 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvantageFlow: Advantage-Weighted Least Squares for RL in Flow Models
May 25, 2026We introduce AdvantageFlow, a forward-process reinforcement learning algorithm for rectified flow models. Unlike Flow-GRPO, which optimizes the reverse process, we optimize an advantage-weighted forward-process prediction loss. This optimization problem is unstable when advantages are negative and the loss becomes non-convex. We stabilize it by rollout policy regularization, which reduces variance and arises from fitting a local reward-improving target distribution. We evaluate AdvantageFlow on image generation tasks with Stable Diffusion 3.5 Medium. It outperforms both Flow-GRPO and a state-of-the-art forward-process RL baseline based on negative-aware fine-tuning.
MOCHA: Multi-Objective Chebyshev Annealing for Agent Skill Optimization
May 19, 2026LLM agents organize behavior through skills - structured natural-language specifications governing how an agent reasons, retrieves, and responds. Unlike monolithic prompts, skills are multi-field artifacts subject to hard platform constraints: description fields are truncated for routing, instruction bodies are compacted via progressive disclosure, and co-resident skills compete for limited context windows. These constraints make skill optimization inherently multi-objective: a skill must simultaneously maximize task performance and satisfy platform limits. Yet existing prompt optimizers either ignore these trade-offs or collapse them into a weighted sum, missing Pareto-optimal variants in non-convex objective regions. We introduce MOCHA (Multi-Objective Chebyshev Annealing), which replaces single-objective selection with Chebyshev scalarization - covering the full Pareto front, including non-convex regions - combined with exponential annealing that transitions from exploration to exploitation. In our experiments across six diverse agent skills - where all methods share the same multi-objective mutation operator and baselines receive identical per-objective textual feedback - existing optimizers fail to improve the seed skill on 4 of 6 tasks: 1000 rollouts yield zero progress. MOCHA breaks through on every task, achieving 7.5% relative improvement in mean correctness over the strongest baseline (up to 14.9% on FEVER and 10.4% on TheoremQA) while discovering twice as many more Pareto-optimal skill variants.
Sparse Personalized Text Generation with Multi-Trajectory Reasoning
Apr 27, 2026As Large Language Models (LLMs) advance, personalization has become a key mechanism for tailoring outputs to individual user needs. However, most existing methods rely heavily on dense interaction histories, making them ineffective in cold-start scenarios where such data is sparse or unavailable. While external signals (e.g., content of similar users) can offer a potential remedy, leveraging them effectively remains challenging: raw context is often noisy, and existing methods struggle to reason over heterogeneous data sources. To address these issues, we introduce PAT (Personalization with Aligned Trajectories), a reasoning framework for cold-start LLM personalization. PAT first retrieves information along two complementary trajectories: writing-style cues from stylistically similar users and topic-specific context from preference-aligned users. It then employs a reinforcement learning-based, iterative dual-reasoning mechanism that enables the LLM to jointly refine and integrate these signals. Experimental results across real-world personalization benchmarks show that PAT consistently improves generation quality and alignment under sparse-data conditions, establishing a strong solution to the cold-start personalization problem.
A Survey on LLM-based Conversational User Simulation
Apr 27, 2026User simulation has long played a vital role in computer science due to its potential to support a wide range of applications. Language, as the primary medium of human communication, forms the foundation of social interaction and behavior. Consequently, simulating conversational behavior has become a key area of study. Recent advancements in large language models (LLMs) have significantly catalyzed progress in this domain by enabling high-fidelity generation of synthetic user conversation. In this paper, we survey recent advancements in LLM-based conversational user simulation. We introduce a novel taxonomy covering user granularity and simulation objectives. Additionally, we systematically analyze core techniques and evaluation methodologies. We aim to keep the research community informed of the latest advancements in conversational user simulation and to further facilitate future research by identifying open challenges and organizing existing work under a unified framework.
Stepwise Credit Assignment for GRPO on Flow-Matching Models
Mar 30, 2026Flow-GRPO successfully applies reinforcement learning to flow models, but uses uniform credit assignment across all steps. This ignores the temporal structure of diffusion generation: early steps determine composition and content (low-frequency structure), while late steps resolve details and textures (high-frequency details). Moreover, assigning uniform credit based solely on the final image can inadvertently reward suboptimal intermediate steps, especially when errors are corrected later in the diffusion trajectory. We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement. By leveraging Tweedie's formula to obtain intermediate reward estimates and introducing gain-based advantages, our method achieves superior sample efficiency and faster convergence. We also introduce a DDIM-inspired SDE that improves reward quality while preserving stochasticity for policy gradients.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Human-Aligned MLLM Judges for Fine-Grained Image Editing Evaluation: A Benchmark, Framework, and Analysis
Feb 13, 2026Evaluating image editing models remains challenging due to the coarse granularity and limited interpretability of traditional metrics, which often fail to capture aspects important to human perception and intent. Such metrics frequently reward visually plausible outputs while overlooking controllability, edit localization, and faithfulness to user instructions. In this work, we introduce a fine-grained Multimodal Large Language Model (MLLM)-as-a-Judge framework for image editing that decomposes common evaluation notions into twelve fine-grained interpretable factors spanning image preservation, edit quality, and instruction fidelity. Building on this formulation, we present a new human-validated benchmark that integrates human judgments, MLLM-based evaluations, model outputs, and traditional metrics across diverse image editing tasks. Through extensive human studies, we show that the proposed MLLM judges align closely with human evaluations at a fine granularity, supporting their use as reliable and scalable evaluators. We further demonstrate that traditional image editing metrics are often poor proxies for these factors, failing to distinguish over-edited or semantically imprecise outputs, whereas our judges provide more intuitive and informative assessments in both offline and online settings. Together, this work introduces a benchmark, a principled factorization, and empirical evidence positioning fine-grained MLLM judges as a practical foundation for studying, comparing, and improving image editing approaches.
