 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Optimization via Contrastive Divergence: Your Reward Model is Secretly an NLL Estimator
Feb 06, 2025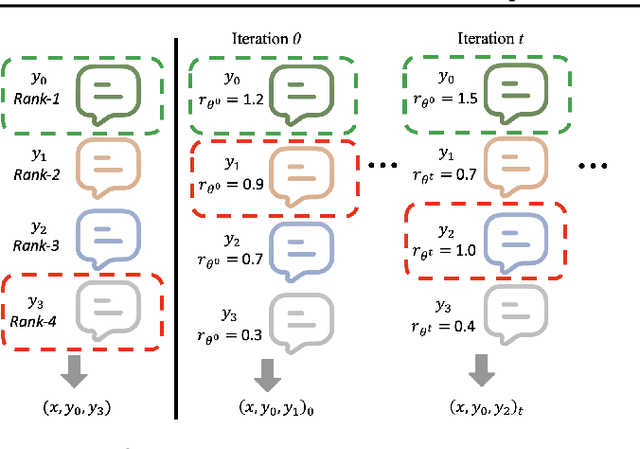
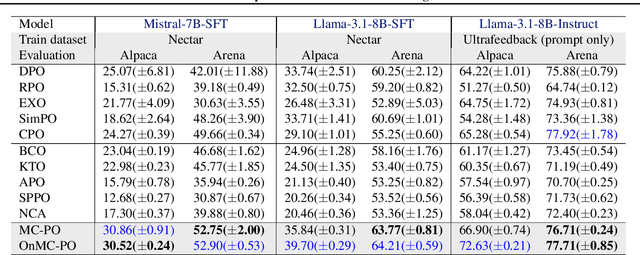
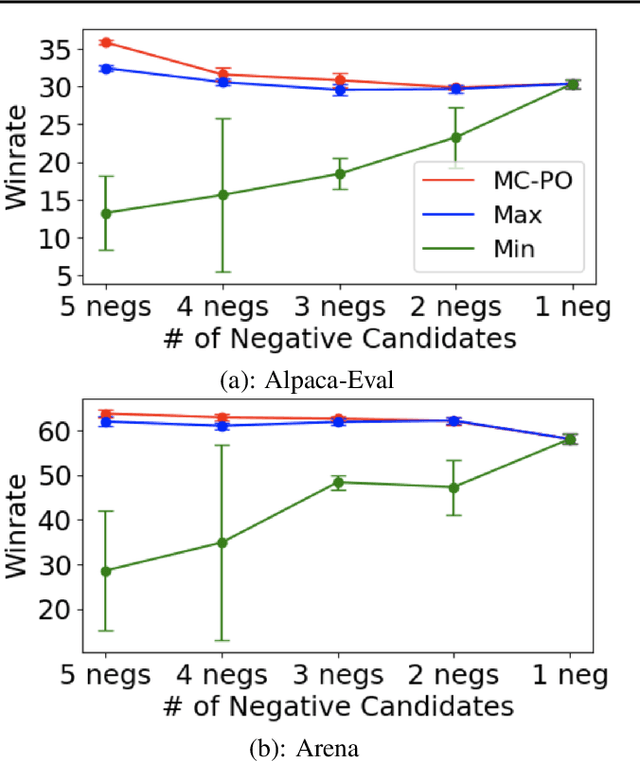
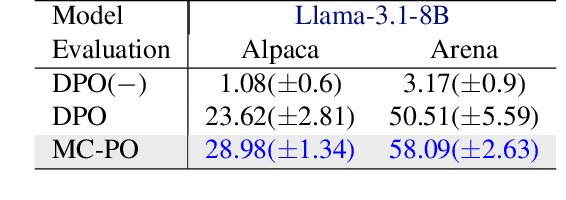
Existing studies on preference optimization (PO) have centered on constructing pairwise preference data following simple heuristics, such as maximizing the margin between preferred and dispreferred completions based on human (or AI) ranked scores. However, none of these heuristics has a full theoretical justification. In this work, we develop a novel PO framework that provides theoretical guidance to effectively sample dispreferred completions. To achieve this, we formulate PO as minimizing the negative log-likelihood (NLL) of a probability model and propose to estimate its normalization constant via a sampling strategy. As we will demonstrate, these estimative samples can act as dispreferred completions in PO. We then select contrastive divergence (CD) as the sampling strategy, and propose a novel MC-PO algorithm that applies the Monte Carlo (MC) kernel from CD to sample hard negatives w.r.t. the parameterized reward model. Finally, we propose the OnMC-PO algorithm, an extension of MC-PO to the online setting. On popular alignment benchmarks, MC-PO outperforms existing SOTA baselines, and OnMC-PO leads to further improvement.
