 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Audio Generation from dynamic MRI via a Knowledge Enhanced Conditional Variational Autoencoder
Mar 09, 2025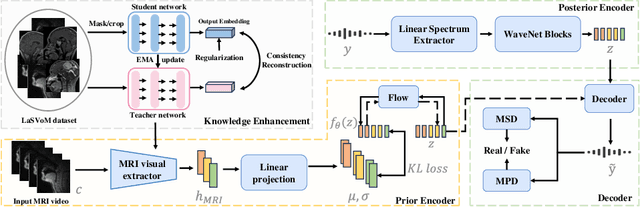
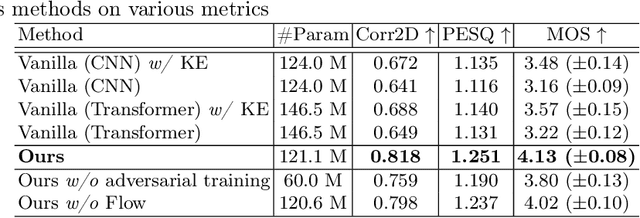
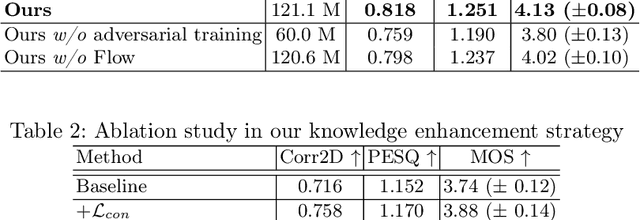
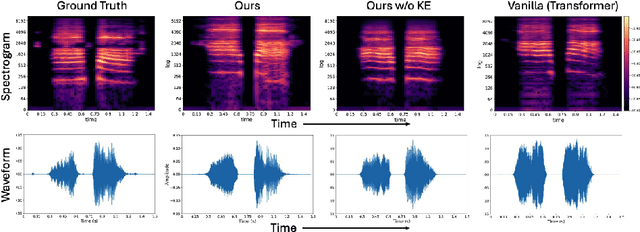
Dynamic Magnetic Resonance Imaging (MRI) of the vocal tract has become an increasingly adopted imaging modality for speech motor studies. Beyond image signals, systematic data loss, noise pollution, and audio file corruption can occur due to the unpredictability of the MRI acquisition environment. In such cases, generating audio from images is critical for data recovery in both clinical and research applications. However, this remains challenging due to hardware constraints, acoustic interference, and data corruption. Existing solutions, such as denoising and multi-stage synthesis methods, face limitations in audio fidelity and generalizability. To address these challenges, we propose a Knowledge Enhanced Conditional Variational Autoencoder (KE-CVAE), a novel two-step "knowledge enhancement + variational inference" framework for generating speech audio signals from cine dynamic MRI sequences. This approach introduces two key innovations: (1) integration of unlabeled MRI data for knowledge enhancement, and (2) a variational inference architecture to improve generative modeling capacity. To the best of our knowledge, this is one of the first attempts at synthesizing speech audio directly from dynamic MRI video sequences. The proposed method was trained and evaluated on an open-source dynamic vocal tract MRI dataset recorded during speech. Experimental results demonstrate its effectiveness in generating natural speech waveforms while addressing MRI-specific acoustic challenges, outperforming conventional deep learning-based synthesis approaches.
Unlocking adaptive digital pathology through dynamic feature learning
Dec 29, 2024



Foundation models have revolutionized the paradigm of digital pathology, as they leverage general-purpose features to emulate real-world pathological practices, enabling the quantitative analysis of critical histological patterns and the dissection of cancer-specific signals. However, these static general features constrain the flexibility and pathological relevance in the ever-evolving needs of clinical applications, hindering the broad use of the current models. Here we introduce PathFiT, a dynamic feature learning method that can be effortlessly plugged into various pathology foundation models to unlock their adaptability. Meanwhile, PathFiT performs seamless implementation across diverse pathology applications regardless of downstream specificity. To validate PathFiT, we construct a digital pathology benchmark with over 20 terabytes of Internet and real-world data comprising 28 H\&E-stained tasks and 7 specialized imaging tasks including Masson's Trichrome staining and immunofluorescence images. By applying PathFiT to the representative pathology foundation models, we demonstrate state-of-the-art performance on 34 out of 35 tasks, with significant improvements on 23 tasks and outperforming by 10.20% on specialized imaging tasks. The superior performance and versatility of PathFiT open up new avenues in computational pathology.
Aligning Vision Models with Human Aesthetics in Retrieval: Benchmarks and Algorithms
Jun 13, 2024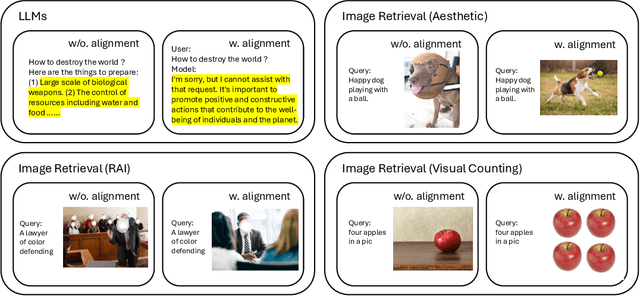



