger than the largest existing ConvQA dataset. Furthermore, human raters judge the answer adequacy and conversationality of WikiDialog to be as good or better than existing manually-collected datasets. Using our inpainted data to pre-train ConvQA retrieval systems, we significantly advance state-of-the-art across three benchmarks (QReCC, OR-QuAC, TREC CAsT) yielding up to 40% relative gains on standard evaluation metrics.
Conformal retrofitting via Riemannian manifolds: distilling task-specific graphs into pretrained embeddings
Oct 09, 2020
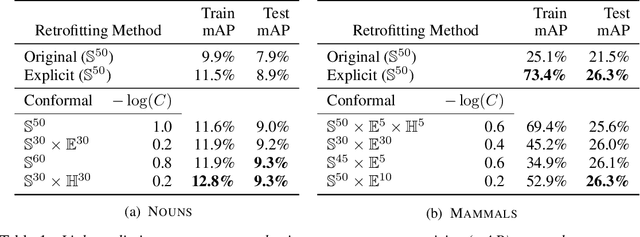
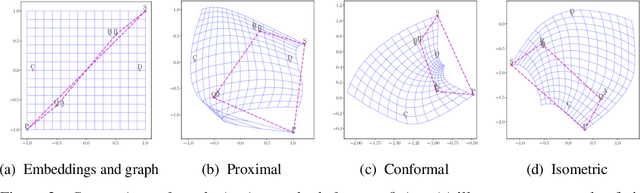
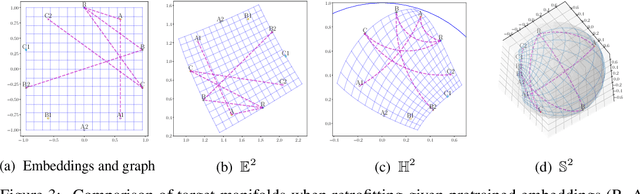
Pretrained (language) embeddings are versatile, task-agnostic feature representations of entities, like words, that are central to many machine learning applications. These representations can be enriched through retrofitting, a class of methods that incorporate task-specific domain knowledge encoded as a graph over a subset of these entities. However, existing retrofitting algorithms face two limitations: they overfit the observed graph by failing to represent relationships with missing entities; and they underfit the observed graph by only learning embeddings in Euclidean manifolds, which cannot faithfully represent even simple tree-structured or cyclic graphs. We address these problems with two key contributions: (i) we propose a novel regularizer, a conformality regularizer, that preserves local geometry from the pretrained embeddings---enabling generalization to missing entities and (ii) a new Riemannian feedforward layer that learns to map pre-trained embeddings onto a non-Euclidean manifold that can better represent the entire graph. Through experiments on WordNet, we demonstrate that the conformality regularizer prevents even existing (Euclidean-only) methods from overfitting on link prediction for missing entities, and---together with the Riemannian feedforward layer---learns non-Euclidean embeddings that outperform them.
Textual Analogy Parsing: What's Shared and What's Compared among Analogous Facts
Sep 07, 2018

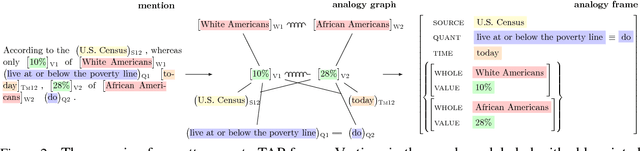
To understand a sentence like "whereas only 10% of White Americans live at or below the poverty line, 28% of African Americans do" it is important not only to identify individual facts, e.g., poverty rates of distinct demographic groups, but also the higher-order relations between them, e.g., the disparity between them. In this paper, we propose the task of Textual Analogy Parsing (TAP) to model this higher-order meaning. The output of TAP is a frame-style meaning representation which explicitly specifies what is shared (e.g., poverty rates) and what is compared (e.g., White Americans vs. African Americans, 10% vs. 28%) between its component facts. Such a meaning representation can enable new applications that rely on discourse understanding such as automated chart generation from quantitative text. We present a new dataset for TAP, baselines, and a model that successfully uses an ILP to enforce the structural constraints of the problem.
The price of debiasing automatic metrics in natural language evaluation
Jul 06, 2018

