 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Estimation of Last Mile Electric Vehicle Routes
Aug 21, 2024



Last-mile carriers increasingly incorporate electric vehicles (EVs) into their delivery fleet to achieve sustainability goals. This goal presents many challenges across multiple planning spaces including but not limited to how to plan EV routes. In this paper, we address the problem of predicting energy consumption of EVs for Last-Mile delivery routes using deep learning. We demonstrate the need to move away from thinking about range and we propose using energy as the basic unit of analysis. We share a range of deep learning solutions, beginning with a Feed Forward Neural Network (NN) and Recurrent Neural Network (RNN) and demonstrate significant accuracy improvements relative to pure physics-based and distance-based approaches. Finally, we present Route Energy Transformer (RET) a decoder-only Transformer model sized according to Chinchilla scaling laws. RET yields a +217 Basis Points (bps) improvement in Mean Absolute Percentage Error (MAPE) relative to the Feed Forward NN and a +105 bps improvement relative to the RNN.
Off-Policy Evaluation from Logged Human Feedback
Jun 14, 2024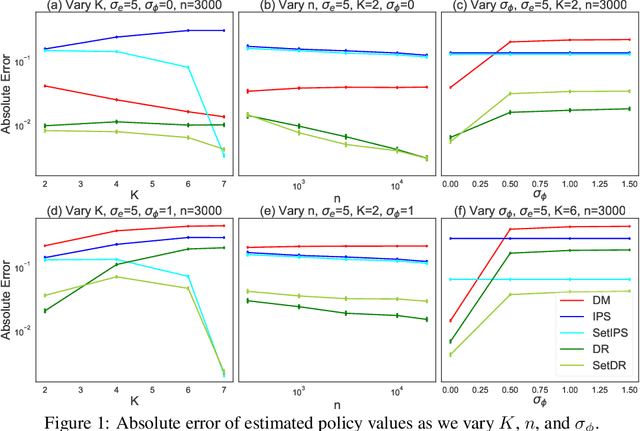
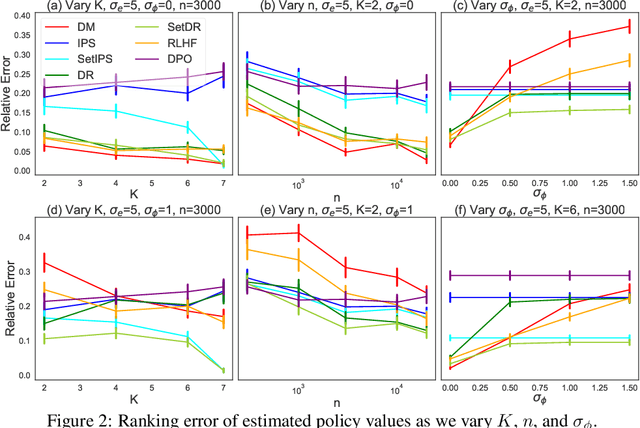
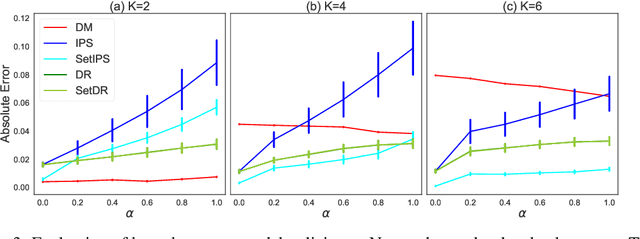

Learning from human feedback has been central to recent advances in artificial intelligence and machine learning. Since the collection of human feedback is costly, a natural question to ask is if the new feedback always needs to collected. Or could we evaluate a new model with the human feedback on responses of another model? This motivates us to study off-policy evaluation from logged human feedback. We formalize the problem, propose both model-based and model-free estimators for policy values, and show how to optimize them. We analyze unbiasedness of our estimators and evaluate them empirically. Our estimators can predict the absolute values of evaluated policies, rank them, and be optimized.