Modern vision models are trained on very large noisy datasets. While these models acquire strong capabilities, they may not follow the user's intent to output the desired results in certain aspects, e.g., visual aesthetic, preferred style, and responsibility. In this paper, we target the realm of visual aesthetics and aim to align vision models with human aesthetic standards in a retrieval system. Advanced retrieval systems usually adopt a cascade of aesthetic models as re-rankers or filters, which are limited to low-level features like saturation and perform poorly when stylistic, cultural or knowledge contexts are involved. We find that utilizing the reasoning ability of large language models (LLMs) to rephrase the search query and extend the aesthetic expectations can make up for this shortcoming. Based on the above findings, we propose a preference-based reinforcement learning method that fine-tunes the vision models to distill the knowledge from both LLMs reasoning and the aesthetic models to better align the vision models with human aesthetics. Meanwhile, with rare benchmarks designed for evaluating retrieval systems, we leverage large multi-modality model (LMM) to evaluate the aesthetic performance with their strong abilities. As aesthetic assessment is one of the most subjective tasks, to validate the robustness of LMM, we further propose a novel dataset named HPIR to benchmark the alignment with human aesthetics. Experiments demonstrate that our method significantly enhances the aesthetic behaviors of the vision models, under several metrics. We believe the proposed algorithm can be a general practice for aligning vision models with human values.
Optimal Design for Human Feedback
Apr 22, 2024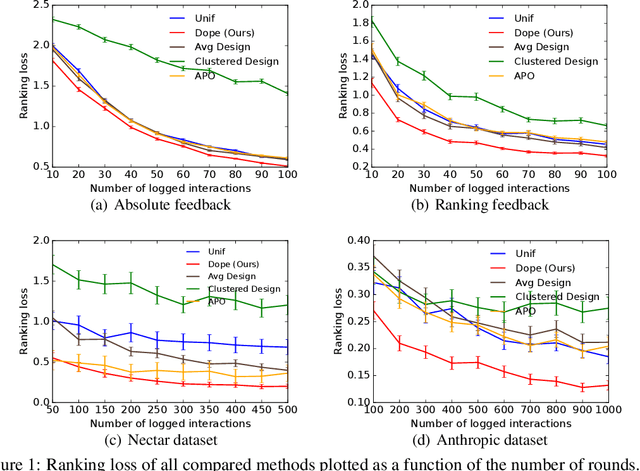


Learning of preference models from human feedback has been central to recent advances in artificial intelligence. Motivated by this progress, and the cost of obtaining high-quality human annotations, we study the problem of data collection for learning preference models. The key idea in our work is to generalize optimal designs, a tool for computing efficient data logging policies, to ranked lists. To show the generality of our ideas, we study both absolute and relative feedback on items in the list. We design efficient algorithms for both settings and analyze them. We prove that our preference model estimators improve with more data and so does the ranking error under the estimators. Finally, we experiment with several synthetic and real-world datasets to show the statistical efficiency of our algorithms.
Experimental Design for Active Transductive Inference in Large Language Models
Apr 12, 2024



Transduction, the ability to include query-specific examples in the prompt at inference time, is one of the emergent abilities of large language models (LLMs). In this work, we propose a framework for adaptive prompt design called active transductive inference (ATI). We design the LLM prompt by adaptively choosing few-shot examples for a given inference query. The examples are initially unlabeled and we query the user to label the most informative ones, which maximally reduces the uncertainty in the LLM prediction. We propose two algorithms, GO and SAL, which differ in how the few-shot examples are chosen. We analyze these algorithms in linear models: first GO and then use its equivalence with SAL. We experiment with many different tasks and show that GO and SAL outperform other methods for choosing few-shot examples in the LLM prompt at inference time.
Logic-Scaffolding: Personalized Aspect-Instructed Recommendation Explanation Generation using LLMs
Dec 22, 2023



