 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiCW: A Large-Scale Balanced Benchmark Dataset for Training Robust Check-Worthiness Detection Models
Feb 18, 2026Large Language Models (LLMs) are beginning to reshape how media professionals verify information, yet automated support for detecting check-worthy claims a key step in the fact-checking process remains limited. We introduce the Multi-Check-Worthy (MultiCW) dataset, a balanced multilingual benchmark for check-worthy claim detection spanning 16 languages, 7 topical domains, and 2 writing styles. It consists of 123,722 samples, evenly distributed between noisy (informal) and structured (formal) texts, with balanced representation of check-worthy and non-check-worthy classes across all languages. To probe robustness, we also introduce an equally balanced out-of-distribution evaluation set of 27,761 samples in 4 additional languages. To provide baselines, we benchmark 3 common fine-tuned multilingual transformers against a diverse set of 15 commercial and open LLMs under zero-shot settings. Our findings show that fine-tuned models consistently outperform zero-shot LLMs on claim classification and show strong out-of-distribution generalization across languages, domains, and styles. MultiCW provides a rigorous multilingual resource for advancing automated fact-checking and enables systematic comparisons between fine-tuned models and cutting-edge LLMs on the check-worthy claim detection task.
Revisiting Prompt Sensitivity in Large Language Models for Text Classification: The Role of Prompt Underspecification
Feb 04, 2026Large language models (LLMs) are widely used as zero-shot and few-shot classifiers, where task behaviour is largely controlled through prompting. A growing number of works have observed that LLMs are sensitive to prompt variations, with small changes leading to large changes in performance. However, in many cases, the investigation of sensitivity is performed using underspecified prompts that provide minimal task instructions and weakly constrain the model's output space. In this work, we argue that a significant portion of the observed prompt sensitivity can be attributed to prompt underspecification. We systematically study and compare the sensitivity of underspecified prompts and prompts that provide specific instructions. Utilising performance analysis, logit analysis, and linear probing, we find that underspecified prompts exhibit higher performance variance and lower logit values for relevant tokens, while instruction-prompts suffer less from such problems. However, linear probing analysis suggests that the effects of prompt underspecification have only a marginal impact on the internal LLM representations, instead emerging in the final layers. Overall, our findings highlight the need for more rigour when investigating and mitigating prompt sensitivity.
Better as Generators Than Classifiers: Leveraging LLMs and Synthetic Data for Low-Resource Multilingual Classification
Jan 22, 2026Large Language Models (LLMs) have demonstrated remarkable multilingual capabilities, making them promising tools in both high- and low-resource languages. One particularly valuable use case is generating synthetic samples that can be used to train smaller models in low-resource scenarios where human-labelled data is scarce. In this work, we investigate whether these synthetic data generation capabilities can serve as a form of distillation, producing smaller models that perform on par with or even better than massive LLMs across languages and tasks. To this end, we use a state-of-the-art multilingual LLM to generate synthetic datasets covering 11 languages and 4 classification tasks. These datasets are then used to train smaller models via fine-tuning or instruction tuning, or as synthetic in-context examples for compact LLMs. Our experiments show that even small amounts of synthetic data enable smaller models to outperform the large generator itself, particularly in low-resource languages. Overall, the results suggest that LLMs are best utilised as generators (teachers) rather than classifiers, producing data that empowers smaller and more efficient multilingual models.
A Rigorous Evaluation of LLM Data Generation Strategies for Low-Resource Languages
Jun 13, 2025Large Language Models (LLMs) are increasingly used to generate synthetic textual data for training smaller specialized models. However, a comparison of various generation strategies for low-resource language settings is lacking. While various prompting strategies have been proposed, such as demonstrations, label-based summaries, and self-revision, their comparative effectiveness remains unclear, especially for low-resource languages. In this paper, we systematically evaluate the performance of these generation strategies and their combinations across 11 typologically diverse languages, including several extremely low-resource ones. Using three NLP tasks and four open-source LLMs, we assess downstream model performance on generated versus gold-standard data. Our results show that strategic combinations of generation methods, particularly target-language demonstrations with LLM-based revisions, yield strong performance, narrowing the gap with real data to as little as 5% in some settings. We also find that smart prompting techniques can reduce the advantage of larger LLMs, highlighting efficient generation strategies for synthetic data generation in low-resource scenarios with smaller models.
Use Random Selection for Now: Investigation of Few-Shot Selection Strategies in LLM-based Text Augmentation for Classification
Oct 14, 2024



The generative large language models (LLMs) are increasingly used for data augmentation tasks, where text samples are paraphrased (or generated anew) and then used for classifier fine-tuning. Existing works on augmentation leverage the few-shot scenarios, where samples are given to LLMs as part of prompts, leading to better augmentations. Yet, the samples are mostly selected randomly and a comprehensive overview of the effects of other (more ``informed'') sample selection strategies is lacking. In this work, we compare sample selection strategies existing in few-shot learning literature and investigate their effects in LLM-based textual augmentation. We evaluate this on in-distribution and out-of-distribution classifier performance. Results indicate, that while some ``informed'' selection strategies increase the performance of models, especially for out-of-distribution data, it happens only seldom and with marginal performance increases. Unless further advances are made, a default of random sample selection remains a good option for augmentation practitioners.
LLMs vs Established Text Augmentation Techniques for Classification: When do the Benefits Outweight the Costs?