Towards Improved Preference Optimization Pipeline: from Data Generation to Budget-Controlled Regularization
Nov 07, 2024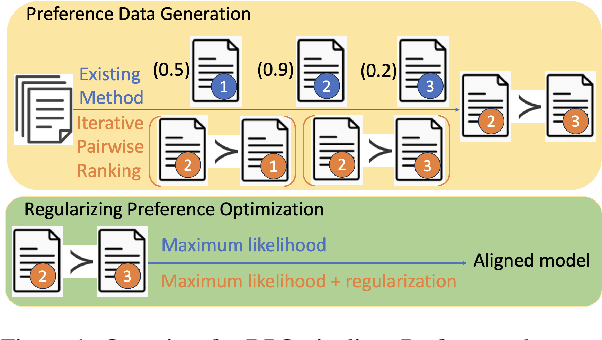

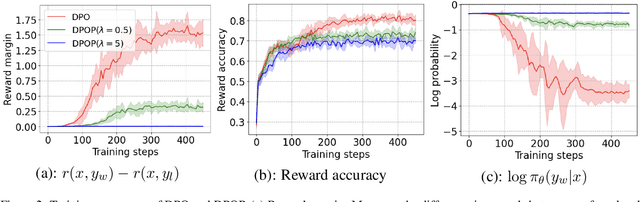
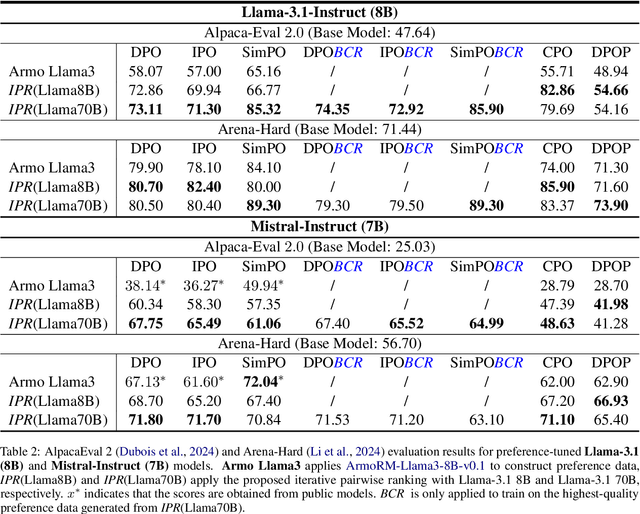
Direct Preference Optimization (DPO) and its variants have become the de facto standards for aligning large language models (LLMs) with human preferences or specific goals. However, DPO requires high-quality preference data and suffers from unstable preference optimization. In this work, we aim to improve the preference optimization pipeline by taking a closer look at preference data generation and training regularization techniques. For preference data generation, we demonstrate that existing scoring-based reward models produce unsatisfactory preference data and perform poorly on out-of-distribution tasks. This significantly impacts the LLM alignment performance when using these data for preference tuning. To ensure high-quality preference data generation, we propose an iterative pairwise ranking mechanism that derives preference ranking of completions using pairwise comparison signals. For training regularization, we observe that preference optimization tends to achieve better convergence when the LLM predicted likelihood of preferred samples gets slightly reduced. However, the widely used supervised next-word prediction regularization strictly prevents any likelihood reduction of preferred samples. This observation motivates our design of a budget-controlled regularization formulation. Empirically we show that combining the two designs leads to aligned models that surpass existing SOTA across two popular benchmarks.