Pessimistic Off-Policy Multi-Objective Optimization
Oct 28, 2023



Multi-objective optimization is a type of decision making problems where multiple conflicting objectives are optimized. We study offline optimization of multi-objective policies from data collected by an existing policy. We propose a pessimistic estimator for the multi-objective policy values that can be easily plugged into existing formulas for hypervolume computation and optimized. The estimator is based on inverse propensity scores (IPS), and improves upon a naive IPS estimator in both theory and experiments. Our analysis is general, and applies beyond our IPS estimators and methods for optimizing them. The pessimistic estimator can be optimized by policy gradients and performs well in all of our experiments.
Linear Bandits with Feature Feedback
Mar 12, 2019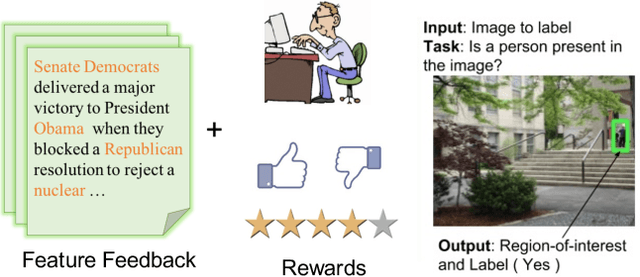
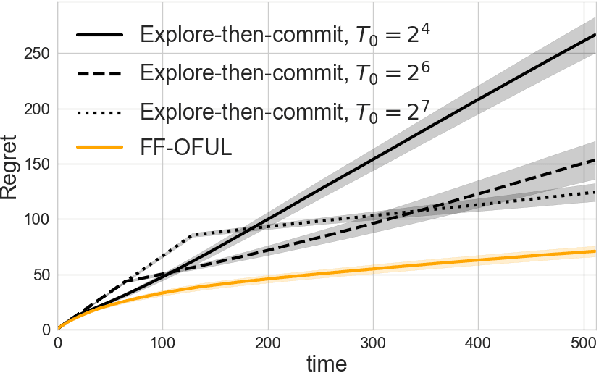

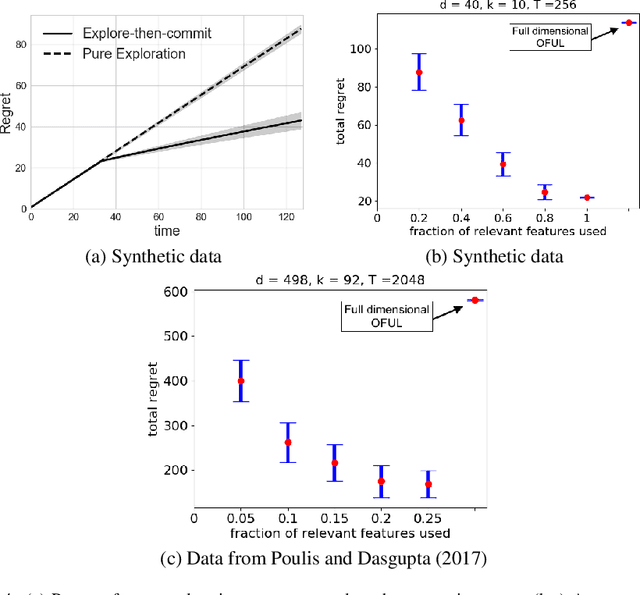
This paper explores a new form of the linear bandit problem in which the algorithm receives the usual stochastic rewards as well as stochastic feedback about which features are relevant to the rewards, the latter feedback being the novel aspect. The focus of this paper is the development of new theory and algorithms for linear bandits with feature feedback. We show that linear bandits with feature feedback can achieve regret over time horizon $T$ that scales like $k\sqrt{T}$, without prior knowledge of which features are relevant nor the number $k$ of relevant features. In comparison, the regret of traditional linear bandits is $d\sqrt{T}$, where $d$ is the total number of (relevant and irrelevant) features, so the improvement can be dramatic if $k\ll d$. The computational complexity of the new algorithm is proportional to $k$ rather than $d$, making it much more suitable for real-world applications compared to traditional linear bandits. We demonstrate the performance of the new algorithm with synthetic and real human-labeled data.
