 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single Items: Exploring User Preferences in Item Sets with the Conversational Playlist Curation Dataset
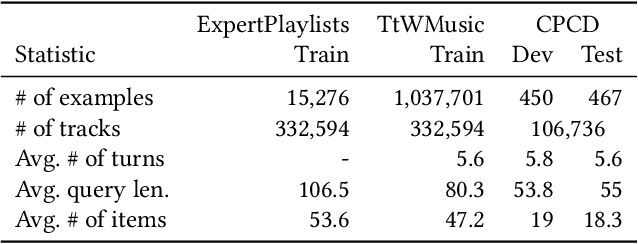
Mar 13, 2023Users in consumption domains, like music, are often able to more efficiently provide preferences over a set of items (e.g. a playlist or radio) than over single items (e.g. songs). Unfortunately, this is an underexplored area of research, with most existing recommendation systems limited to understanding preferences over single items. Curating an item set exponentiates the search space that recommender systems must consider (all subsets of items!): this motivates conversational approaches-where users explicitly state or refine their preferences and systems elicit preferences in natural language-as an efficient way to understand user needs. We call this task conversational item set curation and present a novel data collection methodology that efficiently collects realistic preferences about item sets in a conversational setting by observing both item-level and set-level feedback. We apply this methodology to music recommendation to build the Conversational Playlist Curation Dataset (CPCD), where we show that it leads raters to express preferences that would not be otherwise expressed. Finally, we propose a wide range of conversational retrieval models as baselines for this task and evaluate them on the dataset.
Generating Synthetic Data for Conversational Music Recommendation Using Random Walks and Language Models
Jan 27, 2023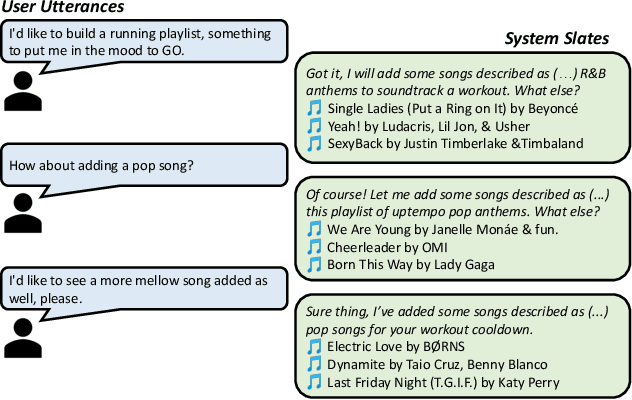
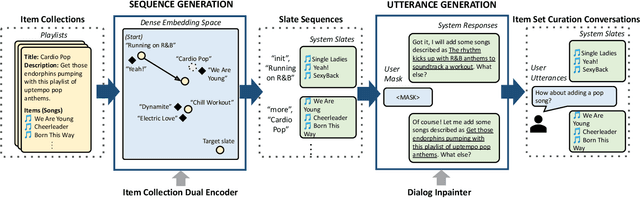

Conversational recommendation systems (CRSs) enable users to use natural language feedback to control their recommendations, overcoming many of the challenges of traditional recommendation systems. However, the practical adoption of CRSs remains limited due to a lack of rich and diverse conversational training data that pairs user utterances with recommendations. To address this problem, we introduce a new method to generate synthetic training data by transforming curated item collections, such as playlists or movie watch lists, into item-seeking conversations. First, we use a biased random walk to generate a sequence of slates, or sets of item recommendations; then, we use a language model to generate corresponding user utterances. We demonstrate our approach by generating a conversational music recommendation dataset with over one million conversations, which were found to be consistent with relevant recommendations by a crowdsourced evaluation. Using the synthetic data to train a CRS, we significantly outperform standard retrieval baselines in offline and online evaluations.