PID Control-Based Self-Healing to Improve the Robustness of Large Language Models
Mar 31, 2024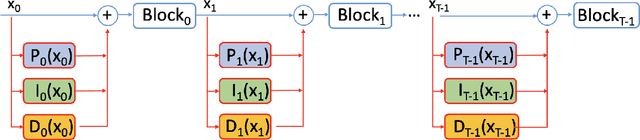
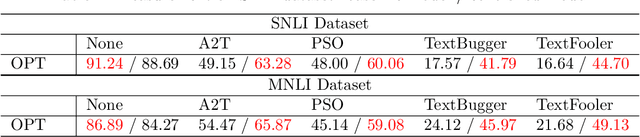
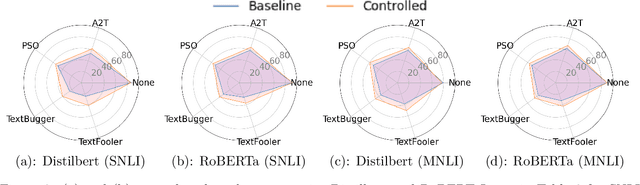

Despite the effectiveness of deep neural networks in numerous natural language processing applications, recent findings have exposed the vulnerability of these language models when minor perturbations are introduced. While appearing semantically indistinguishable to humans, these perturbations can significantly reduce the performance of well-trained language models, raising concerns about the reliability of deploying them in safe-critical situations. In this work, we construct a computationally efficient self-healing process to correct undesired model behavior during online inference when perturbations are applied to input data. This is formulated as a trajectory optimization problem in which the internal states of the neural network layers are automatically corrected using a PID (Proportional-Integral-Derivative) control mechanism. The P controller targets immediate state adjustments, while the I and D controllers consider past states and future dynamical trends, respectively. We leverage the geometrical properties of the training data to design effective linear PID controllers. This approach reduces the computational cost to that of using just the P controller, instead of the full PID control. Further, we introduce an analytical method for approximating the optimal control solutions, enhancing the real-time inference capabilities of this controlled system. Moreover, we conduct a theoretical error analysis of the analytic solution in a simplified setting. The proposed PID control-based self-healing is a low cost framework that improves the robustness of pre-trained large language models, whether standard or robustly trained, against a wide range of perturbations. A detailed implementation can be found in:https://github.com/zhuotongchen/PID-Control-Based-Self-Healing-to-Improve-the-Robustness-of-Large-Language-Models.
Logic-Scaffolding: Personalized Aspect-Instructed Recommendation Explanation Generation using LLMs
Dec 22, 2023



The unique capabilities of Large Language Models (LLMs), such as the natural language text generation ability, position them as strong candidates for providing explanation for recommendations. However, despite the size of the LLM, most existing models struggle to produce zero-shot explanations reliably. To address this issue, we propose a framework called Logic-Scaffolding, that combines the ideas of aspect-based explanation and chain-of-thought prompting to generate explanations through intermediate reasoning steps. In this paper, we share our experience in building the framework and present an interactive demonstration for exploring our results.
Asymptotically Fair Participation in Machine Learning Models: an Optimal Control Perspective
Nov 16, 2023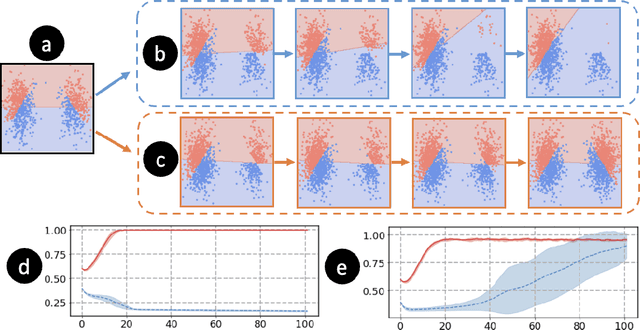

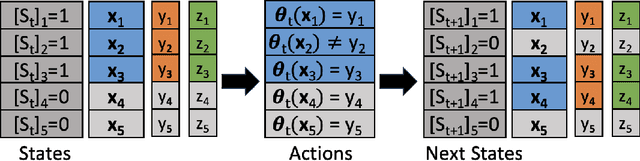

The performance of state-of-the-art machine learning models often deteriorates when testing on demographics that are under-represented in the training dataset. This problem has predominately been studied in a supervised learning setting where the data distribution is static. However, real-world applications often involve distribution shifts caused by the deployed models. For instance, the performance disparity against monitory users can lead to a high customer churn rate, thus the available data provided by active users are skewed due to the lack of minority users. This feedback effect further exacerbates the disparity among different demographic groups in future steps. To address this issue, we propose asymptotically fair participation as a condition to maintain long-term model performance over all demographic groups. In this work, we aim to address the problem of achieving asymptotically fair participation via optimal control formulation. Moreover, we design a surrogate retention system based on existing literature on evolutionary population dynamics to approximate the dynamics of distribution shifts on active user counts, from which the objective of achieving asymptotically fair participation is formulated as an optimal control problem, and the control variables are considered as the model parameters. We apply an efficient implementation of Pontryagin's maximum principle to estimate the optimal control solution. To evaluate the effectiveness of the proposed method, we design a generic simulation environment that simulates the population dynamics of the feedback effect between user retention and model performance. When we deploy the resulting models to the simulation environment, the optimal control solution accounts for long-term planning and leads to superior performance compared with existing baseline methods.
