 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Retrieving Information to Reasoning with AI: Exploring Different Interaction Modalities to Support Human-AI Coordination in Clinical Decision-Making
Jan 29, 2026LLMs are popular among clinicians for decision-support because of simple text-based interaction. However, their impact on clinicians' performance is ambiguous. Not knowing how clinicians use this new technology and how they compare it to traditional clinical decision-support systems (CDSS) restricts designing novel mechanisms that overcome existing tool limitations and enhance performance and experience. This qualitative study examines how clinicians (n=12) perceive different interaction modalities (text-based conversation with LLMs, interactive and static UI, and voice) for decision-support. In open-ended use of LLM-based tools, our participants took a tool-centric approach using them for information retrieval and confirmation with simple prompts instead of use as active deliberation partners that can handle complex questions. Critical engagement emerged with changes to the interaction setup. Engagement also differed with individual cognitive styles. Lastly, benefits and drawbacks of interaction with text, voice and traditional UIs for clinical decision-support show the lack of a one-size-fits-all interaction modality.
Logic-Scaffolding: Personalized Aspect-Instructed Recommendation Explanation Generation using LLMs
Dec 22, 2023



The unique capabilities of Large Language Models (LLMs), such as the natural language text generation ability, position them as strong candidates for providing explanation for recommendations. However, despite the size of the LLM, most existing models struggle to produce zero-shot explanations reliably. To address this issue, we propose a framework called Logic-Scaffolding, that combines the ideas of aspect-based explanation and chain-of-thought prompting to generate explanations through intermediate reasoning steps. In this paper, we share our experience in building the framework and present an interactive demonstration for exploring our results.
From Ranked Lists to Carousels: A Carousel Click Model
Sep 27, 2022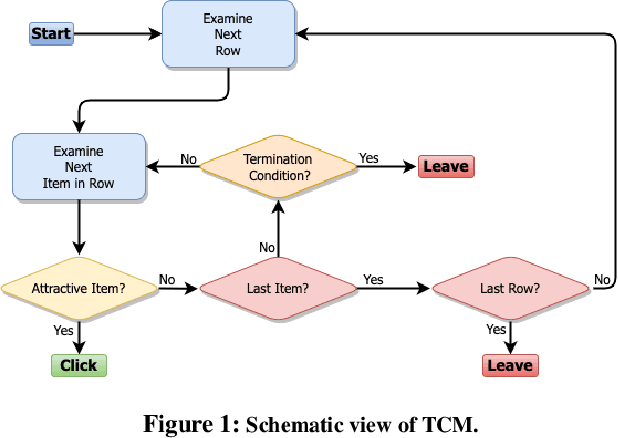


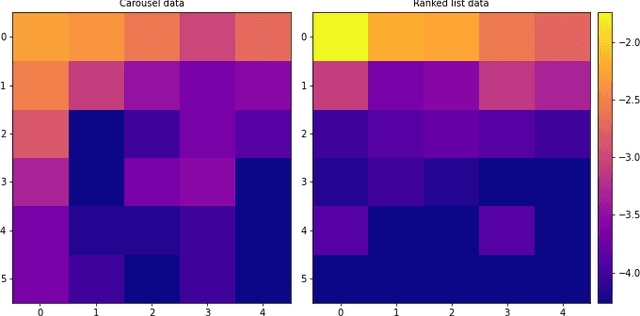
Carousel-based recommendation interfaces allow users to explore recommended items in a structured, efficient, and visually-appealing way. This made them a de-facto standard approach to recommending items to end users in many real-life recommenders. In this work, we try to explain the efficiency of carousel recommenders using a \emph{carousel click model}, a generative model of user interaction with carousel-based recommender interfaces. We study this model both analytically and empirically. Our analytical results show that the user can examine more items in the carousel click model than in a single ranked list, due to the structured way of browsing. These results are supported by a series of experiments, where we integrate the carousel click model with a recommender based on matrix factorization. We show that the combined recommender performs well on held-out test data, and leads to higher engagement with recommendations than a traditional single ranked list.