MAQA: A Multimodal QA Benchmark for Negation
Jan 09, 2023
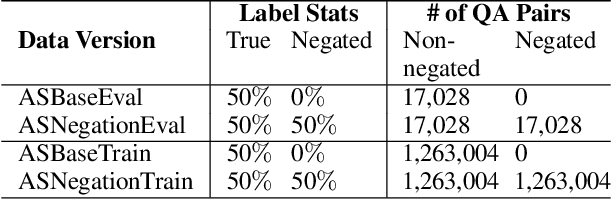
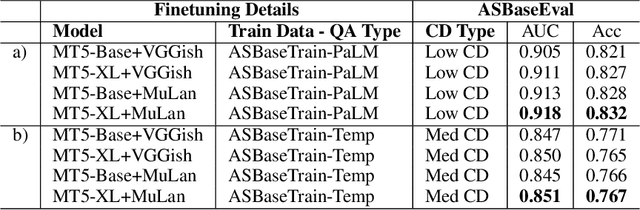
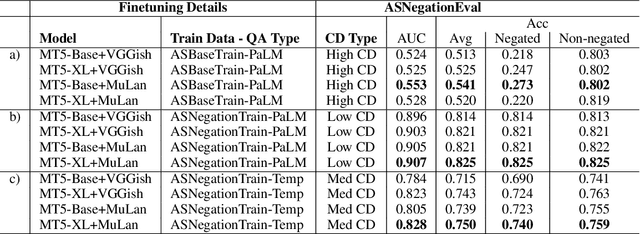
Multimodal learning can benefit from the representation power of pretrained Large Language Models (LLMs). However, state-of-the-art transformer based LLMs often ignore negations in natural language and there is no existing benchmark to quantitatively evaluate whether multimodal transformers inherit this weakness. In this study, we present a new multimodal question answering (QA) benchmark adapted from labeled music videos in AudioSet (Gemmeke et al., 2017) with the goal of systematically evaluating if multimodal transformers can perform complex reasoning to recognize new concepts as negation of previously learned concepts. We show that with standard fine-tuning approach multimodal transformers are still incapable of correctly interpreting negation irrespective of model size. However, our experiments demonstrate that augmenting the original training task distributions with negated QA examples allow the model to reliably reason with negation. To do this, we describe a novel data generation procedure that prompts the 540B-parameter PaLM model to automatically generate negated QA examples as compositions of easily accessible video tags. The generated examples contain more natural linguistic patterns and the gains compared to template-based task augmentation approach are significant.
MuLan: A Joint Embedding of Music Audio and Natural Language
Aug 26, 2022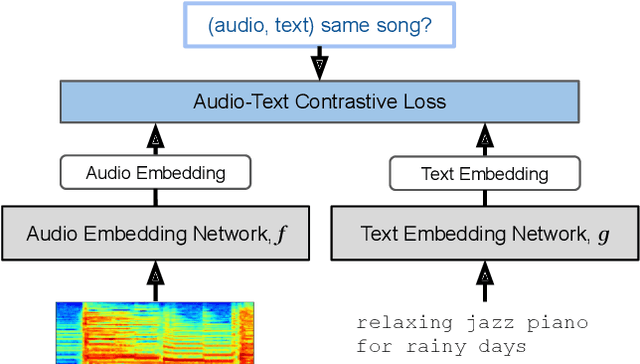


Music tagging and content-based retrieval systems have traditionally been constructed using pre-defined ontologies covering a rigid set of music attributes or text queries. This paper presents MuLan: a first attempt at a new generation of acoustic models that link music audio directly to unconstrained natural language music descriptions. MuLan takes the form of a two-tower, joint audio-text embedding model trained using 44 million music recordings (370K hours) and weakly-associated, free-form text annotations. Through its compatibility with a wide range of music genres and text styles (including conventional music tags), the resulting audio-text representation subsumes existing ontologies while graduating to true zero-shot functionalities. We demonstrate the versatility of the MuLan embeddings with a range of experiments including transfer learning, zero-shot music tagging, language understanding in the music domain, and cross-modal retrieval applications.
A Farewell to Arms: Sequential Reward Maximization on a Budget with a Giving Up Option
Mar 06, 2020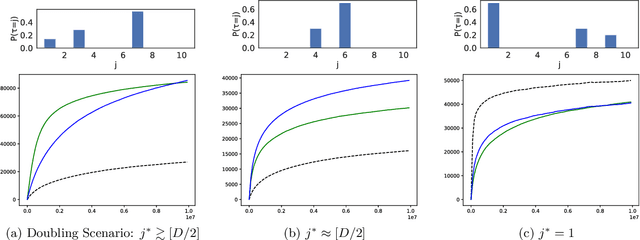
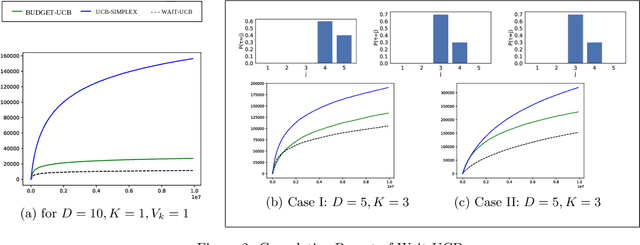
We consider a sequential decision-making problem where an agent can take one action at a time and each action has a stochastic temporal extent, i.e., a new action cannot be taken until the previous one is finished. Upon completion, the chosen action yields a stochastic reward. The agent seeks to maximize its cumulative reward over a finite time budget, with the option of "giving up" on a current action --- hence forfeiting any reward -- in order to choose another action. We cast this problem as a variant of the stochastic multi-armed bandits problem with stochastic consumption of resource. For this problem, we first establish that the optimal arm is the one that maximizes the ratio of the expected reward of the arm to the expected waiting time before the agent sees the reward due to pulling that arm. Using a novel upper confidence bound on this ratio, we then introduce an upper confidence based-algorithm, WAIT-UCB, for which we establish logarithmic, problem-dependent regret bound which has an improved dependence on problem parameters compared to previous works. Simulations on various problem configurations comparing WAIT-UCB against the state-of-the-art algorithms are also presented.