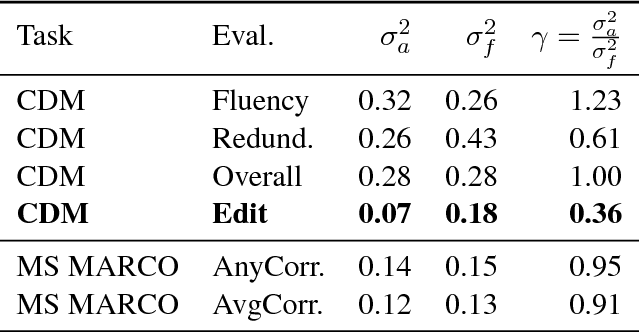

For evaluating generation systems, automatic metrics such as BLEU cost nothing to run but have been shown to correlate poorly with human judgment, leading to systematic bias against certain model improvements. On the other hand, averaging human judgments, the unbiased gold standard, is often too expensive. In this paper, we use control variates to combine automatic metrics with human evaluation to obtain an unbiased estimator with lower cost than human evaluation alone. In practice, however, we obtain only a 7-13% cost reduction on evaluating summarization and open-response question answering systems. We then prove that our estimator is optimal: there is no unbiased estimator with lower cost. Our theory further highlights the two fundamental bottlenecks---the automatic metric and the prompt shown to human evaluators---both of which need to be improved to obtain greater cost savings.
How Much is 131 Million Dollars? Putting Numbers in Perspective with Compositional Descriptions
Sep 01, 2016



How much is 131 million US dollars? To help readers put such numbers in context, we propose a new task of automatically generating short descriptions known as perspectives, e.g. "$131 million is about the cost to employ everyone in Texas over a lunch period". First, we collect a dataset of numeric mentions in news articles, where each mention is labeled with a set of rated perspectives. We then propose a system to generate these descriptions consisting of two steps: formula construction and description generation. In construction, we compose formulae from numeric facts in a knowledge base and rank the resulting formulas based on familiarity, numeric proximity and semantic compatibility. In generation, we convert a formula into natural language using a sequence-to-sequence recurrent neural network. Our system obtains a 15.2% F1 improvement over a non-compositional baseline at formula construction and a 12.5 BLEU point improvement over a baseline description generation.
Estimating Mixture Models via Mixtures of Polynomials
Mar 28, 2016

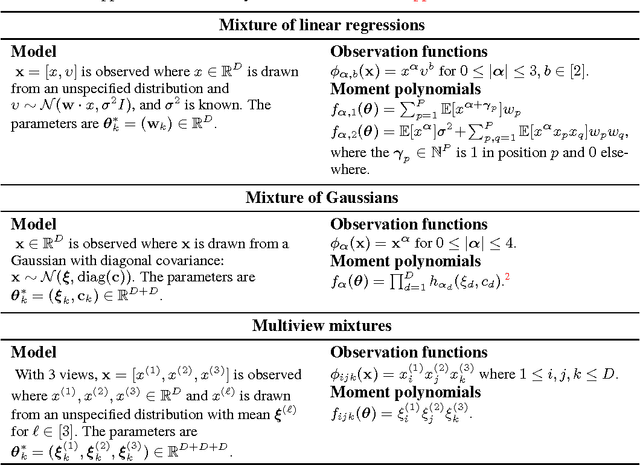

Mixture modeling is a general technique for making any simple model more expressive through weighted combination. This generality and simplicity in part explains the success of the Expectation Maximization (EM) algorithm, in which updates are easy to derive for a wide class of mixture models. However, the likelihood of a mixture model is non-convex, so EM has no known global convergence guarantees. Recently, method of moments approaches offer global guarantees for some mixture models, but they do not extend easily to the range of mixture models that exist. In this work, we present Polymom, an unifying framework based on method of moments in which estimation procedures are easily derivable, just as in EM. Polymom is applicable when the moments of a single mixture component are polynomials of the parameters. Our key observation is that the moments of the mixture model are a mixture of these polynomials, which allows us to cast estimation as a Generalized Moment Problem. We solve its relaxations using semidefinite optimization, and then extract parameters using ideas from computer algebra. This framework allows us to draw insights and apply tools from convex optimization, computer algebra and the theory of moments to study problems in statistical estimation.
Tensor Factorization via Matrix Factorization
May 18, 2015



Tensor factorization arises in many machine learning applications, such knowledge base modeling and parameter estimation in latent variable models. However, numerical methods for tensor factorization have not reached the level of maturity of matrix factorization methods. In this paper, we propose a new method for CP tensor factorization that uses random projections to reduce the problem to simultaneous matrix diagonalization. Our method is conceptually simple and also applies to non-orthogonal and asymmetric tensors of arbitrary order. We prove that a small number random projections essentially preserves the spectral information in the tensor, allowing us to remove the dependence on the eigengap that plagued earlier tensor-to-matrix reductions. Experimentally, our method outperforms existing tensor factorization methods on both simulated data and two real datasets.