Aug 29, 2024The generative large language models (LLMs) are increasingly being used for data augmentation tasks, where text samples are LLM-paraphrased and then used for classifier fine-tuning. However, a research that would confirm a clear cost-benefit advantage of LLMs over more established augmentation methods is largely missing. To study if (and when) is the LLM-based augmentation advantageous, we compared the effects of recent LLM augmentation methods with established ones on 6 datasets, 3 classifiers and 2 fine-tuning methods. We also varied the number of seeds and collected samples to better explore the downstream model accuracy space. Finally, we performed a cost-benefit analysis and show that LLM-based methods are worthy of deployment only when very small number of seeds is used. Moreover, in many cases, established methods lead to similar or better model accuracies.
Fighting Randomness with Randomness: Mitigating Optimisation Instability of Fine-Tuning using Delayed Ensemble and Noisy Interpolation
Jun 18, 2024While fine-tuning of pre-trained language models generally helps to overcome the lack of labelled training samples, it also displays model performance instability. This instability mainly originates from randomness in initialisation or data shuffling. To address this, researchers either modify the training process or augment the available samples, which typically results in increased computational costs. We propose a new mitigation strategy, called Delayed Ensemble with Noisy Interpolation (DENI), that leverages the strengths of ensembling, noise regularisation and model interpolation, while retaining computational efficiency. We compare DENI with 9 representative mitigation strategies across 3 models, 4 tuning strategies and 7 text classification datasets. We show that: 1) DENI outperforms the best performing mitigation strategy (Ensemble), while using only a fraction of its cost; 2) the mitigation strategies are beneficial for parameter-efficient fine-tuning (PEFT) methods, outperforming full fine-tuning in specific cases; and 3) combining DENI with data augmentation often leads to even more effective instability mitigation.
Effects of diversity incentives on sample diversity and downstream model performance in LLM-based text augmentation
Jan 12, 2024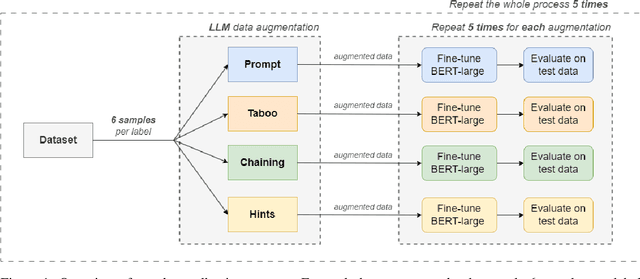
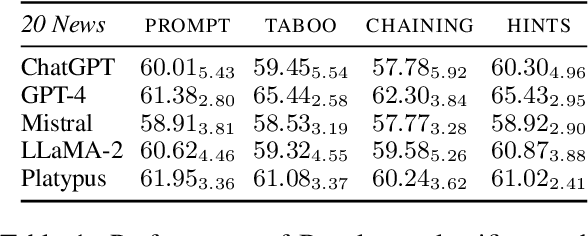
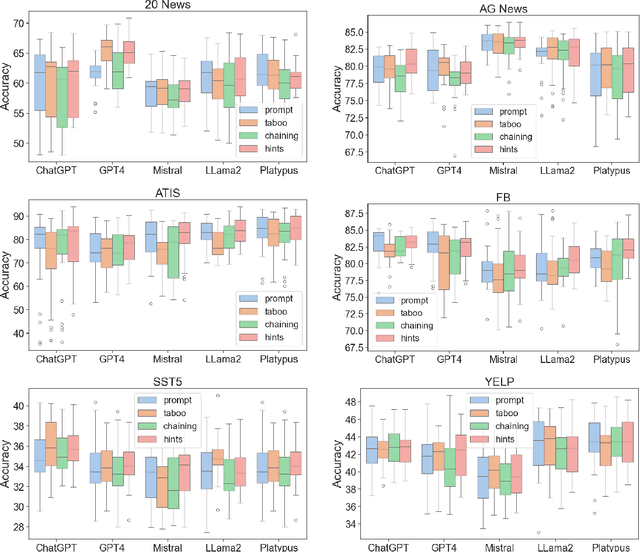
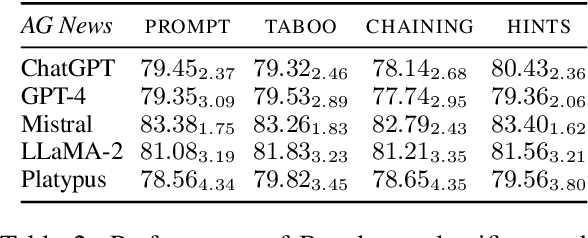
The latest generative large language models (LLMs) have found their application in data augmentation tasks, where small numbers of text samples are LLM-paraphrased and then used to fine-tune the model. However, more research is needed to assess how different prompts, seed data selection strategies, filtering methods, or model settings affect the quality of paraphrased data (and downstream models). In this study, we investigate three text diversity incentive methods well established in crowdsourcing: taboo words, hints by previous outlier solutions, and chaining on previous outlier solutions. Using these incentive methods as part of instructions to LLMs augmenting text datasets, we measure their effects on generated texts' lexical diversity and downstream model performance. We compare the effects over 5 different LLMs and 6 datasets. We show that diversity is most increased by taboo words, while downstream model performance is highest when previously created paraphrases are used as hints.
ChatGPT to Replace Crowdsourcing of Paraphrases for Intent Classification: Higher Diversity and Comparable Model Robustness
May 22, 2023



The emergence of generative large language models (LLMs) raises the question: what will be its impact on crowdsourcing. Traditionally, crowdsourcing has been used for acquiring solutions to a wide variety of human-intelligence tasks, including ones involving text generation, manipulation or evaluation. For some of these tasks, models like ChatGPT can potentially substitute human workers. In this study, we investigate, whether this is the case for the task of paraphrase generation for intent classification. We quasi-replicated the data collection methodology of an existing crowdsourcing study (similar scale, prompts and seed data) using ChatGPT. We show that ChatGPT-created paraphrases are more diverse and lead to more robust models.