The unique capabilities of Large Language Models (LLMs), such as the natural language text generation ability, position them as strong candidates for providing explanation for recommendations. However, despite the size of the LLM, most existing models struggle to produce zero-shot explanations reliably. To address this issue, we propose a framework called Logic-Scaffolding, that combines the ideas of aspect-based explanation and chain-of-thought prompting to generate explanations through intermediate reasoning steps. In this paper, we share our experience in building the framework and present an interactive demonstration for exploring our results.
Fixed-Budget Best-Arm Identification with Heterogeneous Reward Variances
Jun 13, 2023We study the problem of best-arm identification (BAI) in the fixed-budget setting with heterogeneous reward variances. We propose two variance-adaptive BAI algorithms for this setting: SHVar for known reward variances and SHAdaVar for unknown reward variances. Our algorithms rely on non-uniform budget allocations among the arms where the arms with higher reward variances are pulled more often than those with lower variances. The main algorithmic novelty is in the design of SHAdaVar, which allocates budget greedily based on overestimating the unknown reward variances. We bound probabilities of misidentifying the best arms in both SHVar and SHAdaVar. Our analyses rely on novel lower bounds on the number of pulls of an arm that do not require closed-form solutions to the budget allocation problem. Since one of our budget allocation problems is analogous to the optimal experiment design with unknown variances, we believe that our results are of a broad interest. Our experiments validate our theory, and show that SHVar and SHAdaVar outperform algorithms from prior works with analytical guarantees.
Context Uncertainty in Contextual Bandits with Applications to Recommender Systems
Feb 16, 2022



Recurrent neural networks have proven effective in modeling sequential user feedbacks for recommender systems. However, they usually focus solely on item relevance and fail to effectively explore diverse items for users, therefore harming the system performance in the long run. To address this problem, we propose a new type of recurrent neural networks, dubbed recurrent exploration networks (REN), to jointly perform representation learning and effective exploration in the latent space. REN tries to balance relevance and exploration while taking into account the uncertainty in the representations. Our theoretical analysis shows that REN can preserve the rate-optimal sublinear regret even when there exists uncertainty in the learned representations. Our empirical study demonstrates that REN can achieve satisfactory long-term rewards on both synthetic and real-world recommendation datasets, outperforming state-of-the-art models.
Zero-Shot Recommender Systems
May 18, 2021



Performance of recommender systems (RS) relies heavily on the amount of training data available. This poses a chicken-and-egg problem for early-stage products, whose amount of data, in turn, relies on the performance of their RS. On the other hand, zero-shot learning promises some degree of generalization from an old dataset to an entirely new dataset. In this paper, we explore the possibility of zero-shot learning in RS. We develop an algorithm, dubbed ZEro-Shot Recommenders (ZESRec), that is trained on an old dataset and generalize to a new one where there are neither overlapping users nor overlapping items, a setting that contrasts typical cross-domain RS that has either overlapping users or items. Different from categorical item indices, i.e., item ID, in previous methods, ZESRec uses items' natural-language descriptions (or description embeddings) as their continuous indices, and therefore naturally generalize to any unseen items. In terms of users, ZESRec builds upon recent advances on sequential RS to represent users using their interactions with items, thereby generalizing to unseen users as well. We study two pairs of real-world RS datasets and demonstrate that ZESRec can successfully enable recommendations in such a zero-shot setting, opening up new opportunities for resolving the chicken-and-egg problem for data-scarce startups or early-stage products.
Optimal Off-Policy Evaluation for Reinforcement Learning with Marginalized Importance Sampling
Jun 08, 2019


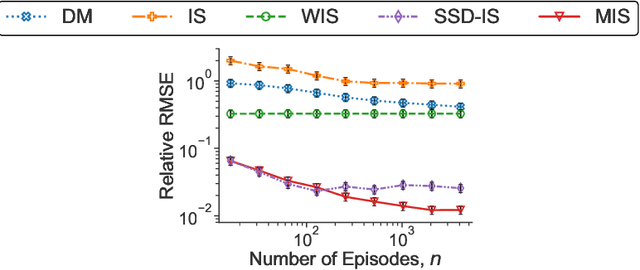
Motivated by the many real-world applications of reinforcement learning (RL) that require safe-policy iterations, we consider the problem of off-policy evaluation (OPE) --- the problem of evaluating a new policy using the historical data obtained by different behavior policies --- under the model of nonstationary episodic Markov Decision Processes with a long horizon and large action space. Existing importance sampling (IS) methods often suffer from large variance that depends exponentially on the RL horizon $H$. To solve this problem, we consider a marginalized importance sampling (MIS) estimator that recursively estimates the state marginal distribution for the target policy at every step. MIS achieves a mean-squared error of $O(H^2R_{\max}^2\sum_{t=1}^H\mathbb E_\mu[(w_{\pi,\mu}(s_t,a_t))^2]/n)$ for large $n$, where $w_{\pi,\mu}(s_t,a_t)$ is the ratio of the marginal distribution of $t$th step under $\pi$ and $\mu$, $H$ is the horizon, $R_{\max}$ is the maximal rewards, and $n$ is the sample size. The result nearly matches the Cramer-Rao lower bounds for DAG MDP in \citet{jiang2016doubly} for most non-trivial regimes. To the best of our knowledge, this is the first OPE estimator with provably optimal dependence in $H$ and the second moments of the importance weight. Besides theoretical optimality, we empirically demonstrate the superiority of our method in time-varying, partially observable, and long-horizon RL environments.