Scalable Generalized Linear Bandits: Online Computation and Hashing
Oct 21, 2017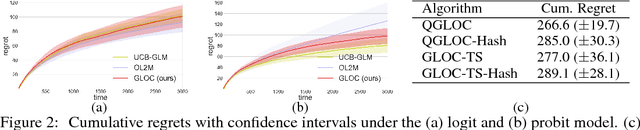
Generalized Linear Bandits (GLBs), a natural extension of the stochastic linear bandits, has been popular and successful in recent years. However, existing GLBs scale poorly with the number of rounds and the number of arms, limiting their utility in practice. This paper proposes new, scalable solutions to the GLB problem in two respects. First, unlike existing GLBs, whose per-time-step space and time complexity grow at least linearly with time $t$, we propose a new algorithm that performs online computations to enjoy a constant space and time complexity. At its heart is a novel Generalized Linear extension of the Online-to-confidence-set Conversion (GLOC method) that takes \emph{any} online learning algorithm and turns it into a GLB algorithm. As a special case, we apply GLOC to the online Newton step algorithm, which results in a low-regret GLB algorithm with much lower time and memory complexity than prior work. Second, for the case where the number $N$ of arms is very large, we propose new algorithms in which each next arm is selected via an inner product search. Such methods can be implemented via hashing algorithms (i.e., "hash-amenable") and result in a time complexity sublinear in $N$. While a Thompson sampling extension of GLOC is hash-amenable, its regret bound for $d$-dimensional arm sets scales with $d^{3/2}$, whereas GLOC's regret bound scales with $d$. Towards closing this gap, we propose a new hash-amenable algorithm whose regret bound scales with $d^{5/4}$. Finally, we propose a fast approximate hash-key computation (inner product) with a better accuracy than the state-of-the-art, which can be of independent interest. We conclude the paper with preliminary experimental results confirming the merits of our methods.
Active Algorithms For Preference Learning Problems with Multiple Populations
Jun 22, 2016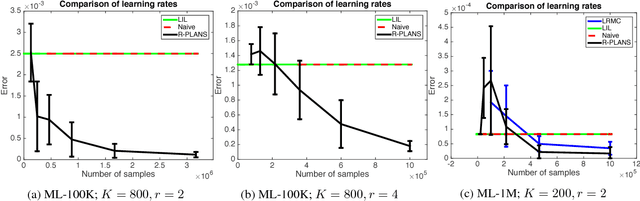
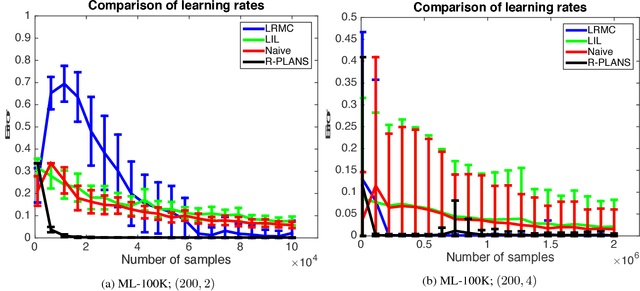
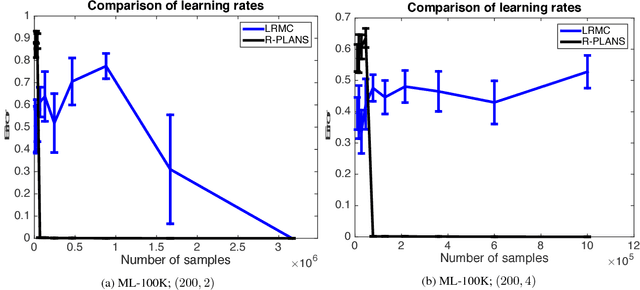
In this paper we model the problem of learning preferences of a population as an active learning problem. We propose an algorithm can adaptively choose pairs of items to show to users coming from a heterogeneous population, and use the obtained reward to decide which pair of items to show next. We provide computationally efficient algorithms with provable sample complexity guarantees for this problem in both the noiseless and noisy cases. In the process of establishing sample complexity guarantees for our algorithms, we establish new results using a Nystr{\"o}m-like method which can be of independent interest. We supplement our theoretical results with experimental comparisons.