Thompson Sampling for Dynamic Pricing
Feb 08, 2018
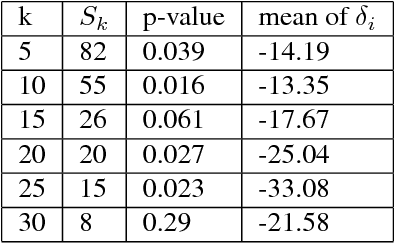
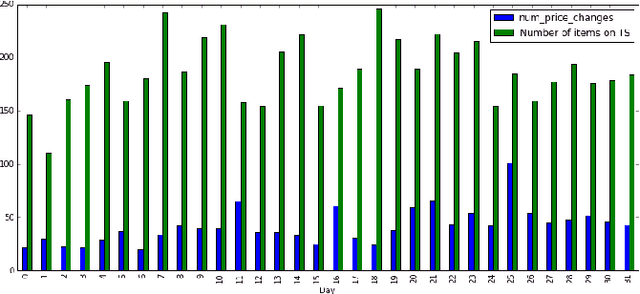
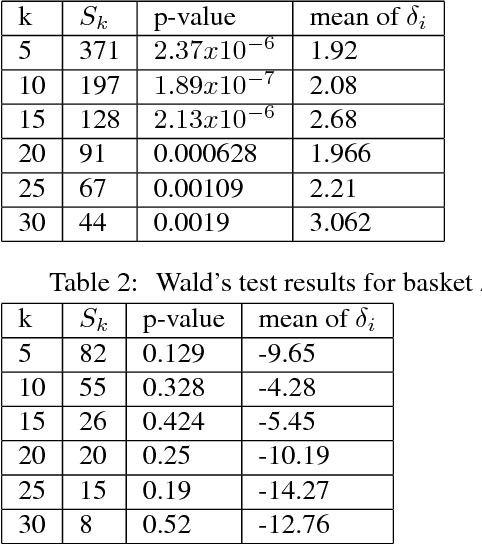
In this paper we apply active learning algorithms for dynamic pricing in a prominent e-commerce website. Dynamic pricing involves changing the price of items on a regular basis, and uses the feedback from the pricing decisions to update prices of the items. Most popular approaches to dynamic pricing use a passive learning approach, where the algorithm uses historical data to learn various parameters of the pricing problem, and uses the updated parameters to generate a new set of prices. We show that one can use active learning algorithms such as Thompson sampling to more efficiently learn the underlying parameters in a pricing problem. We apply our algorithms to a real e-commerce system and show that the algorithms indeed improve revenue compared to pricing algorithms that use passive learning.
On Learning High Dimensional Structured Single Index Models
Nov 29, 2016
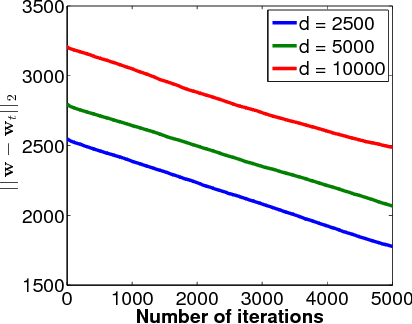


Single Index Models (SIMs) are simple yet flexible semi-parametric models for machine learning, where the response variable is modeled as a monotonic function of a linear combination of features. Estimation in this context requires learning both the feature weights and the nonlinear function that relates features to observations. While methods have been described to learn SIMs in the low dimensional regime, a method that can efficiently learn SIMs in high dimensions, and under general structural assumptions, has not been forthcoming. In this paper, we propose computationally efficient algorithms for SIM inference in high dimensions with structural constraints. Our general approach specializes to sparsity, group sparsity, and low-rank assumptions among others. Experiments show that the proposed method enjoys superior predictive performance when compared to generalized linear models, and achieves results comparable to or better than single layer feedforward neural networks with significantly less computational cost.