Learning to Reason in LLMs by Expectation Maximization
Dec 23, 2025

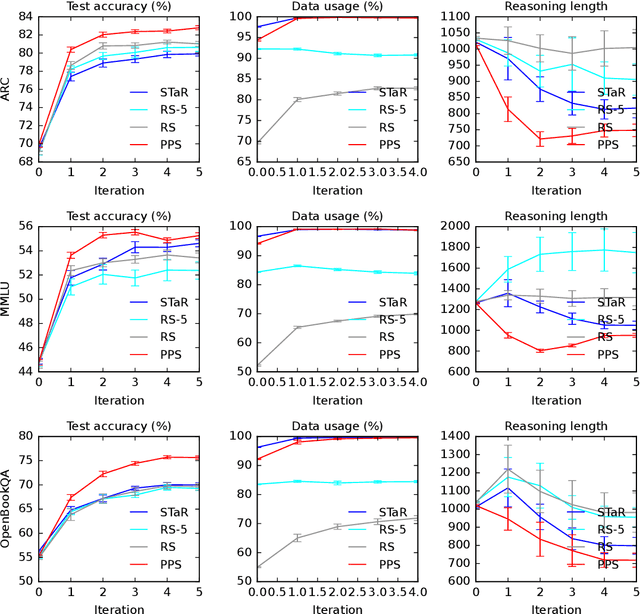
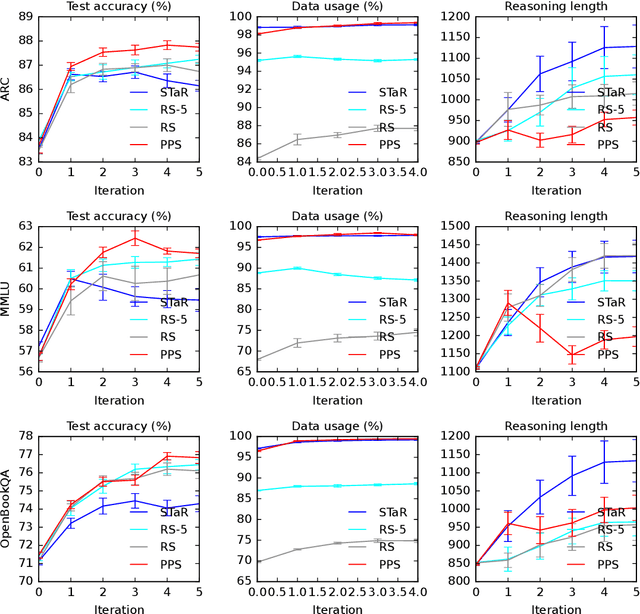
Large language models (LLMs) solve reasoning problems by first generating a rationale and then answering. We formalize reasoning as a latent variable model and derive an expectation-maximization (EM) objective for learning to reason. This view connects EM and modern reward-based optimization, and shows that the main challenge lies in designing a sampling distribution that generates rationales that justify correct answers. We instantiate and compare several sampling schemes: rejection sampling with a budget, self-taught reasoner (STaR), and prompt posterior sampling (PPS), which only keeps the rationalization stage of STaR. Our experiments on the ARC, MMLU, and OpenBookQA datasets with the Llama and Qwen models show that the sampling scheme can significantly affect the accuracy of learned reasoning models. Despite its simplicity, we observe that PPS outperforms the other sampling schemes.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Learning to Clarify by Reinforcement Learning Through Reward-Weighted Fine-Tuning
Jun 08, 2025


Question answering (QA) agents automatically answer questions posed in natural language. In this work, we learn to ask clarifying questions in QA agents. The key idea in our method is to simulate conversations that contain clarifying questions and learn from them using reinforcement learning (RL). To make RL practical, we propose and analyze offline RL objectives that can be viewed as reward-weighted supervised fine-tuning (SFT) and easily optimized in large language models. Our work stands in a stark contrast to recently proposed methods, based on SFT and direct preference optimization, which have additional hyper-parameters and do not directly optimize rewards. We compare to these methods empirically and report gains in both optimized rewards and language quality.