Self-Healing Robust Neural Networks via Closed-Loop Control
Jun 26, 2022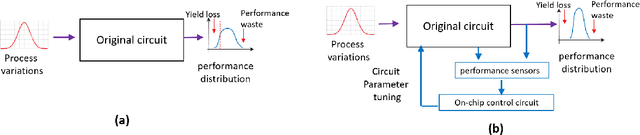

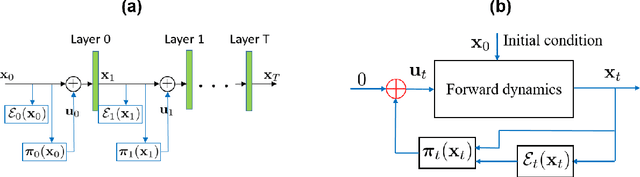
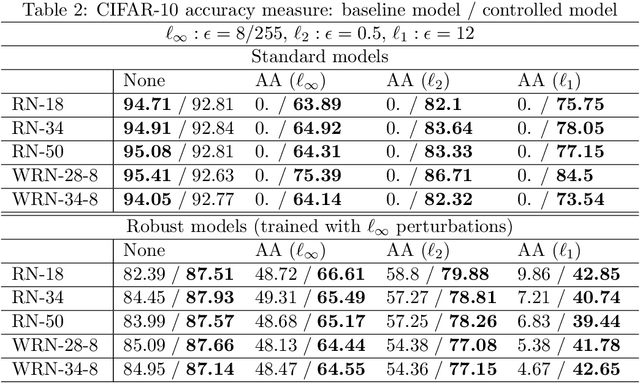
Despite the wide applications of neural networks, there have been increasing concerns about their vulnerability issue. While numerous attack and defense techniques have been developed, this work investigates the robustness issue from a new angle: can we design a self-healing neural network that can automatically detect and fix the vulnerability issue by itself? A typical self-healing mechanism is the immune system of a human body. This biology-inspired idea has been used in many engineering designs but is rarely investigated in deep learning. This paper considers the post-training self-healing of a neural network, and proposes a closed-loop control formulation to automatically detect and fix the errors caused by various attacks or perturbations. We provide a margin-based analysis to explain how this formulation can improve the robustness of a classifier. To speed up the inference of the proposed self-healing network, we solve the control problem via improving the Pontryagin Maximum Principle-based solver. Lastly, we present an error estimation of the proposed framework for neural networks with nonlinear activation functions. We validate the performance on several network architectures against various perturbations. Since the self-healing method does not need a-priori information about data perturbations/attacks, it can handle a broad class of unforeseen perturbations.
Towards Robust Neural Networks via Close-loop Control
Feb 03, 2021
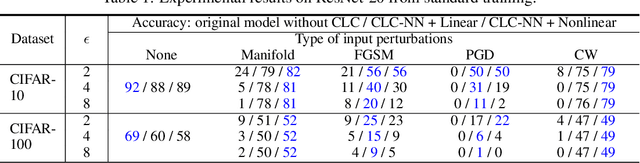
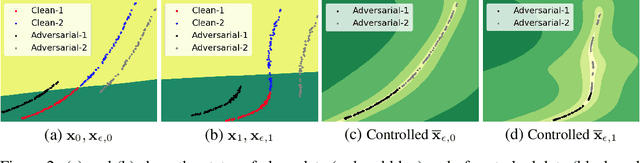
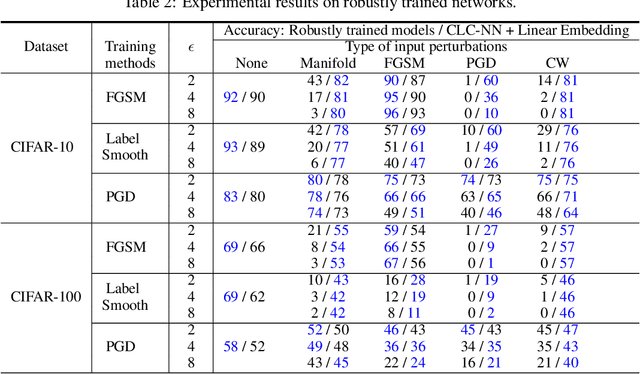
Despite their success in massive engineering applications, deep neural networks are vulnerable to various perturbations due to their black-box nature. Recent study has shown that a deep neural network can misclassify the data even if the input data is perturbed by an imperceptible amount. In this paper, we address the robustness issue of neural networks by a novel close-loop control method from the perspective of dynamic systems. Instead of modifying the parameters in a fixed neural network architecture, a close-loop control process is added to generate control signals adaptively for the perturbed or corrupted data. We connect the robustness of neural networks with optimal control using the geometrical information of underlying data to design the control objective. The detailed analysis shows how the embedding manifolds of state trajectory affect error estimation of the proposed method. Our approach can simultaneously maintain the performance on clean data and improve the robustness against many types of data perturbations. It can also further improve the performance of robustly trained neural networks against different perturbations. To the best of our knowledge, this is the first work that improves the robustness of neural networks with close-loop control.