 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Farewell to Arms: Sequential Reward Maximization on a Budget with a Giving Up Option
Paper and Code
Mar 06, 2020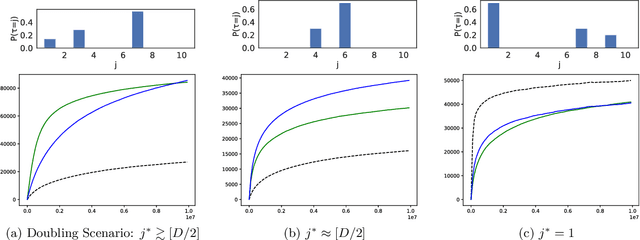
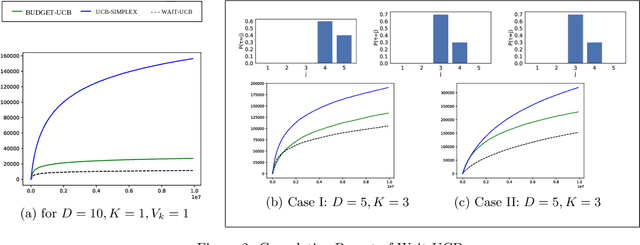
We consider a sequential decision-making problem where an agent can take one action at a time and each action has a stochastic temporal extent, i.e., a new action cannot be taken until the previous one is finished. Upon completion, the chosen action yields a stochastic reward. The agent seeks to maximize its cumulative reward over a finite time budget, with the option of "giving up" on a current action --- hence forfeiting any reward -- in order to choose another action. We cast this problem as a variant of the stochastic multi-armed bandits problem with stochastic consumption of resource. For this problem, we first establish that the optimal arm is the one that maximizes the ratio of the expected reward of the arm to the expected waiting time before the agent sees the reward due to pulling that arm. Using a novel upper confidence bound on this ratio, we then introduce an upper confidence based-algorithm, WAIT-UCB, for which we establish logarithmic, problem-dependent regret bound which has an improved dependence on problem parameters compared to previous works. Simulations on various problem configurations comparing WAIT-UCB against the state-of-the-art algorithms are also presented.