 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effectiveness of Using LLMs for Automated Assessment of Student Self Explanations in Programming Education
May 20, 2026Worked examples are step-by-step solutions to problems in a specific domain, offered to students to acquire domain-specific problem-solving skills. The effectiveness of worked examples could be enhanced by combining them with self-explanations, which ask students to explain rather than passively study each problem-solving step. The main challenge of this approach is assessing the correctness of the student's explanations. In the prevailing approach, student explanations are judged by their semantic similarity to an instructor's or domain expert's explanation. Given recent advances in LLM-based automated scoring, it remains unclear whether semantic similarity methods are still the most effective technique to automatically score textual student responses like essays or code explanations. Comparing these methods also requires quality datasets that offer distinctive features such as balanced class distributions and domain-specific labeled data for automated scoring tasks. In this paper, we present a rigorous comparison between LLMs and semantic similarity used for automated scoring, framed as a binary classification task.
Retrieval-Augmented Tutoring for Algorithm Tracing and Problem-Solving in AI Education
May 13, 2026Students learning algorithms often need support as they interpret traces, debug reasoning errors, and apply procedures across unfamiliar problem instances. In this paper, we present KITE (Knowledge-Informed Tutoring Engine), a Retrieval-Augmented Generation (RAG)-based intelligent tutoring system designed to serve as a classroom teaching assistant for algorithmic reasoning and problem-solving tasks. KITE uses an intent-aware Socratic response strategy to tailor support to different student needs, responding with targeted hints, guiding questions, and progressive scaffolding intended to strengthen students' algorithmic problem-solving ability. To keep responses aligned with course content, KITE uses a multimodal RAG pipeline that retrieves relevant information from course materials. We evaluate KITE using three forms of assessment: RAGAs-based metrics for response grounding and quality, expert evaluation of pedagogical quality, and a simulated student pipeline in which a weaker language model interacts with KITE across two-turn dialogues and produces revised answers after receiving feedback. Results indicate that KITE produces contextually grounded and pedagogically appropriate responses. Further, using simulated students, KITE's feedback helped the student models produce more accurate follow-up responses on procedural and tracing questions, suggesting that its scaffolding can support algorithmic problem-solving. This work contributes a tutoring architecture and an evaluation approach for assessing retrieval-grounded explanations and scaffolded problem-solving feedback.
The Missing Evaluation Axis: What 10,000 Student Submissions Reveal About AI Tutor Effectiveness
May 07, 2026Current Artificial Intelligence (AI)-based tutoring systems (AI tutors) are primarily evaluated based on the pedagogical quality of their feedback messages. While important, pedagogy alone is insufficient because it ignores a critical question: what do students actually do with the feedback they receive? We argue that AI tutor evaluation should be extended with a behavioral dimension grounded in student interaction data, which complements pedagogical assessment. We propose an evaluation framework and apply it to 10,235 code submissions with corresponding AI tutor feedback from an introductory undergraduate programming course to measure whether students act on tutor feedback and whether those actions are applied correctly. Using this framework to compare two deployed AI tutors across different semesters in a large-scale introductory computer science course reveals substantial differences in student engagement patterns that are not captured by pedagogy-only evaluation. Moreover, these engagement-based behavioral signals are more strongly associated with student perception of helpful feedback than pedagogical quality alone, providing a more complete and actionable picture of AI tutor performance.
Personalized Worked Example Generation from Student Code Submissions using Pattern-based Knowledge Components
Apr 27, 2026Adaptive programming practice often relies on fixed libraries of worked examples and practice problems, which require substantial authoring effort and may not correspond well to the logical errors and partial solutions students produce while writing code. As a result, students may receive learning content that does not directly address the concepts they are working to understand, while instructors must either invest additional effort in expanding content libraries or accept a coarse level of personalization. We present an approach for knowledge-component (KC) guided educational content generation using pattern-based KCs extracted from student code. Given a problem statement and student submissions, our pipeline extracts recurring structural KC patterns from students' code through AST-based analysis and uses them to condition a generative model. In this study, we apply this approach to worked example generation, and compare baseline and KC-conditioned outputs through expert evaluation. Results suggest that KC-conditioned generation improves topical focus and relevance to learners' underlying logical errors, providing evidence that KC-based steering of generative models can support personalized learning at scale.