Robust Spatio-Temporal Signal Recovery from Noisy Counts in Social Media
Apr 10, 2012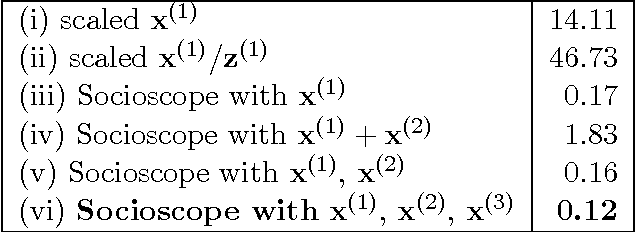
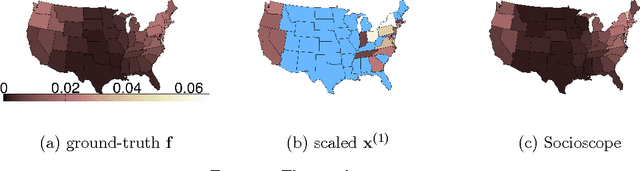
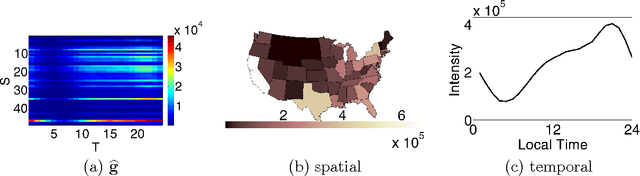
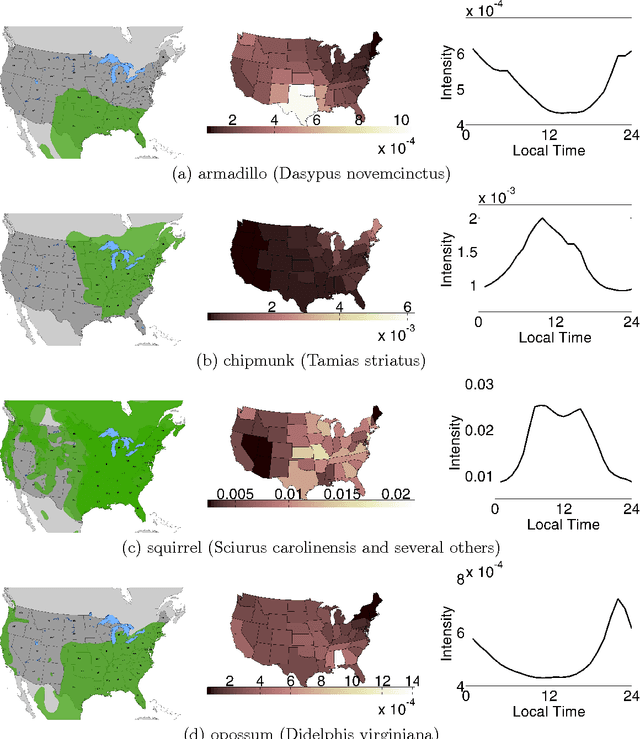
Many real-world phenomena can be represented by a spatio-temporal signal: where, when, and how much. Social media is a tantalizing data source for those who wish to monitor such signals. Unlike most prior work, we assume that the target phenomenon is known and we are given a method to count its occurrences in social media. However, counting is plagued by sample bias, incomplete data, and, paradoxically, data scarcity -- issues inadequately addressed by prior work. We formulate signal recovery as a Poisson point process estimation problem. We explicitly incorporate human population bias, time delays and spatial distortions, and spatio-temporal regularization into the model to address the noisy count issues. We present an efficient optimization algorithm and discuss its theoretical properties. We show that our model is more accurate than commonly-used baselines. Finally, we present a case study on wildlife roadkill monitoring, where our model produces qualitatively convincing results.