 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Design for Human Feedback
Paper and Code
Apr 22, 2024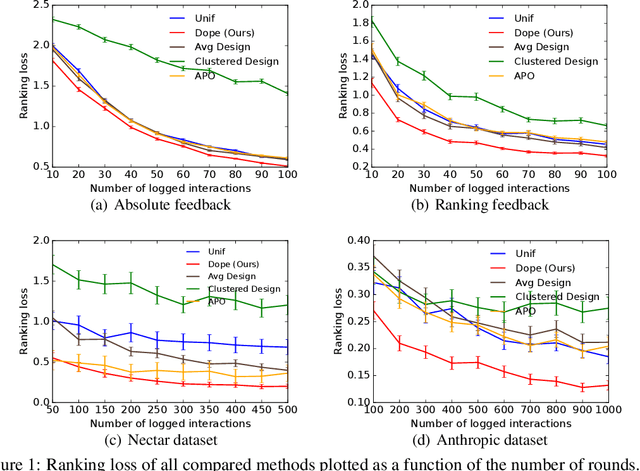


Learning of preference models from human feedback has been central to recent advances in artificial intelligence. Motivated by this progress, and the cost of obtaining high-quality human annotations, we study the problem of data collection for learning preference models. The key idea in our work is to generalize optimal designs, a tool for computing efficient data logging policies, to ranked lists. To show the generality of our ideas, we study both absolute and relative feedback on items in the list. We design efficient algorithms for both settings and analyze them. We prove that our preference model estimators improve with more data and so does the ranking error under the estimators. Finally, we experiment with several synthetic and real-world datasets to show the statistical efficiency of our algorithms.