Skill-based Explanations for Serendipitous Course Recommendation
Aug 27, 2025Academic choice is crucial in U.S. undergraduate education, allowing students significant freedom in course selection. However, navigating the complex academic environment is challenging due to limited information, guidance, and an overwhelming number of choices, compounded by time restrictions and the high demand for popular courses. Although career counselors exist, their numbers are insufficient, and course recommendation systems, though personalized, often lack insight into student perceptions and explanations to assess course relevance. In this paper, a deep learning-based concept extraction model is developed to efficiently extract relevant concepts from course descriptions to improve the recommendation process. Using this model, the study examines the effects of skill-based explanations within a serendipitous recommendation framework, tested through the AskOski system at the University of California, Berkeley. The findings indicate that these explanations not only increase user interest, particularly in courses with high unexpectedness, but also bolster decision-making confidence. This underscores the importance of integrating skill-related data and explanations into educational recommendation systems.
Use Random Selection for Now: Investigation of Few-Shot Selection Strategies in LLM-based Text Augmentation for Classification
Oct 14, 2024



The generative large language models (LLMs) are increasingly used for data augmentation tasks, where text samples are paraphrased (or generated anew) and then used for classifier fine-tuning. Existing works on augmentation leverage the few-shot scenarios, where samples are given to LLMs as part of prompts, leading to better augmentations. Yet, the samples are mostly selected randomly and a comprehensive overview of the effects of other (more ``informed'') sample selection strategies is lacking. In this work, we compare sample selection strategies existing in few-shot learning literature and investigate their effects in LLM-based textual augmentation. We evaluate this on in-distribution and out-of-distribution classifier performance. Results indicate, that while some ``informed'' selection strategies increase the performance of models, especially for out-of-distribution data, it happens only seldom and with marginal performance increases. Unless further advances are made, a default of random sample selection remains a good option for augmentation practitioners.
LLMs vs Established Text Augmentation Techniques for Classification: When do the Benefits Outweight the Costs?
Aug 29, 2024The generative large language models (LLMs) are increasingly being used for data augmentation tasks, where text samples are LLM-paraphrased and then used for classifier fine-tuning. However, a research that would confirm a clear cost-benefit advantage of LLMs over more established augmentation methods is largely missing. To study if (and when) is the LLM-based augmentation advantageous, we compared the effects of recent LLM augmentation methods with established ones on 6 datasets, 3 classifiers and 2 fine-tuning methods. We also varied the number of seeds and collected samples to better explore the downstream model accuracy space. Finally, we performed a cost-benefit analysis and show that LLM-based methods are worthy of deployment only when very small number of seeds is used. Moreover, in many cases, established methods lead to similar or better model accuracies.
