 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal retrofitting via Riemannian manifolds: distilling task-specific graphs into pretrained embeddings
Oct 09, 2020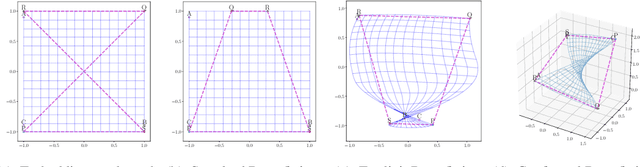
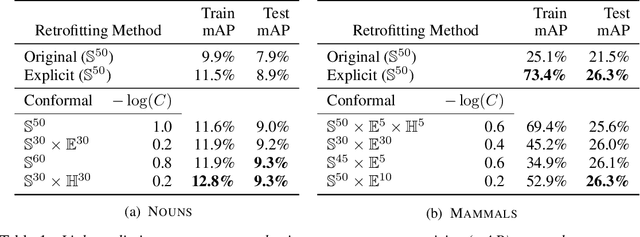
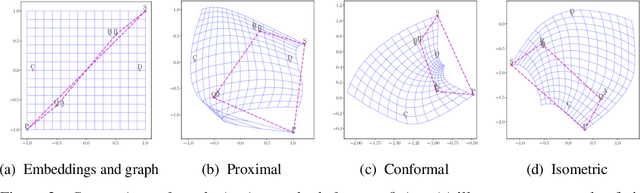
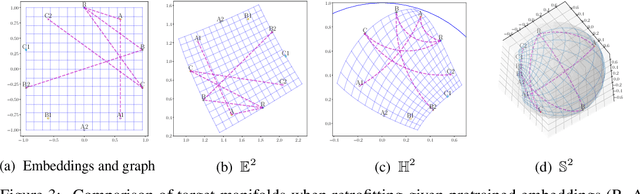
Pretrained (language) embeddings are versatile, task-agnostic feature representations of entities, like words, that are central to many machine learning applications. These representations can be enriched through retrofitting, a class of methods that incorporate task-specific domain knowledge encoded as a graph over a subset of these entities. However, existing retrofitting algorithms face two limitations: they overfit the observed graph by failing to represent relationships with missing entities; and they underfit the observed graph by only learning embeddings in Euclidean manifolds, which cannot faithfully represent even simple tree-structured or cyclic graphs. We address these problems with two key contributions: (i) we propose a novel regularizer, a conformality regularizer, that preserves local geometry from the pretrained embeddings---enabling generalization to missing entities and (ii) a new Riemannian feedforward layer that learns to map pre-trained embeddings onto a non-Euclidean manifold that can better represent the entire graph. Through experiments on WordNet, we demonstrate that the conformality regularizer prevents even existing (Euclidean-only) methods from overfitting on link prediction for missing entities, and---together with the Riemannian feedforward layer---learns non-Euclidean embeddings that outperform them.
Collaboration of AI Agents via Cooperative Multi-Agent Deep Reinforcement Learning
Jun 30, 2019



There are many AI tasks involving multiple interacting agents where agents should learn to cooperate and collaborate to effectively perform the task. Here we develop and evaluate various multi-agent protocols to train agents to collaborate with teammates in grid soccer. We train and evaluate our multi-agent methods against a team operating with a smart hand-coded policy. As a baseline, we train agents concurrently and independently, with no communication. Our collaborative protocols were parameter sharing, coordinated learning with communication, and counterfactual policy gradients. Against the hand-coded team, the team trained with parameter sharing and the team trained with coordinated learning performed the best, scoring on 89.5% and 94.5% of episodes respectively when playing against the hand-coded team. Against the parameter sharing team, with adversarial training the coordinated learning team scored on 75% of the episodes, indicating it is the most adaptable of our methods. The insights gained from our work can be applied to other domains where multi-agent collaboration could be beneficial.