Active Algorithms For Preference Learning Problems with Multiple Populations
Jun 22, 2016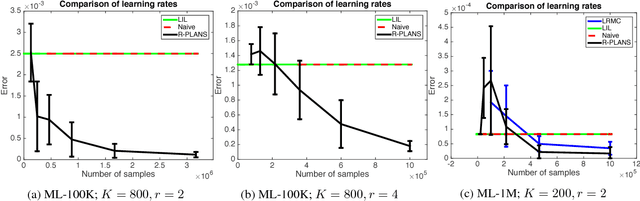
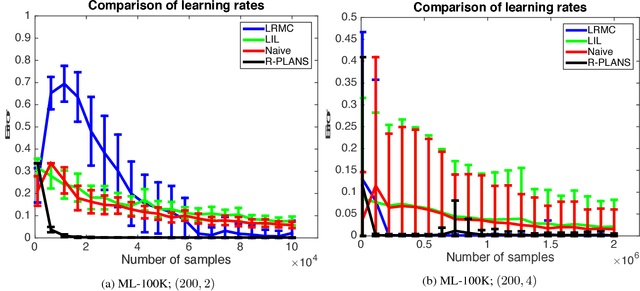
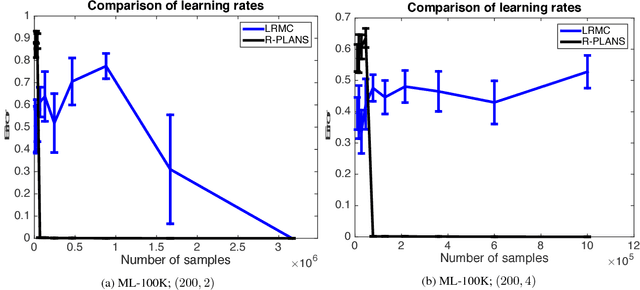
In this paper we model the problem of learning preferences of a population as an active learning problem. We propose an algorithm can adaptively choose pairs of items to show to users coming from a heterogeneous population, and use the obtained reward to decide which pair of items to show next. We provide computationally efficient algorithms with provable sample complexity guarantees for this problem in both the noiseless and noisy cases. In the process of establishing sample complexity guarantees for our algorithms, we establish new results using a Nystr{\"o}m-like method which can be of independent interest. We supplement our theoretical results with experimental comparisons.
Matrix Completion Under Monotonic Single Index Models
Dec 29, 2015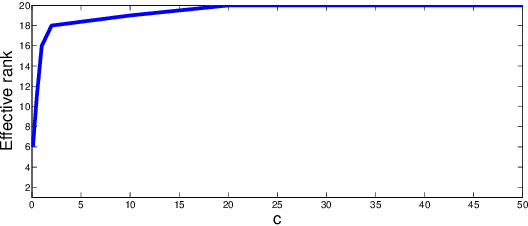

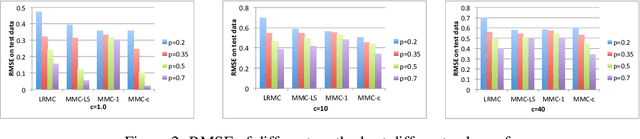
Most recent results in matrix completion assume that the matrix under consideration is low-rank or that the columns are in a union of low-rank subspaces. In real-world settings, however, the linear structure underlying these models is distorted by a (typically unknown) nonlinear transformation. This paper addresses the challenge of matrix completion in the face of such nonlinearities. Given a few observations of a matrix that are obtained by applying a Lipschitz, monotonic function to a low rank matrix, our task is to estimate the remaining unobserved entries. We propose a novel matrix completion method that alternates between low-rank matrix estimation and monotonic function estimation to estimate the missing matrix elements. Mean squared error bounds provide insight into how well the matrix can be estimated based on the size, rank of the matrix and properties of the nonlinear transformation. Empirical results on synthetic and real-world datasets demonstrate the competitiveness of the proposed approach.
Learning Single Index Models in High Dimensions
Jun 30, 2015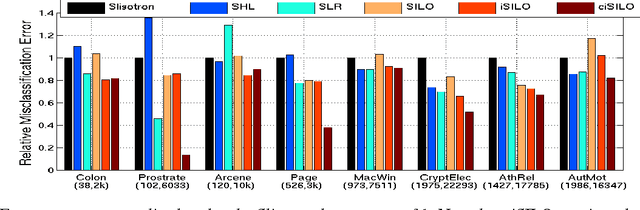

Single Index Models (SIMs) are simple yet flexible semi-parametric models for classification and regression. Response variables are modeled as a nonlinear, monotonic function of a linear combination of features. Estimation in this context requires learning both the feature weights, and the nonlinear function. While methods have been described to learn SIMs in the low dimensional regime, a method that can efficiently learn SIMs in high dimensions has not been forthcoming. We propose three variants of a computationally and statistically efficient algorithm for SIM inference in high dimensions. We establish excess risk bounds for the proposed algorithms and experimentally validate the advantages that our SIM learning methods provide relative to Generalized Linear Model (GLM) and low dimensional SIM based learning methods.