Human-AI Co-Creation of Worked Examples for Programming Classes
Feb 29, 2024Worked examples (solutions to typical programming problems presented as a source code in a certain language and are used to explain the topics from a programming class) are among the most popular types of learning content in programming classes. Most approaches and tools for presenting these examples to students are based on line-by-line explanations of the example code. However, instructors rarely have time to provide line-by-line explanations for a large number of examples typically used in a programming class. In this paper, we explore and assess a human-AI collaboration approach to authoring worked examples for Java programming. We introduce an authoring system for creating Java worked examples that generates a starting version of code explanations and presents it to the instructor to edit if necessary.We also present a study that assesses the quality of explanations created with this approach
Effects of diversity incentives on sample diversity and downstream model performance in LLM-based text augmentation
Jan 12, 2024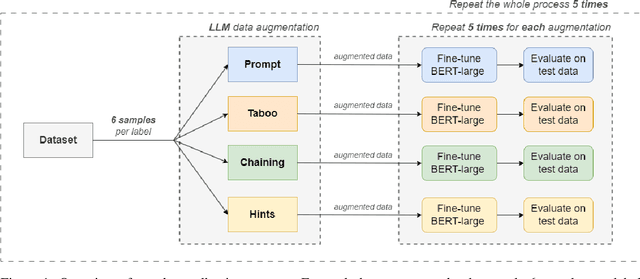
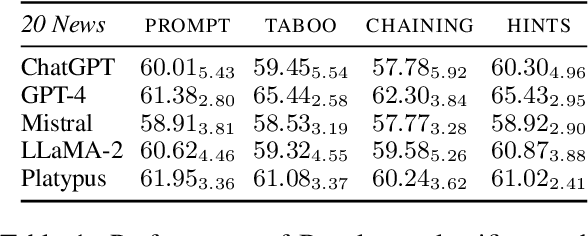
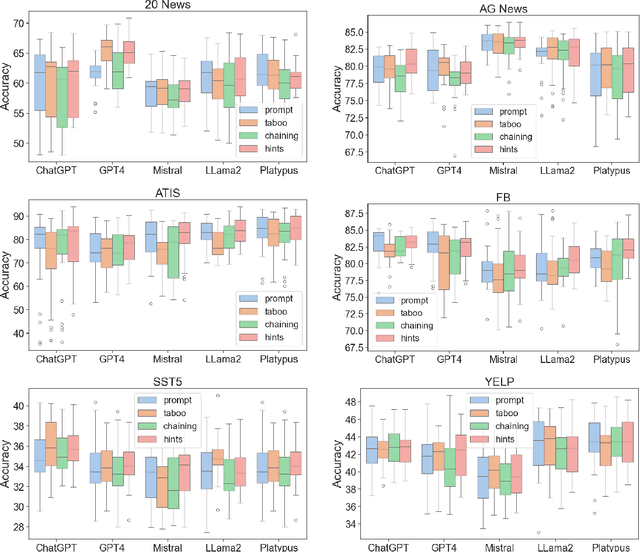
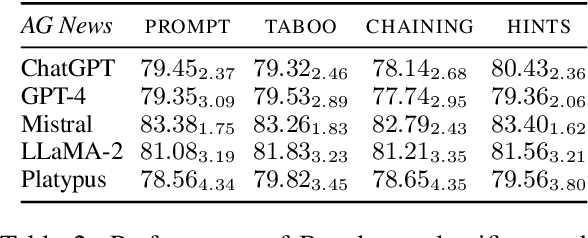
The latest generative large language models (LLMs) have found their application in data augmentation tasks, where small numbers of text samples are LLM-paraphrased and then used to fine-tune the model. However, more research is needed to assess how different prompts, seed data selection strategies, filtering methods, or model settings affect the quality of paraphrased data (and downstream models). In this study, we investigate three text diversity incentive methods well established in crowdsourcing: taboo words, hints by previous outlier solutions, and chaining on previous outlier solutions. Using these incentive methods as part of instructions to LLMs augmenting text datasets, we measure their effects on generated texts' lexical diversity and downstream model performance. We compare the effects over 5 different LLMs and 6 datasets. We show that diversity is most increased by taboo words, while downstream model performance is highest when previously created paraphrases are used as hints.
Authoring Worked Examples for Java Programming with Human-AI Collaboration
Dec 04, 2023Worked examples (solutions to typical programming problems presented as a source code in a certain language and are used to explain the topics from a programming class) are among the most popular types of learning content in programming classes. Most approaches and tools for presenting these examples to students are based on line-by-line explanations of the example code. However, instructors rarely have time to provide line-by-line explanations for a large number of examples typically used in a programming class. In this paper, we explore and assess a human-AI collaboration approach to authoring worked examples for Java programming. We introduce an authoring system for creating Java worked examples that generates a starting version of code explanations and presents it to the instructor to edit if necessary. We also present a study that assesses the quality of explanations created with this approach.